
Notion 编辑器原理分析
作者:国勇
来源:https://zhuanlan.zhihu.com/p/359122473
notion 是我一直用的日常知识管理工具,让我生活与工作的所的资料汇聚在一起。他的使用体验非常棒,各种快捷键可丢掉鼠标行云流水式的进行文字编辑,block 之间随意拖动与组装;无限级的 page 能力,可一直延深整理自己的知识;database 数据管理能力加多种视图展示满足各种对数据的整理需求和日常任务管理
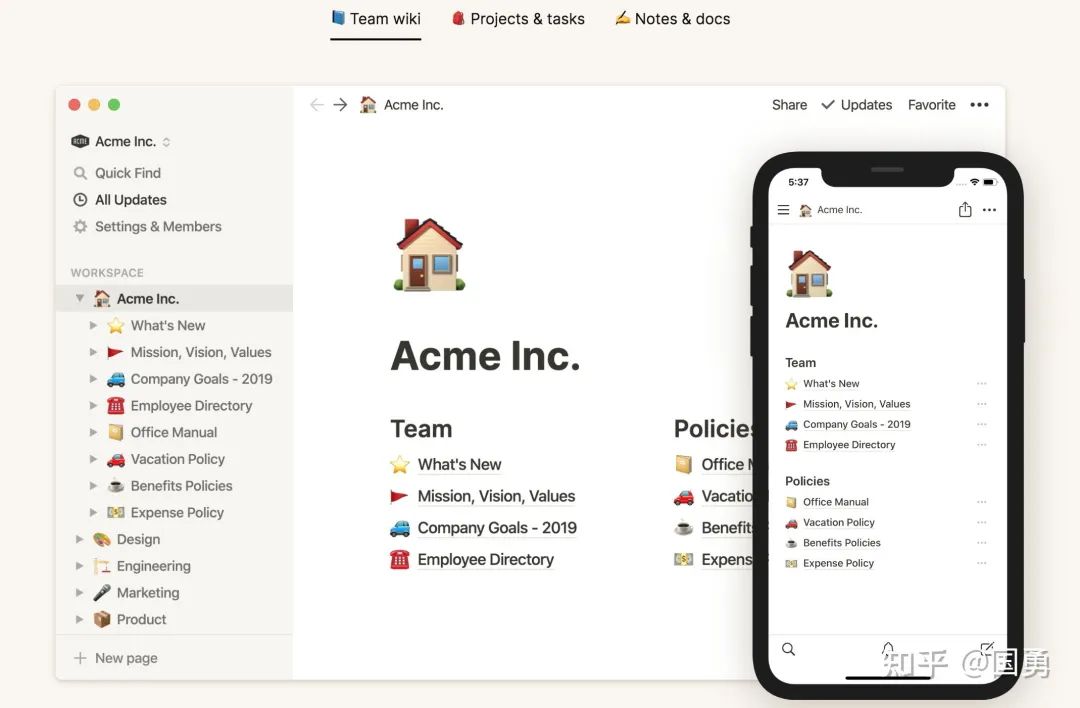
一款如此好的笔记工具,不得不让我了解他的技术原理,接下来讲一讲。
先了解怎么设计一款编辑器,做下铺垫,参考 facebook draft-js 的介绍视频 (Draft.js was introduced at React.js Conf in February 2016.),文章讲了做一款编辑器为什么不直接使用 contenteditable,但又不能完全抛弃 contenteditable 的原因。
文章所指的主要原因是 contenteditable 中 DOM = State ,这里的 State 指存储用户输入的内容,为 html 格式;从用户操作发起到数据修改整个过程都由浏览器控制,但是各浏览器存在实现差异,造成 State 的结果不一致,兼容性问题多。contenteditable 又有很多原生能力,速度快且支持所有的浏览器、如光标与选区、输入法事件等;ipad 下 contenteditable 也提供较多有意思的能力,如左右分栏时可直接从其它应用拖动文字到 contenteditable 中。最终 draft-js 通过自定义 State,抛弃掉原生提供的 html 形式的 State,通过 contenteditable 提供的能力负责文字排版与用户事件接收,定义一套 op(Operation) 来修改 State ,同时把数据模型通过 react 渲染到 html 中,达到 controlled contenteditable。
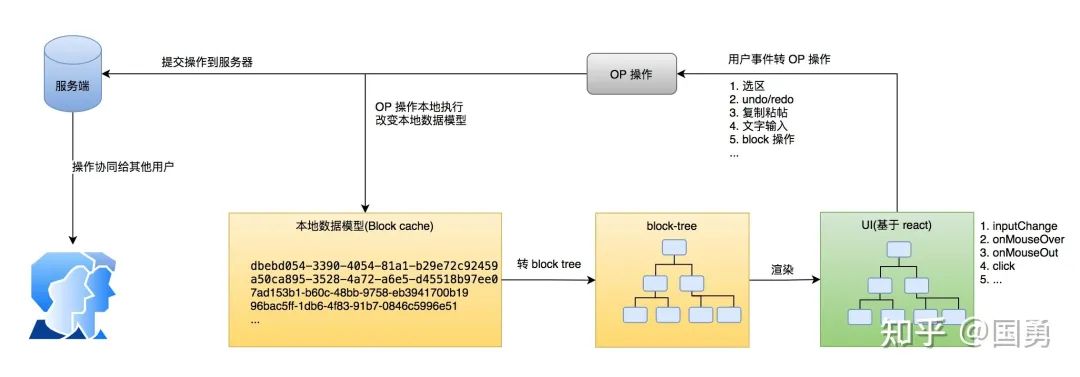
notion 也自定义数据层,设计了基于 Block-tree 的数据模型;渲染层用 React 把数据渲染成 html;使用 React 提供的事件(onInput\onCopy\onCut)或者工具条接收用户的操作指令,用户指令转换成 op;操作经过执行并修改数据模型 ,op 也会实时提交到服务端中改变后端数据库中的数据;服务端通过协同把 op 传给其他用户,达到一起编辑同一篇文章目的。
所以整个 notion 可以分两层,数据层专门负责存储数据;渲染层负责把数据渲染成界面,接收用户的事件并转化成 op 操作交给数据层执行。接下来分别介绍。
数据层
在 notion 里一切都为 block,表格、图片、文字段落等,block 通过 parent_id 来指向父 block,以此表达层级,如文章下有段落、表格、表格下有行、分栏下又可以圈套表格等。通过这种层级关系,就形成一棵 block-tree。一个 block 最基本的几个属性为:
1. properties: 属性值,如段落中用户输入的文字
2. parent_id: 指向父 block id,形成 block tree
3. type: block 的类型,如表格、行、列、图片、段落等
4. version:版本,用于协同

上图为 notion 的一篇两栏的文章,左栏为标题加一个表格;右栏为四行文字.
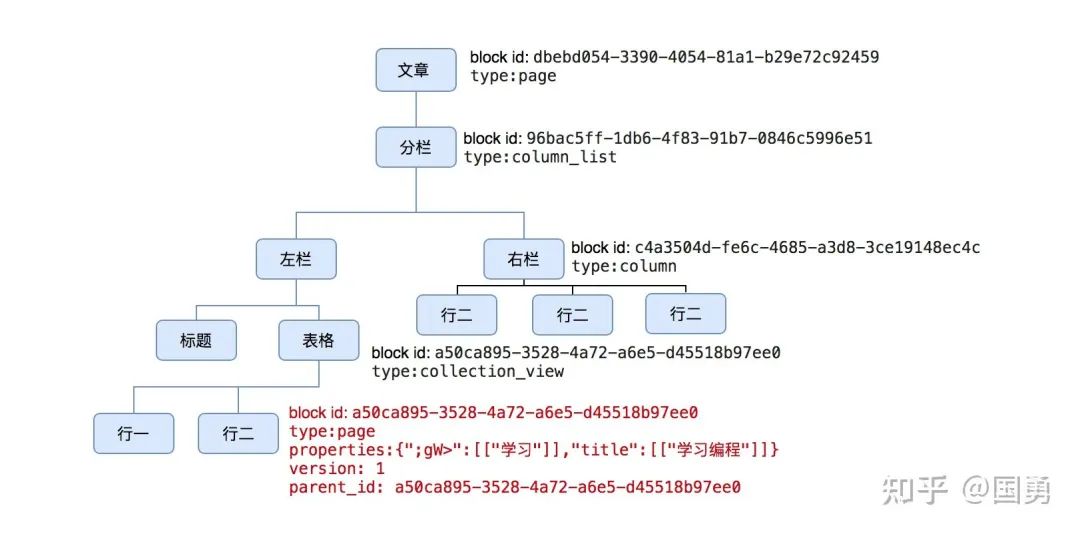
图为了简约,只把部份节点的部份值标识出来
这棵 block tree 为上篇文章的存储格式,每个 block 都有 block id、type、properties、version 等几个基本字段。红色为表格下的行存储,行的每列值是存储在 properties 中,属性 key 为列名,属性值为列的值,version 标识当前的版本号。
这会让一个前端同学马上把 block tree 和 dom tree 对比,block 和 dom 节点对比,反过来想,dom tree 可以表达所有的用户界面,理论上来说 block tree 也能完成大部份编辑器的需求,所以 notion 可以提供很多丰富的功能 。
在 notion 中没特别有 「文章」的概念,可以把任何一个 block id 组合在 url 上,notion 会把此 block id 下的所有子孙 block 又重新组合成一篇文章。比如:notion.so/c4a3504dfe6c4。

也会根据 block id 一直往上找到空间,把这些 block 的 title 取出来形成面包屑。
这是 notion 魔力的地方,他就像「乐高积木」一样,每块积木功能不同,可以搭建出不同的形状。在 notion 中每个 block 都和积木一样,block 的能力也不同,但可以组合成不同的解决方案,你可以在 notion 中提供的模板看出有不同需求的解决方案。
op
有了数据模型后,接下来是需要对这棵数据模型进行修改,在 dom api 里,浏览器提供了节点的删除、增加、修改(属性)、移动等功能 。在 notion 里也一样,数据层通过提供 op 的方式给到渲染层来修改数据,常规对树的操作可以有两类:
节点位置移动、增加、删除
节点属性修改
下面举几个在 notion 中的 demo:
修改属性

右图为修改左图上的图标产生的一次 set(修改) 操作,pointer 表示操作的 block id,args 为对这个 block 做 set 操作所需要的参数。
插入一个 block

插入一个 block 也是走的 set 命令,其中 args 里面会说明版本号(version)为1,同时当前节点为文本(text)节点。
但插入 block 还会有一个操作,记录是插在哪个 block 的后面。
通过这两个原子操作的组合就完成了一次插入 block 操作。
Transaction 操作组合
上面的「插入 block」就是两个原子操作组合完成的,通过这种原子操作的组合可以完成更多的用户操作。
Transaction 不仅修改本地内存数据,也会提交到服务器执行,如用户操作过程中,在本地与远端数据库中都维护着一棵 block-Tree,操作在本地做完后, notion 会自动发送到服务器,服务器也要执行并更新自己的数据模型,从而达到本地与服务端数据一致。
总结
数据存储基于 tree,称为 block-tree,类似于 dom-tree
定义一套 op 来表达修改数据意图,通过执行 op 来修改 block-tree
表现层
前台数据模型建立
在打开一篇文档时会通过 blockId 去服务端拿到前 50 个子 block ,本地把这 50 个 block 缓存到内存中。
此时服务端传回的和存在本地 store 的 block 并没有树形概念,而扁平化存储在 map 中,block id 为 key,block 值为 value;树形的构建是在渲染期建立,通过 block id,去 map 中找出所有的子节点递归渲染。从最顶上文章 block id 开始,一直递归到叶子节点。边构建树的过程中边渲染。
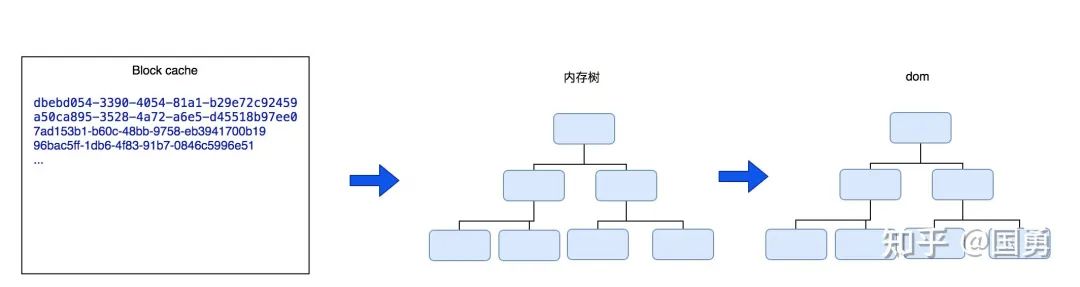
表现层的渲染大致流程为,第一步从服务端取出当前页的子 block 存放在 block cache 内存中,第二步从最顶上的 block 依次递归到叶子节点进行渲染。
Block 渲染的层级结构
基于块的编辑器有一个特点,块的行为是一致的,比如说块的移动、块选区等,只是块里面的内容不一样。一个 block 的渲染分为 block 包装组件,负责通用表现输出和行为的接收;而具体的组件内容渲染如 block 内容组件完成。
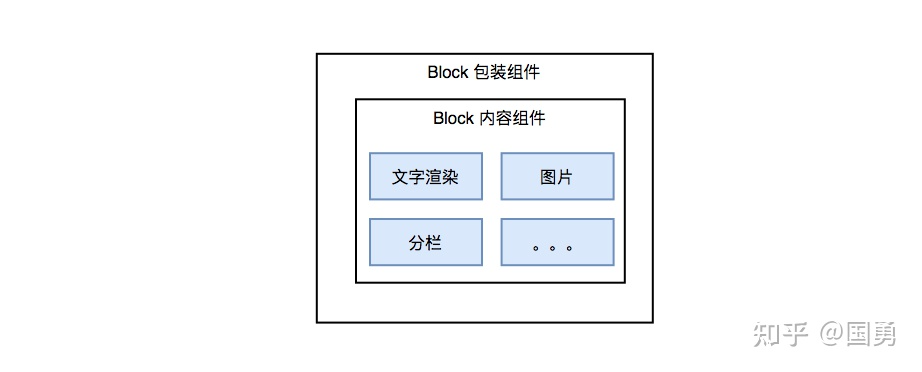
Block 包装组件的核心代码:
renderComponent()
{
const {isDragging: e, initiator: t, hasDragged: n, shouldShowDropParentHalo: o, shouldShowSelectionHalo: i, currentDropZone: s, dropZoneHint: a, dropZoneHintIndex: l, shouldRenderSelectionHalo: c, shouldRenderDropParentHalo: d, shouldRenderDropZoneHint: u, shouldRenderDropZone: p, propStoreType: h} = this.computedStore.state,
m = c || d || u || p,
g = "".concat(x.sb, " notion-").concat(h, "-block");
return this.renderDraggable(h => r.createElement("div", Object.assign({
style: this.getStyle({isPositionRelative: m,isDragging: e,hasDragged: n,initiator: t}),
"data-block-id": this.props.store.id,
className: this.props.className ? "".concat(g, " ").concat(this.props.className) : g
}, Object(f.a)(h || {}, {
onDoubleClick: this.handleDoubleClick,
onContextMenu: this.handleContextMenu,
onMouseOver: this.handleMouseOver,
onMouseOut: this.handleMouseOut,
onClick: this.handleClick,
onMouseMove: this.props.onMouseMove,
onMouseDown: this.props.onMouseDown,
onMouseEnter: this.props.onMouseEnter,
onMouseLeave: this.props.onMouseLeave
})), this.props.children, c && this.renderSelectionHalo(i), d && this.renderDropParentHalo(o), u && this.renderDropZoneHint(a, l), p && this.renderCurrentDropZone(s)))
}
块的核心行为在这里都能看出来,renderSelectionHalo 渲染选区背景,renderDraggable 设置拖拽行为,也定义了一堆事情,如 mouse 、click 事件,来响应 block 的通用事件。
上面为各种 block 内容的 react 渲染组件,负责组件具体的渲染与行为,如 block type 为 text 则渲染成 contenteditable 的 div。
这种方式给系统提供了非常大的灵活性,看出 block 为什么这么丰富,他背后要加一个新的 block type 类型速度也是很快,写好 type 渲染器就能完成大部份工作。
大体渲染流程看完了,接下来看一下一个常规的编辑器他的通用行为是怎么完成的。分别有 选区、undo/redo、复制粘帖、文字输入。
选区

notion 有块选区和文字选区两种,块选区可以一次性选中多个 block ,不过只能同时选择同级的;而文字选区是 block type 为 text 的节点专属选区,text block 直接渲染成 contentedable ,选区也是 contenteditable 提供的,但是 contentedable 的存储数据 notion 接管了,后面会细说。接下来得点讲下块选择。
块的选择分 2 个步骤:
block 选择,当鼠标拖动时,根据当前的鼠标位置判断哪些 block 被选中
block 表现渲染,在 block 渲染时会判断是否已被选中,如在的话在为 block 增加背景颜色
block 选择
要知道哪些 block 被选中 notion 做了些事情,在 block 渲染时所有可选择的 block 都缓存起来,当需要使用的时候根据鼠标位置去遍历可快速得到用户选择了哪些 Block,这个缓存如下:

缓存 map 里记录了上图所示的 React 的渲染组件实例和 react 组件渲染出 dom 元素的位置,有 x、y 坐标、以及他的宽和高。
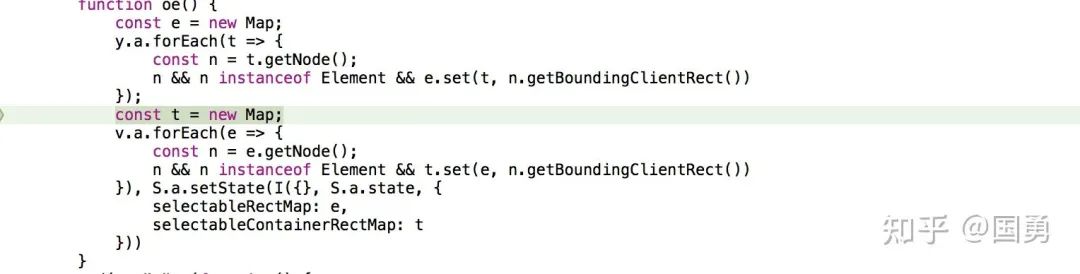
上面的代码就是 block 渲染时把组件实例和 dom 的位置信息记录在 selectableRectMap 中。

后期判断一个元素是否命中就只需要通过鼠标的 x、y 坐标去这个缓存对象里匹配就可。
同时被选中的 block 元素记录在 l.default.state.stores 中,并再次触发 react 重新渲染,每个组件都会通过 Block id 判断是否被选中了,当被选中则给 Block 的背景色补上,当然这里会有一个脏区处理,而不是把一整棵树都重新渲染。
Undo/Redo
上面讲过,针对数据层的修改叫做 op,而多个 op 组合在一起叫 Transation。要做 undo 时就简单了,undo/redo 本身就是一个记录栈,每次把操作往栈里放,当用户 ctrl+z 撤销操作时,则从栈顶取出一个操作,并找出反操作执行就可。
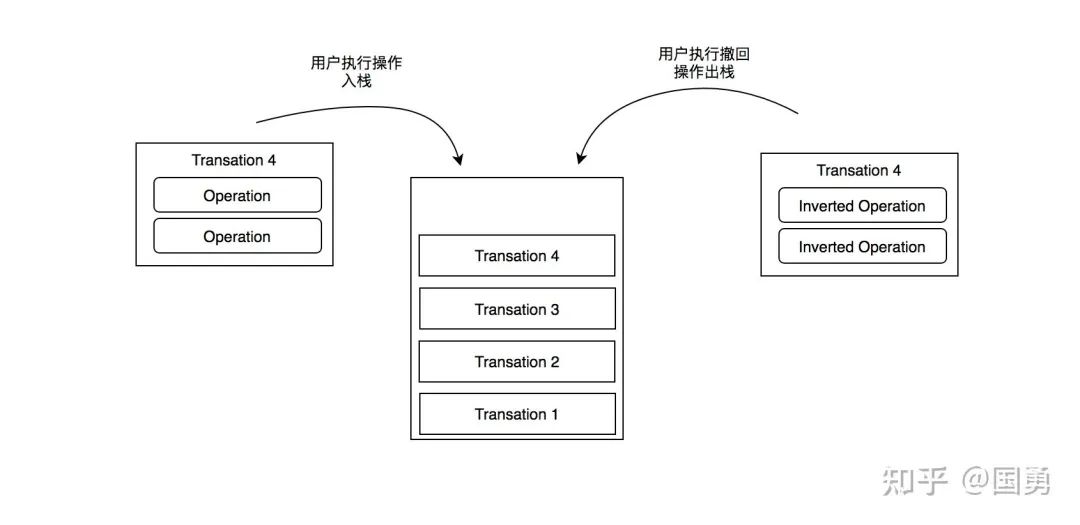
执行一次 op 的过程分成几步:
创建 Transation t 对象
把 op 添加到 t.operations 数组中
算出当前 op 的反操作,添加到 t.invertedOperations 数组中,供后续撤回使用
以下就是相关代码

不过这里怎么取 op 的反操作有意思,比如当用户输入完文字后,会把当前用户输入的值当成 set 操作的参数来执行修改数据模型的值 ,同时也会把当前内存中的 block text 算出一个反操作(因为此时数据模型中的值还没有更新),并记录起来。所以反操作是在生成操作时就算出来了,而不是等着用户触发撤回再算,因为执行操作前的状态就是执行完操作后再撤回的状态,这时算就有足够的信息。
如一个 block text 的原先值为 "hello",当用户输入了一个空格,则新的值为 "hello ",会得到以下两个操作:
操作:{pointer: {table: "block", id: "42c83ef1-fd06-422e-ad30-86992b97b1f5"}, path: ["properties", "title"], command: "set", args: [["hello "]]}
反操作:{pointer: {table: "block", id: "42c83ef1-fd06-422e-ad30-86992b97b1f5"}, path: ["properties", "title"], command: "set", args: [["hello"]]}
删除一个 block:
操作:{pointer: {table: "block", id: "4fcbd80b-09cd-4f44-b9a2-0cef1ba3145f"}, path: [], command: "update", args: {alive: false}}
反操作:{pointer: {table: "block", id: "4fcbd80b-09cd-4f44-b9a2-0cef1ba3145f"}, path: [], command: "update", args: {alive: true}}
在 notion 中的原子操作种类不多,取反操作也容易做。下面就是五种原子操作类型的取反操作的实现方法。
case "set":
return ((e, t) => ({ pointer: e.pointer, path: e.path, command: "set", args: g.h(t) ? null : t }))(e, n);
case "update":
return ((e, t) => { t || (t = {}); const n = {};
return Object.keys(e.args).forEach(e => {n[e] = t[e], void 0 === n[e] && (n[e] = null)}), {
pointer: e.pointer, path: e.path, command: "update", args: n }
})(e, n);
case "listBefore":
return function(e, t) {
const n = o.a.isArray(t) ? t : [], r = n.findIndex(t => t === e.args.id);
...
return { pointer: e.pointer, path: e.path, command: "listRemove", args: { id: e.args.id } }
}(e, n);
case "listAfter":
return function(e, t) {
const n = o.a.isArray(t) ? t : [],
r = n.findIndex(t => t === e.args.id);
...
return { pointer: e.pointer, path: e.path, command: "listRemove", args: { id: e.args.id } }
}(e, n);
case "listRemove":
return function(e, t) {
const n = o.a.isArray(t) ? t : [], r = n.findIndex(t => t === e.args.id), i = n[r - 1];
return i ? { pointer: e.pointer, path: e.path, command: "listAfter",
args: { id: e.args.id, after: i }
} : { pointer: e.pointer, path: e.path, command: "listBefore", args: { id: e.args.id } }
}(e, n);
在看下入栈的过程:
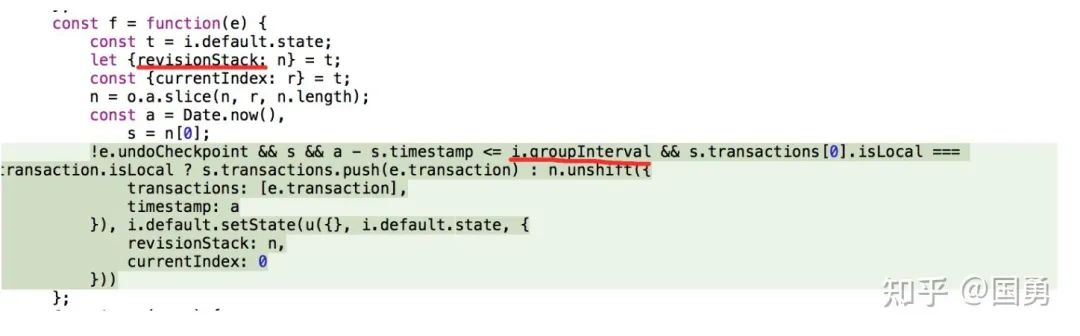
revisionStack 为堆栈记录数组变量,记录了用户操作的 transations,当然不是每次用户操作生成的 transation 都是直接往 revisionStack 里放,会有 700ms 的缓冲时间,在最后一个 transation 与新进来的 transation 如果是在 700ms 内,则会合并。如用户一个字符一个字符依次输入,我们再撤回时也是一个字符一个字符的删,这显然是不合理的,就像 contenteditable 一样,撤回时一次可删除多个字符,这个缓冲时间就是起这个作用的。
还有一个问题是用户不停的产生操作,堆栈要记录多少呢?会不会把内存搞爆,他的上限是多少?
看了一圈,是没有去处理的,而是一直往 revisionStack 里怼,直到内存爆啦为止,不过你也不会把他搞爆啦。
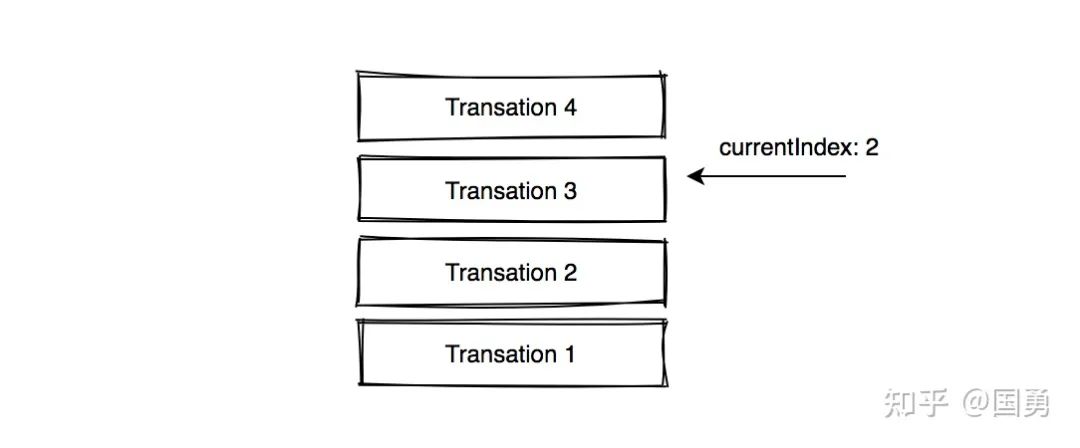
由于用户所有的操作是一直存放在 revisionStack 里的,而不会随着用户的撤销操作而移除, notion 定义了一个下标指针变量 currentIndex,表示下一次要撤回的操作下标,当每次撤回操作时只需要取出 revisionStack[currentIndex] 里的 invertedOperations 并执行,就达到了撤回效果。同时执行 redo 操作也只需要取出 revisionStack[currentIndex-1] 的操作,并取出 op 里的 operations 并执行就可以了。
文字操作
文字节点也是一个普通的 block,只是他承载的是文字输入与呈现,输出为 contenteditable div,就如 facebook draft 的视频中所说,需要一个 controlled contenteditable,contenteditable 负责文字呈现与用户事件的接收,接收到事件后再自己处理,如文字加粗、文字录入、文字颜色等,并最终生成 notion 的 op 来修改 block tree 上的 block 节点,这样做的好处就如 facebook draft 里提的复用了浏览器的文字排版渲染、选区等浏览器提供的功能,但接管了数据存储,达到数据完全可控。从而脱离 contenteditable 的数据层,达到 controlled contenteditable。
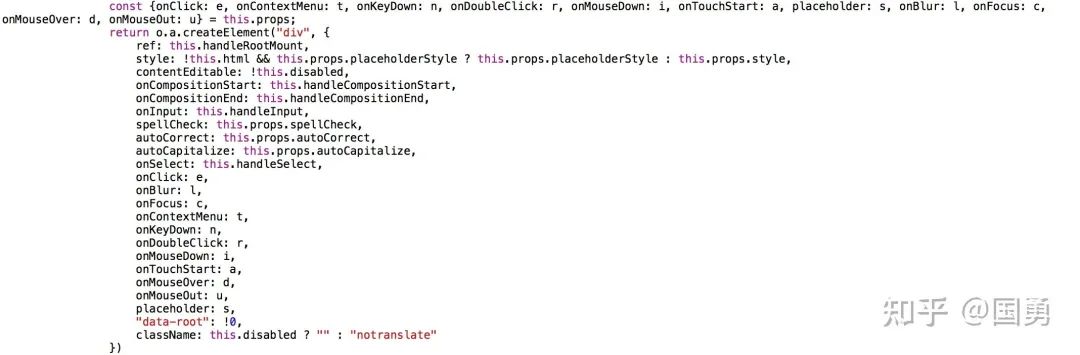
上图代码为文字 block 的渲染组件,onInput 用于接收用户的文字录入,onCompositionStart/onCompositionEnd 也会处理中文输入法的问题。

渲染组件将文字 block type 渲染成了如上 contenteditable div 节点
文字存储与渲染
一段文字会有某一区间加粗、颜色不同、等不同样式,先看下是怎么存储的。

上面一段话,被拆分成了多个文字区间,并最终存储在 block 里的 title 属性里,每个区间由文字加属性组成,文字中有加粗、下划线、颜色等不同属性,区间按文字的先后顺序形成了的数组,同时组合在一起就代表整句话,如上面「我说」通过 b 来描述他是粗体;「终将会让你的」区间有两个属性,通过 h 来标识颜色为 orange,通过 s 来代表文字有下划线。

有属性的区间会输出在一个 span 里,同时 b/h/s 这类属性描述会转换成 style 输出,从而就完成了不同样式的区间文字渲染。
文字操作
此类 block 除了把初始化的文字进行渲染,还会接收用户的文字录入与属性修改,并最终修改 block tree 上的数据,接下来先讲属性修改是怎么工作的,比如给一段文字进行加粗,主要分成如下3个步骤。
区间查找,根据 UI 映射到数组区间
区间修改,找到了数组区间后,把当前用户新加的属性加到区间中
区间重组,判断被修改的前后区间属性值是否一样,如一样则进行区间合并,避免太多零散区间造成存储大以及加大解析时间。
function Ee(e) {
const { environment: t, store: n, selection: r, annotation: a, transaction: s } = e, l = n.getValue();
if (l) {
// 第一步:区间查找
const e = a, c = i.F(e), { tokensInsideRange: d } = i.Nb(l, r.startIndex, r.endIndex);
// 第二步:新区间生成
let u; u = o.a.every(d, e => i.db(e).some(e => i.F(e) === c))
? d.map(e => { const t = i.fb(e), n = i.db(e).filter(e => i.F(e) !== c); return i.n(t, n) })
: d.map(t => { const n = i.fb(t), r = i.db(t).filter(e => i.F(e) !== c); return r.push(e), i.n(n, r) });
// 第三步:区间重组
const p = n.getValue(), h = i.p(p, r.startIndex, r.endIndex);
Me({ environment: t, store: n, value: i.nb(h, u, r.startIndex), transaction: s })
}
}
上面代码就完成了三步,分别标识出来了,接下来讲下更具体的。
选区
刚讲过文字选区是浏览器 contenteditable 提供的能力,用户鼠标选中区间后,通过浏览器提供的 window.getSelection() api 可以获取出用户选择了哪些文字。

左图选择了「渴望」,此时调用 window.getSelection() 会返回 selection 对象,Selection 的具体意思可参考,其中 anchorNode 代表开始 dom 节点,anchorOffset 为节点下文字的开始偏移量,focus开头代表结束 dom 节点与文字偏移位置。
区间查找
此时需要映射到文字存储区间,常规可能是把选区映射到文字数组下标,然后按文字下标从左往右找,效率低,查找复杂度为 o(n) 的。但这样显然不高效,上面渲染成 html 时,会在 span 节点带个 data-token-index 属性标识数据存储区间的数据下标位置。有了这个位置就好对应了,整个映射流程是
anchorNode 标识了 span,span 上的 data-token-index 对应的是数组区间的下标,anchorOffset 是文字的偏移位置,从而完美的完成了映射,达到了 o(1) 的查找速度。
然而搞笑的事,他并没有这样做。这个 data-token-index 是用于其它定位,而不是用于这里的区间查找,区间查找查找复杂度还是 o(n)。
他的做法是把文字选择的下标位置记下来,然后去数组区间循环遍历一个一个按 o(n) 的方式找。
const We = function(e, t, n) {
const r = we(e), o = [], a = [], s = [];
let l = 0;
for (const c of r) {
const e = G(c), r = le(c), d = i.a.toArray(e), u = l, p = l + d.length;
if (p <= t) o.push(c);
else if (u >= n) a.push(c);
else if (u >= t && p <= n) s.push(c); // 整个区间命中
else if (u <= t && p >= n) { // 右半区间命中
const e = t - u, i = e + n - t, l = d.slice(0, e), c = d.slice(e, i), p = d.slice(i);
l.length > 0 && o.push(_e(l.join(""), r)), p.length > 0 && a.push(_e(p.join(""), r)), c.length > 0 && s.push(_e(c.join(""), r))
} else if (u >= t && u < n) { // 左半区间命中
const e = n - u, t = d.slice(0, e), o = d.slice(e);
o.length > 0 && a.push(_e(o.join(""), r)), t.length > 0 && s.push(_e(t.join(""), r))
} else if (u < t && p > t) {
const e = t - u, n = d.slice(0, e), i = d.slice(e);
n.length > 0 && o.push(_e(n.join(""), r)), i.length > 0 && s.push(_e(i.join(""), r))
}
l = p
}
return { tokensBeforeRange: He(o), tokensInsideRange: He(s), tokensAfterRange: He(a) }
}
上面代码可以看出,每个区间都会和当前 ui 选区的文字下标进行匹配,进行区间命中判断,在区间内或命中整个区间则直接找到;如果是命中半个区间时,则会把原区间所有属性 + 所选区间的文字组合成新的选区。
当然区间存储还有较多可提高的,典型的是腾讯文档会通过「线段树」来存储数组的文字区间下标,文字与属性分离存储,线段树是基于「红黑树」,让查找可以在 o(log n) 来查找定位。
区间属性修改
接下来区间找到后,需要把用户的属性值加到新区间中,同之前的区间组合成新的区间数组,完成用户的操作。这步比较简单,比如找出的区间是 ["知识",[["_"]]],需要对他加粗,加粗标识为 b,则修改后变成了["知识",[["_"],["b"]]],当然如果你再次对「知识」按下一次加次,表现是取反,变成了不加粗。上面代码中第二步能看出。
区间重组
重组是为了把相邻区间属性值一样的区间进行合并,以免造成多余的区间,造成存储变大与解析时间增长等。
如 ["对",["_"]]、["知识",["_"]],两个属性一样,则会重组成["对知识",["_"]],上面代码中第三步能看出
文字输入
输入文字和属性无太大不同,找到对应的文字区间,并把文字增加到区间就可以了。
复制粘帖
复制粘帖是文字编辑器里面重要功能,特别对于「复制粘帖工程师」而言,最大的还原原有文字是验证能力的标准。
复制的工作是把选区里面的内容复制到剪切板里,上面讲过 notion 里有 block 选区和文字选区,文字选区的 copy 就直接用的是浏览器提供的,不需要 notion 做什么处理。如果复制的是 block 选区,就需要做两件事情:
拿到选区下选择的 block ,递归 block 转换成 javascript 对象
对象转换成 html 与 json 设置到剪切版中
设置 text/_notion-blocks-v2-production,用于 notion 内部粘帖使用,数据为 json 字符串
渲染成 text/plaint,供粘帖到外部使用
渲染成 text/html ,供粘帖到外部使用
// 递归选区的 block 转换成 javascript 对象
$t(t, a.map(t => ({
blockId: t, snapshotData: void 0,
// 子节点,注意这里是把子节点下的子孙节点会遍平存储在 blockSubtree 中
blockSubtree: bt.b(e, { blockId: t, inMemoryRecordCache: o,
allowCopyCollections: !1, requireFullSubtree: !0
})
})))
// 把 json 对象设置到剪切版自定义数据里
function $t(e, t) {
if (!e.clipboardData) return;
const n = t.map(e => Wt({}, e, { blockSubtree: e.blockSubtree ? e.blockSubtree.toJson() : void 0 }));
// 设置到剪切板的 text/_notion-blocks-v2-production key 里
e.clipboardData.setData(Jt, JSON.stringify(n))
}
上面代码为设置 text/_notion-blocks-v2-production 的过程,通过拿到选区的节点,再把节点的子孙 block 都设置到 blockSubtree 属性中。
复制成 text/plaint 与 text/html 相对复杂,先生成 markdown 格式,然后通过 markdown-it 转成 html,再分别设置到 text/plaint 与 text/html 。
// 1. 把选区的节点生成 markdown 格式
// 这里只会把选区 block 节点转换,block 的子节点需要在转换器里面迭代
return q(s.a.compact(e.map(e => z({ block: e, exportArgs: O({}, t, { blockId: e.id })
// 1.1 根据节点类型来找出每个节点转 markdown 的转换器
function z(e) {
const {block: t} = e;
if (t && t.type) {
// {text: function, header: function, sub_header: function, sub_sub_header: function, quote: function, …} = $20
// Y 变量里存放着每种 block type 对应的转换方法
const n = Y[t.type];
// 转换成 markdown 格式
if (n) return n(e) }
}
// 1.1.1 其中一个渲染器
// e 为 notion block
to_do: function(e) {
const {block: t, exportArgs: n} = e;
let r;
return r = p.n(Object(f.c)(t).checked) ? "- [x] " : "- [ ] ", {
// 生成 markdown 格式
text: "".concat(r, " ").concat(D({ block: t, exportArgs: n }).trim()),
breakLines: !1, indentChildren: !0,
// 再把子节点进行递归转换
children: L(e)
}
}
// 2. 通过 markdown-it 渲染成 html,变设置到剪切版的 text/html
const r = K(Wt({}, n, { markdown: p }));
t.clipboardData.setData("text/html", en(e.device.isWindows, r))
上图代码先把选区所先的 block 及子孙节点都分别转成 markdown 格式,每种 block type 都有对应用的 markdown 转换器进行转换,转换后再通过 markdown-it 生成 html ,最后把 html 设置到剪切板中。
粘帖
粘帖分为内部与外部两种数据来源,内部数据源是指在 notion 文章内的复制粘帖;外部数据源是指从其它系统,如网页、word 等工具。粘帖分成几步:
数据获取:获取剪切版里数据
解析数据:根据数据类型不一样,使用不同的数据解析器来解析数据
数据应用:把解析出来的数据生成 notion 的 op ,通过执行完这些 op ,达到修改数据的目的
内部数据源
内部数据源的数据来源来内部系统复制,所以数据源是自己规定的,获取与解析都简单。
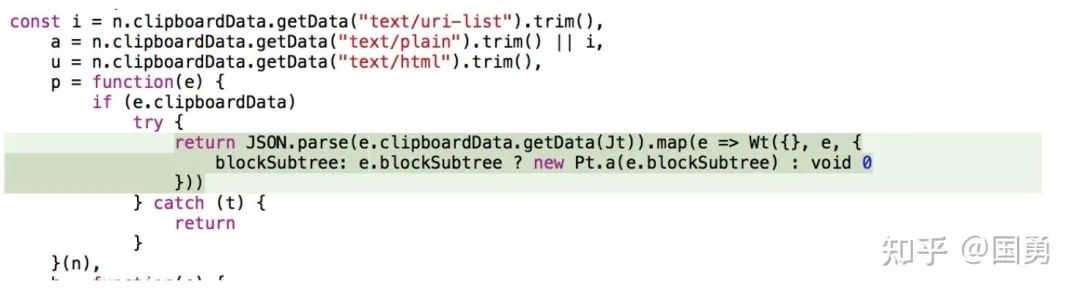
上面代码就是从剪切版里拿到内部复制时存到剪切版里的 json 数据,这里直接 json.parse 解析,解析完后把每个 block 都分别生成增加 block 的 op 执行就可以了。
外部数据源

外部复制分为两种来源,一种 office 与 非 office,非 office 是指网页等这类。
剪切版里的数据本来就有 html 格式的,html 会先渲染到离屏的 dom 对象中,notion 会分别递归迭代并解析这些 html 的节点,然后通过遍历这棵 dom tree,把 dom node 转成 notion block 节点的 op 操作。
if (a && a instanceof u.Element) {
const t = a.tagName.toLowerCase();
// html h1 标签
if ("h1" === t)
return [Ve({actor: n,parentId: r, parentTable: o, spaceId: i, node: a,...)];
// html h2 标签
if ("h2" === t)
return [Ve({actor: n,parentId: r, parentTable: o, spaceId: i, node: a,...)];
...
if ("details" === t)
return [Je({actor: n,parentId: r, parentTable: o, spaceId: i, node: a,...)];
// 表格
if ("table" === t) {
const e = [], t = Array.from(a.querySelectorAll("tr")).filter(e => e.closest("table") === a);
for (const n of t) {
const t = [], r = Array.from(n.querySelectorAll("td, th")).filter(e => e.closest("tr") === n);
for (const e of r) {
const n = (e.textContent || "").trim();
t.push({ text: n, textValue: Re({ node: e, window: u, stripText: !1 }) })
}
e.push(t)
}
return 0 === s.a.flattenDeep(e).length ? [] : [Ne({actor: n,parentId: r, parentTable: o, spaceId: i, node: a,...)];
}
// div
if ("div" === t && a.hasAttribute(_e[l.a.columnList]))
return [Qe({actor: n,parentId: r, parentTable: o, spaceId: i, node: a,...)];
上面就是每个 dom node 对 notion op 的解析流程,根据 node tag 类型有不同的 block 解析器。
function Ve(e) {
const {actor: t, parentId: n, parentTable: r, spaceId: o, node: i, type: a, allOperations: s, window: l, ignoreBlockCount: c, stripText: u, randomID: p} = e,
// 创建一个新的 block id
h = p(),
m = {id: h, version: 0, type: a,
// dom 节点的值当成 block title 属性
properties: { title: Re({ node: i, window: l, stripText: u }) },
parent_id: n, parent_table: r,
space_id: o, created_by_table: t.table, created_by_id: t.value.id, created_time: Date.now(), last_edited_by_table: t.table, last_edited_by_id: t.value.id, last_edited_time: Date.now(), alive: !0, ignore_block_count: !!c || void 0
};
// 给新的 block 设置值,生成新 op
return s.push({ pointer: { table: d.b, id: h, spaceId: o }, command: "set",path: [],args: m }), h
}
上面代码为其中一个 div 节点转 op 的过程,op 是创建一个 block,dom 里面的值会当成 block 的参数。
office 原理都一致,只是解析格式不一样,就不细看了。
总结
notion 在产品能力上很优秀,打破了传统的笔记软件固化思维,与其说提供给用户的是一套笔记工具,而不如说是一套设计笔记软件的系统。但通过 block 能力的增强,能力更多了,可以用来做日常工作管理,团队 wiki 等。
notion 整个软件架构的基建能力是把 block 的渲染、block 的存储、数据修改等都处理好,后期功能的增加可快速迭代,在基础上增加更多的 block 类型。
爱心三连击
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号脑洞前端,获取更多前端硬核文章!加个星标,不错过每一条成长的机会。
3.如果你觉得本文的内容对你有帮助,就帮我转发一下吧。