
Java8 中用法优雅的 Stream,性能也""优雅""吗?
作者:CarpenterLee
github.com/CarpenterLee/JavaLambdaInternals
我们已经学会如何使用Stream API,用起来真的很爽,但简洁的方法下面似乎隐藏着无尽的秘密,如此强大的API是如何实现的呢?
比如Pipeline是怎么执行的,每次方法调用都会导致一次迭代吗?自动并行又是怎么做到的,线程个数是多少?本节我们学习Stream流水线的原理,这是Stream实现的关键所在。
首先回顾一下容器执行Lambda表达式的方式,以ArrayList.forEach()方法为例,具体代码如下:
// ArrayList.forEach()
public void forEach(Consumersuper E> action) {
...
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);// 回调方法
}
...
}
我们看到ArrayList.forEach()方法的主要逻辑就是一个for循环,在该for循环里不断调用action.accept()回调方法完成对元素的遍历。
这完全没有什么新奇之处,回调方法在Java GUI的监听器中广泛使用。Lambda表达式的作用就是相当于一个回调方法,这很好理解。
Stream API中大量使用Lambda表达式作为回调方法,但这并不是关键。理解Stream我们更关心的是另外两个问题:流水线和自动并行。
使用Stream或许很容易写入如下形式的代码:
int longestStringLengthStartingWithA
= strings.stream()
.filter(s -> s.startsWith("A"))
.mapToInt(String::length)
.max();
上述代码求出以字母A开头的字符串的最大长度,一种直白的方式是为每一次函数调用都执一次迭代,这样做能够实现功能,但效率上肯定是无法接受的。
类库的实现着使用流水线(Pipeline)的方式巧妙的避免了多次迭代,其基本思想是在一次迭代中尽可能多的执行用户指定的操作。为讲解方便我们汇总了Stream的所有操作。
| Stream操作分类 | ||
| 中间操作(Intermediate operations) | 无状态(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有状态(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 结束操作(Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() | |
Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记,只有结束操作才会触发实际计算。中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果。
比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。
为了更好的理解流的中间操作和终端操作,可以通过下面的两段代码来看他们的执行过程。
IntStream.range(1, 10)
.peek(x -> System.out.print("\nA" + x))
.limit(3)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
输出为:
A1B1C1
A2B2C2
A3B3C3
中间操作是懒惰的,也就是中间操作不会对数据做任何操作,直到遇到了最终操作。而最终操作,都是比较热情的。他们会往前回溯所有的中间操作。也就是当执行到最后的forEach操作的时候,它会回溯到它的上一步中间操作,上一步中间操作,又会回溯到上上一步的中间操作,...,直到最初的第一步。
第一次forEach执行的时候,会回溯peek 操作,然后peek会回溯更上一步的limit操作,然后limit会回溯更上一步的peek操作,顶层没有操作了,开始自上向下开始执行,输出:A1B1C1 第二次forEach执行的时候,然后会回溯peek 操作,然后peek会回溯更上一步的limit操作,然后limit会回溯更上一步的peek操作,顶层没有操作了,开始自上向下开始执行,输出:A2B2C2
... 当第四次forEach执行的时候,然后会回溯peek 操作,然后peek会回溯更上一步的limit操作,到limit的时候,发现limit(3)这个job已经完成,这里就相当于循环里面的break操作,跳出来终止循环。
再来看第二段代码:
IntStream.range(1, 10)
.peek(x -> System.out.print("\nA" + x))
.skip(6)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
输出为:
A1
A2
A3
A4
A5
A6
A7B7C7
A8B8C8
A9B9C9
第一次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,因为执行到skip,这个操作的意思就是跳过,下面的都不要执行了,也就是就相当于循环里面的continue,结束本次循环。输出:A1
第二次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,发现这是第二次skip,结束本次循环。输出:A2
...
第七次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,发现这是第七次skip,已经大于6了,它已经执行完了skip(6)的job了。这次skip就直接跳过,继续执行下面的操作。输出:A7B7C7
...直到循环结束。
一种直白的实现方式
仍然考虑上述求最长字符串的程序,一种直白的流水线实现方式是为每一次函数调用都执一次迭代,并将处理中间结果放到某种数据结构中(比如数组,容器等)。
具体说来,就是调用filter()方法后立即执行,选出所有以A开头的字符串并放到一个列表list1中,之后让list1传递给mapToInt()方法并立即执行,生成的结果放到list2中,最后遍历list2找出最大的数字作为最终结果。程序的执行流程如如所示:
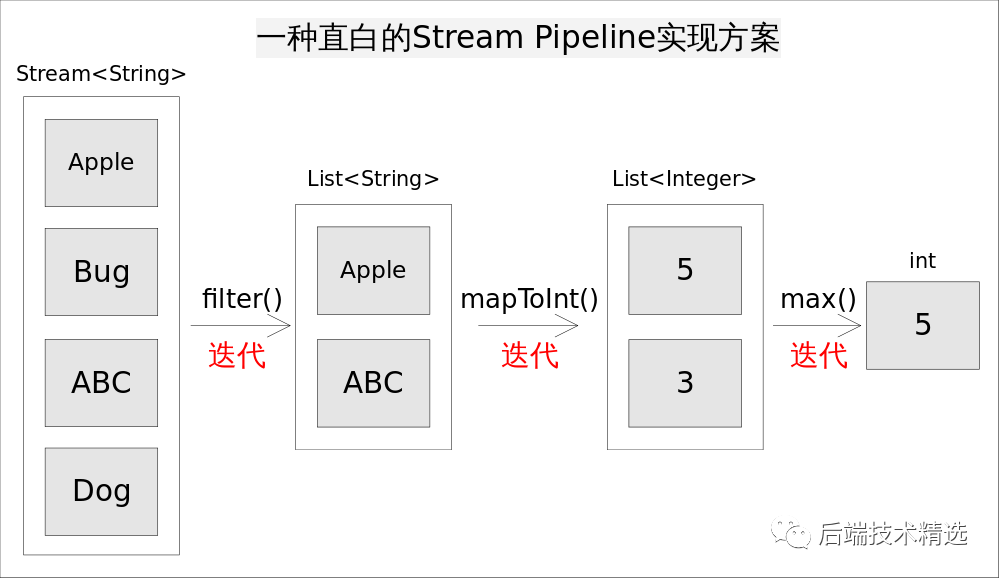
这样做实现起来非常简单直观,但有两个明显的弊端:
迭代次数多。迭代次数跟函数调用的次数相等。
频繁产生中间结果。每次函数调用都产生一次中间结果,存储开销无法接受。
这些弊端使得效率底下,根本无法接受。如果不使用Stream API我们都知道上述代码该如何在一次迭代中完成,大致是如下形式:
int longest = 0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以A开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
}
}
采用这种方式我们不但减少了迭代次数,也避免了存储中间结果,显然这就是流水线,因为我们把三个操作放在了一次迭代当中。只要我们事先知道用户意图,总是能够采用上述方式实现跟Stream API等价的功能,但问题是Stream类库的设计者并不知道用户的意图是什么。
如何在无法假设用户行为的前提下实现流水线,是类库的设计者要考虑的问题。
Stream流水线解决方案
我们大致能够想到,应该采用某种方式记录用户每一步的操作,当用户调用结束操作时将之前记录的操作叠加到一起在一次迭代中全部执行掉。沿着这个思路,有几个问题需要解决:
用户的操作如何记录?
操作如何叠加?
叠加之后的操作如何执行?
执行后的结果(如果有)在哪里?
>> 操作如何记录
注意这里使用的是“操作(operation)”一词,指的是“Stream中间操作”的操作,很多Stream操作会需要一个回调函数(Lambda表达式),因此一个完整的操作是<数据来源,操作,回调函数>构成的三元组。
Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的PipelineHelper来代表Stage,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。跟Stream相关类和接口的继承关系图示。
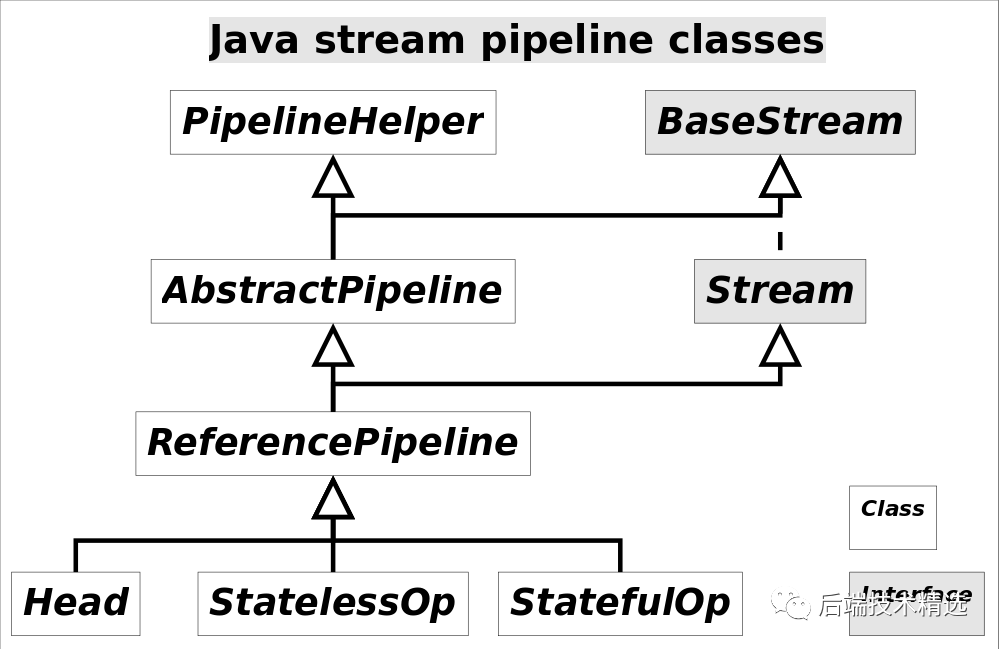
还有IntPipeline, LongPipeline, DoublePipeline没在图中画出,这三个类专门为三种基本类型(不是包装类型)而定制的,跟ReferencePipeline是并列关系。
图中Head用于表示第一个Stage,即调用调用诸如Collection.stream()方法产生的Stage,很显然这个Stage里不包含任何操作;StatelessOp和StatefulOp分别表示无状态和有状态的Stage,对应于无状态和有状态的中间操作。
Stream流水线组织结构示意图如下:
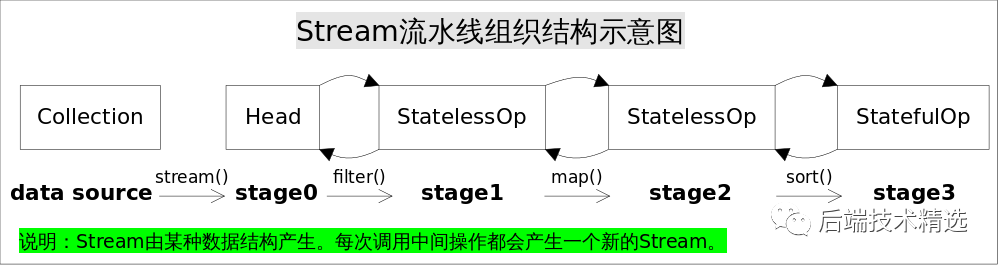
图中通过Collection.stream()方法得到Head也就是stage0,紧接着调用一系列的中间操作,不断产生新的Stream。
这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作。这就是Stream记录操作的方式。
>> 操作如何叠加
以上只是解决了操作记录的问题,要想让流水线起到应有的作用我们需要一种将所有操作叠加到一起的方案。你可能会觉得这很简单,只需要从流水线的head开始依次执行每一步的操作(包括回调函数)就行了。
这听起来似乎是可行的,但是你忽略了前面的Stage并不知道后面Stage到底执行了哪种操作,以及回调函数是哪种形式。换句话说,只有当前Stage本身才知道该如何执行自己包含的动作。这就需要有某种协议来协调相邻Stage之间的调用关系。
这种协议由Sink接口完成,Sink接口包含的方法如下表所示:
| 方法名 | 作用 |
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
有了上面的协议,相邻Stage之间调用就很方便了,每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的accept()方法即可,并不需要知道其内部是如何处理的。
当然对于有状态的操作,Sink的begin()和end()方法也是必须实现的。比如Stream.sorted()是一个有状态的中间操作,其对应的Sink.begin()方法可能创建一个盛放结果的容器,而accept()方法负责将元素添加到该容器,最后end()负责对容器进行排序。
对于短路操作,Sink.cancellationRequested()也是必须实现的,比如Stream.findFirst()是短路操作,只要找到一个元素,cancellationRequested()就应该返回true,以便调用者尽快结束查找。
Sink的四个接口方法常常相互协作,共同完成计算任务。
实际上Stream API内部实现的的本质,就是如何重写Sink的这四个接口方法。
有了Sink对操作的包装,Stage之间的调用问题就解决了,执行时只需要从流水线的head开始对数据源依次调用每个Stage对应的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。
一种可能的Sink.accept()方法流程是这样的:
void accept(U u){
1. 使用当前Sink包装的回调函数处理u
2. 将处理结果传递给流水线下游的Sink
}
Sink接口的其他几个方法也是按照这种[处理->转发]的模型实现。
下面我们结合具体例子看看Stream的中间操作是如何将自身的操作包装成Sink以及Sink是如何将处理结果转发给下一个Sink的。
先看Stream.map()方法:
// Stream.map(),调用该方法将产生一个新的Stream
public final Stream map(Functionsuper P_OUT, ? extends R> mapper) {
...
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override /*opWripSink()方法返回由回调函数包装而成Sink*/
Sink opWrapSink(int flags, Sink downstream) {
return new Sink.ChainedReference(downstream) {
@Override
public void accept(P_OUT u) {
R r = mapper.apply(u);// 1. 使用当前Sink包装的回调函数mapper处理u
downstream.accept(r);// 2. 将处理结果传递给流水线下游的Sink
}
};
}
};
}
上述代码看似复杂,其实逻辑很简单,就是将回调函数mapper包装到一个Sink当中。由于Stream.map()是一个无状态的中间操作,所以map()方法返回了一个StatelessOp内部类对象(一个新的Stream),调用这个新Stream的opWripSink()方法将得到一个包装了当前回调函数的Sink。
再来看一个复杂一点的例子。Stream.sorted()方法将对Stream中的元素进行排序,显然这是一个有状态的中间操作,因为读取所有元素之前是没法得到最终顺序的。抛开模板代码直接进入问题本质,sorted()方法是如何将操作封装成Sink的呢?sorted()一种可能封装的Sink代码如下:
// Stream.sort()方法用到的Sink实现
class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList list;// 存放用于排序的元素
RefSortingSink(Sinksuper T> downstream, Comparatorsuper T> comparator) {
super(downstream, comparator);
}
@Override
public void begin(long size) {
...
// 创建一个存放排序元素的列表
list = (size >= 0) ? new ArrayList((int) size) : new ArrayList();
}
@Override
public void end() {
list.sort(comparator);// 只有元素全部接收之后才能开始排序
downstream.begin(list.size());
if (!cancellationWasRequested) {// 下游Sink不包含短路操作
list.forEach(downstream::accept);// 2. 将处理结果传递给流水线下游的Sink
}
else {// 下游Sink包含短路操作
for (T t : list) {// 每次都调用cancellationRequested()询问是否可以结束处理。
if (downstream.cancellationRequested()) break;
downstream.accept(t);// 2. 将处理结果传递给流水线下游的Sink
}
}
downstream.end();
list = null;
}
@Override
public void accept(T t) {
list.add(t);// 1. 使用当前Sink包装动作处理t,只是简单的将元素添加到中间列表当中
}
}
上述代码完美的展现了Sink的四个接口方法是如何协同工作的:
首先begin()方法告诉Sink参与排序的元素个数,方便确定中间结果容器的的大小;
之后通过accept()方法将元素添加到中间结果当中,最终执行时调用者会不断调用该方法,直到遍历所有元素;
最后end()方法告诉Sink所有元素遍历完毕,启动排序步骤,排序完成后将结果传递给下游的Sink;
如果下游的Sink是短路操作,将结果传递给下游时不断询问下游cancellationRequested()是否可以结束处理。
>> 叠加之后的操作如何执行
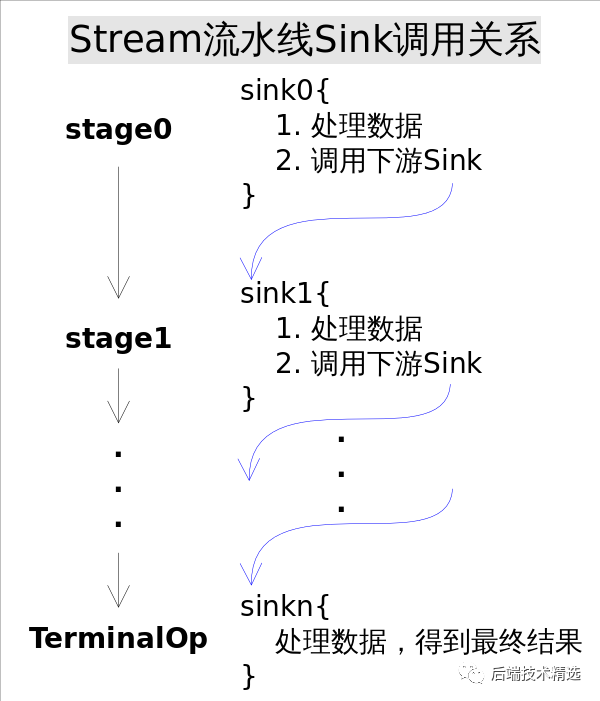
Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。
是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
结束操作之后不能再有别的操作,所以结束操作不会创建新的流水线阶段(Stage),直观的说就是流水线的链表不会在往后延伸了。
结束操作会创建一个包装了自己操作的Sink,这也是流水线中最后一个Sink,这个Sink只需要处理数据而不需要将结果传递给下游的Sink(因为没有下游)。对于Sink的[处理->转发]模型,结束操作的Sink就是调用链的出口。
我们再来考察一下上游的Sink是如何找到下游Sink的。一种可选的方案是在PipelineHelper中设置一个Sink字段,在流水线中找到下游Stage并访问Sink字段即可。
但Stream类库的设计者没有这么做,而是设置了一个Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法来得到Sink,该方法的作用是返回一个新的包含了当前Stage代表的操作以及能够将结果传递给downstream的Sink对象。为什么要产生一个新对象而不是返回一个Sink字段?
这是因为使用opWrapSink()可以将当前操作与下游Sink(上文中的downstream参数)结合成新Sink。
试想只要从流水线的最后一个Stage开始,不断调用上一个Stage的opWrapSink()方法直到最开始(不包括stage0,因为stage0代表数据源,不包含操作),就可以得到一个代表了流水线上所有操作的Sink,用代码表示就是这样:
// AbstractPipeline.wrapSink()
// 从下游向上游不断包装Sink。如果最初传入的sink代表结束操作,
// 函数返回时就可以得到一个代表了流水线上所有操作的Sink。
final Sink wrapSink(Sink sink) {
...
for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink) sink;
}
现在流水线上从开始到结束的所有的操作都被包装到了一个Sink里,执行这个Sink就相当于执行整个流水线,执行Sink的代码如下:
// AbstractPipeline.copyInto(), 对spliterator代表的数据执行wrappedSink代表的操作。
final void copyInto(Sink wrappedSink, Spliterator spliterator) {
...
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());// 通知开始遍历
spliterator.forEachRemaining(wrappedSink);// 迭代
wrappedSink.end();// 通知遍历结束
}
...
}
上述代码首先调用wrappedSink.begin()方法告诉Sink数据即将到来,然后调用spliterator.forEachRemaining()方法对数据进行迭代,最后调用wrappedSink.end()方法通知Sink数据处理结束。逻辑如此清晰。
>> 执行后的结果在哪里
最后一个问题是流水线上所有操作都执行后,用户所需要的结果(如果有)在哪里?首先要说明的是不是所有的Stream结束操作都需要返回结果,有些操作只是为了使用其副作用(Side-effects),比如使用Stream.forEach()方法将结果打印出来就是常见的使用副作用的场景(事实上,除了打印之外其他场景都应避免使用副作用),对于真正需要返回结果的结束操作结果存在哪里呢?
特别说明:副作用不应该被滥用,也许你会觉得在Stream.forEach()里进行元素收集是个不错的选择,就像下面代码中那样,但遗憾的是这样使用的正确性和效率都无法保证,因为Stream可能会并行执行。大多数使用副作用的地方都可以使用归约操作更安全和有效的完成。
// 错误的收集方式
ArrayList results = new ArrayList<>();
stream.filter(s -> pattern.matcher(s).matches())
.forEach(s -> results.add(s)); // Unnecessary use of side-effects!
// 正确的收集方式
Listresults =
stream.filter(s -> pattern.matcher(s).matches())
.collect(Collectors.toList()); // No side-effects!
回到流水线执行结果的问题上来,需要返回结果的流水线结果存在哪里呢?这要分不同的情况讨论,下表给出了各种有返回结果的Stream结束操作。
| 返回类型 | 对应的结束操作 |
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 归约结果 | reduce() collect() |
| 数组 | toArray() |
对于表中返回boolean或者Optional的操作(Optional是存放 一个 值的容器)的操作,由于值返回一个值,只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
对于归约操作,最终结果放在用户调用时指定的容器中(容器类型通过收集器指定)。collect(), reduce(), max(), min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用reduce()方法实现的。
对于返回是数组的情况,毫无疑问的结果会放在数组当中。这么说当然是对的,但在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。关于Node的具体结构,我们会在下一节探究Stream如何并行执行时给出详细说明。
结语
本文详细介绍了Stream流水线的组织方式和执行过程,学习本文将有助于理解原理并写出正确的Stream代码,同时打消你对Stream API效率方面的顾虑。如你所见,Stream API实现如此巧妙,即使我们使用外部迭代手动编写等价代码,也未必更加高效。
注:留下本文所用的JDK版本,以便有考究癖的人考证:
$ java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) Server VM (build 25.101-b13, mixed mode)推荐阅读
Spring 的 Controller 是单例还是多例?怎么保证并发的安全