
你要的机器学习知识点和算法,一文搞定!(附python代码)
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

机器学习发展到现在,已经形成较为完善的知识体系,同时大量的数据科学家的研究成果也让现实问题的处理有了相对成熟的应对算法。
所以对于一般的机器学习来说,解决问题的方式变的非常简单:熟悉这些基本的算法,并且遇到实际的问题能够系统地运用这些思想来解决。
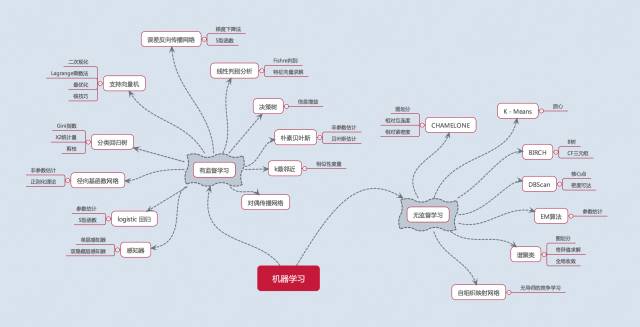
按学习方式划分的机器学习知识架构

机器学习细分方法(点击图片查看高清大图)
这篇文章将对机器学习算法进行分类的详细描述,并介绍几个常用的机器学习算法(附python代码),这些足够解决平时的大多数问题。
回归算法(Regression Algorithms)
回归是关注变量之间关系的建模,利用模型预测误差测量进行反复提炼。回归方法是统计工作,已纳入统计机器学习。这可能是令人困惑,因为我们可以用回归来引用各类的问题及各类算法,回归其实是一个过程。
普通最小二乘法 Ordinary Least Squares
逻辑回归 Logistic Regression
逐步回归 Stepwise Regression
多元自适应回归 MARS
局部散点平滑估计 LOESS
基于实例的方法(Instance-based Algorithms)
基于实例的学习模型是使用那些对于模型很重要训练数据,这类方法通常使用基于示例数据的数据库,用新数据和数据库数据以一种相似度方式从中找到最佳匹配,从而作出预测。出于这个原因,基于实例的方法也被称为赢家通吃所有的方法和基于记忆的学习。重点放在存储实例之间的相似性度量表现上。
k最邻近算法 k-Nearest Neighbour ,kNN
学习矢量量化 Learning Vector Quantization ,LVQ
自组织映射 Self-Organizing Map ,SOM
局部加权学习 Locally Weighted Learning ,LWL
正则化方法(regularization Algorithms)
正则化方法是其他算法(回归算法)的延伸,根据算法的复杂度对算法进行调整。正则化方法通常对简单模型予以奖励而对复杂算法予以惩罚。基于正则化方法的扩展 (典型是基于regression回归方法) 可能比较复杂,越简单可能会利于推广,下面列出的正则化方法是因为它们比较流行 强大简单。
岭回归数值计算方法 Ridge Regression
至少绝对的收缩和选择算子 LASSO
弹性网络 Elastic Net
决策树算法(Decision Tree Algorithms)
决策树方法是建立一种基于数据的实际属性值的决策模型。决策使用树型结构直至基于一个给定记录的预测决策得到。决策树的训练是在分类和回归两方面的数据上进行的。
分类回归树 Classification and Regression Tree ,CART
迭代二叉树3代 Iterative Dichotomiser 3 ,ID3
卡方自动交互检测 CHAID
多元自适应回归样条 MARS
梯度推进机 Gradient Boosting Machines ,GBM
单层决策树 Decision Stump
贝叶斯方法(Bayesian Algorithms)
贝叶斯分析方法(Bayesian Analysis)提供了一种计算假设概率的方法,这种方法是基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身而得出的。其方法为,将关于未知参数的先验信息与样本信息综合,再根据贝叶斯公式,得出后验信息,然后根据后验信息去推断未知参数的方法。
朴素贝叶斯 Naive Bayes
平均单依赖估计 AODE
贝叶斯置信网络 Bayesian Belief Network ,BBN
内核方法(Kernel Methods)
最有名的当属支持向量机的方法, 内核方法更关注将数据映射到高维空间向量,在那里可以进行一些分类或回归问题的建模。
支持向量机 Support Vector Machines ,SVM
径向基函数 Radial Basis Function ,RBF
线性鉴别分析 Linear Discriminate Analysis ,LDA
聚类算法(Clustering Algorithms)
聚类方法, 类似回归,是属于描述问题和方法的类别,聚集方法通常被建模于基于几何中心centroid-based和层次组织等系统。所有的方法都是有关使用数据中固有的结构,这样以便更好将数据组织为存在最大共性的分组。
聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。
k-Means聚类方法
期望最大化算法 Expectation Maximisation ,EM
关联规则学习(Association Rule Learning)
关联规则的学习方法是提取那些能解释观察到的变量之间的数据关系的规则。这些规则可以用于在大型多维数据集里,以便能发现重要的和商业上对某个组织或公司有用的的关联。
关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。
Apriori 算法
Eclat 算法
人工神经网络(Artificial Neural Network)
人工神经网络模型的灵感来自于生物神经网络的结构和功能。他们是一类的模式匹配,常用于回归和分类问题。
神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组织映射方法,以ART 模型为代表。虽然神经网络有多种模型及算法,但在特定领域的数据挖掘中使用何种模型及算法并没有统一的规则,而且人们很难理解网络的学习及决策过程
因为各种各样的问题类型有数百种分支的算法。一些经典的流行的方法:
感知器神经网络 Perceptron
反向传播 Back-Propagation
霍普菲尔网络 Hopfield Network
自组织映射 Self-Organizing Map ,SOM
学习矢量量化 Learning Vector Quantization ,LVQ
深度学习(Deep Learning)
深度学习方法是一个现代的人工神经网络方法升级版,利用丰富而又廉价的计算,建立更大和更复杂的神经网络,许多方法都是涉及半监督学习(大型数据中包含很少有标记的数据)。
受限波尔兹曼机 Restricted Boltzmann Machine ,RBM
深度置信网络 Deep Belief Networks ,DBN
卷积神经网络 Convolutional Neural Network,CNN
堆栈式自动编码器 Stacked Auto-encoders
降维方法(Dimensionality Reduction)
类似群集clustering方法, 降维是寻求和利用数据的内在结构,但在这种情况下,使用无监督的方式只能较少的信息总结或描述数据。以监督方式使用是有用的,能形成可视化的三维数据或简化数据。
主成分分析 Principal Component Analysis ,PCA
偏最小二乘回归 Partial Least Squares Regression ,PLS
萨蒙映射 Sammon Mapping
多维尺度 Multidimensional Scaling ,MDS
投影寻踪 Projection Pursuit
模型融合算法(Ensemble Algorithms)
由多个独立训练的弱模型组成,这些模型以某种方式结合进行整体预测。大量的精力需要投入学习什么弱类型以及它们的组合方式。这是一个非常强大的很受欢迎的技术类别:
Boosting/AdaBoost
自展输入引导式聚合 Bootstrapped Aggregation
堆栈泛化 Stacked Generalization
梯度Boosting机器 Gradient Boosting Machines ,GBM
随机森林 Random Forest
经过上面的描述,机器学习的主流算法基本都已经包括了。但是你肯定会想,这样的分类是否真的科学?诚然,笔者并没有找到完全科学的分类方式,按有无监督的情况来进行分类似乎更准确一些。但是那只说明了算法本身的特征,而我们更需要的是从算法的功能用途来进行分类,这样我们在遇到某一类问题时可以直接利用这些算法切入。
还有一些情况需要说明,比如支持向量机(SVM),既可以用于分类,也可用于回归分析,很难归于某一类。又比如一些具体的领域,如计算机视觉 (CV)、自然语言处理(NLP)、推荐系统等,复杂的实际情况更难使解决问题的算法归于某一类,很可能是多种问题的集合。
这么多的算法,全部融会贯通真的是一件极其困难的事情,就算你全部掌握,也很难在具体问题中做出选择。而对于实际的问题的处理,目前都有了主流的方法,以下10种算法是现在最流行的机器学习算法(含python代码),几乎可以解决绝大部分的问题。
1.线性回归 Linear Regression
线性回归是利用连续性变量来估计实际数值(例如房价,呼叫次数和总销售额等)。我们通过线性回归算法找出自变量和因变量间的最佳线性关系,图形上可以确定一条最佳直线。这条最佳直线就是回归线。这个回归关系可以用Y=aX+b 表示。
Python 代码:
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import linear_model
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient:
', linear.coef_)print('Intercept:
', linear.intercept_)#Predict Output
predicted= linear.predict(x_test)
2.逻辑回归 Logistic Regression
逻辑回归其实是一个分类算法而不是回归算法。通常是利用已知的自变量来预测一个离散型因变量的值(像二进制值0/1,是/否,真/假)。简单来说,它就是通过拟合一个逻辑函数来预测一个事件发生的概率。所以它预测的是一个概率值,它的输出值应该在0到1之间。
Python 代码:
#Import Library
from sklearn.linear_model import LogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)#Equation coefficient and Intercept
print('Coefficient:
', model.coef_)print('Intercept:
', model.intercept_)#Predict Output
predicted= model.predict(x_test)
3.决策树 Decision Tree
既可以运用于类别变量(categorical variables)也可以作用于连续变量。这个算法可以让我们把一个总体分为两个或多个群组。分组根据能够区分总体的最重要的特征变量/自变量进行。
Python 代码:
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini') # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
4.支持向量机 SVM
给定一组训练样本,每个标记为属于两类,一个SVM训练算法建立了一个模型,分配新的实例为一类或其他类,使其成为非概率二元线性分类。一个SVM模型的例子,如在空间中的点,映射,使得所述不同的类别的例子是由一个明显的差距是尽可能宽划分的表示。新的实施例则映射到相同的空间中,并预测基于它们落在所述间隙侧上属于一个类别。
Python 代码:
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
5.朴素贝叶斯 Naive Bayes
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
Python 代码:
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
6.K邻近算法 KNN
这个算法既可以解决分类问题,也可以用于回归问题,但工业上用于分类的情况更多。KNN先记录所有已知数据,再利用一个距离函数,找出已知数据中距离未知事件最近的K组数据,最后按照这K组数据里最常见的类别预测该事件。
Python 代码:
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
7.K-均值算法 K-means
首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然 后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。
Python 代码:
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)
8.随机森林 Random Forest
随机森林是对决策树集合的特有名称。随机森林里我们有多个决策树(所以叫“森林”)。为了给一个新的观察值分类,根据它的特征,每一个决策树都会给出一个分类。随机森林算法选出投票最多的分类作为分类结果。
Python 代码:
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
9.降维算法
Dimensionality Reduction Algorithms
我们手上的数据有非常多的特征。虽然这听起来有利于建立更强大精准的模型,但它们有时候反倒也是建模中的一大难题。怎样才能从1000或2000个变量里找到最重要的变量呢?这种情况下降维算法及其他算法,如决策树,随机森林,PCA,因子分析,相关矩阵,和缺省值比例等,就能帮我们解决难题。
Python 代码:
#Import Library
from sklearn import decomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced = pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced = pca.transform(test)
10.Gradient Boost/Adaboost算法
GBM和AdaBoost都是在有大量数据时提高预测准确度的boosting算法。Boosting是一种集成学习方法。它通过有序结合多个较弱的分类器/估测器的估计结果来提高预测准确度。这些boosting算法在DataCastke 、Kaggle等数据科学竞赛中有出色发挥。
Python 代码:
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)