
【面试招聘】拼多多 AI算法岗面试(附带解析)
字数统计:2500,预计阅读时间:12min
参考目录:
1 介绍项目
2 EfficientNet的特色
3 python撕BN层前向算法
4 线程和进程的区别
5 SVM和逻辑回归在分类上的区别
6. 有什么人脸检测的数据集
7. YOLO训练的数据集是什么
8. CNN参数初始化的方法
1 介绍项目
答案:略。
2 EfficientNet的特色
这个EfficientNet的核心思想是寻找标准化的模型缩放方法,一般来说,模型深度、宽度、分辨率越大,那么模型的效果就会有提高。以前的网络一般在某一个维度上进行尝试,而EfficientNet因为团队有钱(google的),愣是在三个维度上找到了一个平衡。EfficientNet在图像竞赛中也是直接拿来用,用的也多,所以之后有空把之前写的《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》论文笔记整理整理发出来。总之这里回答的关键在于这个公式:
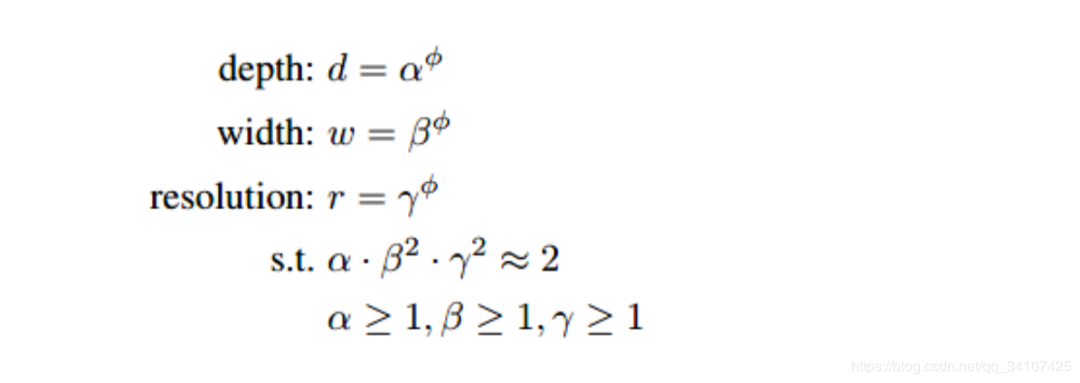
首先让深度宽度和分辨率满足一定的条件,当的时候,,然后不断扩大,就可以得到更复杂的模型了。
3 python撕BN层前向算法
之前的文章详细讲解了BN的算法,所以这个不算太难哈哈。核心思想就是把数据沿着batch的维度,标准化成均值,标准差的分布。减均值处以方差那种。
小白学图像 | BatchNormalization详解与比较
小白学图像 | Group Normalization详解+PyTorch代码
(这两个一起食用效果更佳哦)
突然一身冷汗,如果要让我写反向传播算法的代码。。。手推能算,代码的话。。。啧啧啧。
4 线程和进程的区别
进程:进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间。比较稳定。线程:线程是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.它可与同属一个进程的其他的线程共享进程所拥有的全部资源。但是不够稳定容易丢失数据。
【进程多与线程比较】
地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源 线程是处理器调度的基本单位,但进程不是 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
5 SVM和逻辑回归在分类上的区别
这个问题我也被问了两次了,这里好好整理一下回答的核心:SVM和逻辑回归其实是只有损失函数有不同。这个问题其实就是让你分析损失函数不同对分类的影响。
我们先来看一下SVM和逻辑回归的损失函数(这里带上了正则项):
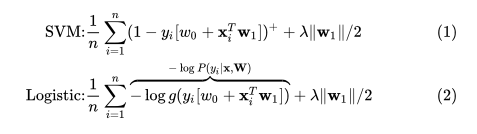
这损失函数看起来可能有些别扭,但是其实是和你内心想的那个是等价的(把这两个公式在纸上抄三遍,你就发现其实很好理解的)。在公式(1)中,SVM的损失函数那个+号,表示负数取0整数不变的一个成处理符号。公式(2)中的是Sigmoid激活函数。
这两个公式其实可以统一起来:

也就是说,它们的区别就在于逻辑回归采用的是 log loss(对数损失函数),svm采用的是hinge loss = max(0,1-z)。
z是,z越大,说明分类越准确,z越小,分类越错误。这里类别标签是+1和-1.
SVM损失函数: logistic损失函数:
两者损失函数的图像就是:
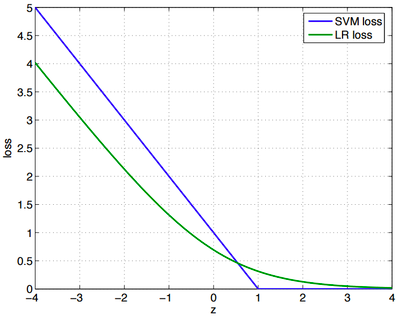
其实,这两个损失函数的目的都是给分类错误的样本大的损失,给分类正确的样本小的损失。SVM的处理方法是只考虑分类效果不够好的样本,对于已经分类正确的样本,就不再更新他们了,给他们0损失;逻辑回归希望正样本尽可能的大,副样本尽可能的小,所以就算已经分类正确了,也还是会给分类正确的样本一个损失。
辅导员(SVM)关心的是挂科边缘的人,常常找他们谈话,告诫他们一定得好好学习,不要浪费大好青春,挂科了会拿不到毕业证、学位证等等,相反,对于那些相对优秀或者良好的学生,他们却很少去问,因为辅导员相信他们一定会按部就班的做好分内的事;有的教师(逻辑回归)却不是这样的,他们关心的是班里的整体情况,不管你是60分还是90分,都要给我继续提升。
6. 有什么人脸检测的数据集
回答了IMDB-WIKI数据库。
IMDB-WIKI人脸数据库是有IMDB数据库和Wikipedia数据库组成,其中IMDB人脸数据库包含了460,723张人脸图片,而Wikipedia人脸数据库包含了62,328张人脸数据库,总共523,051张人脸数据库,IMDB-WIKI人脸数据库中的每张图片都被标注了人的年龄和性别,对于年龄识别和性别识别的研究有着重要的意义。
7. YOLO训练的数据集是什么
ImageNet和VOC2007.YOLO v1 好像只用了VOC2007,后面YOLOv2使用了ImageNet作为预训练。
8. CNN参数初始化的方法
我说了Xavier,然后均匀分布,0初始化,高斯分布初始化,预训练初始化。
Xavier这个我之前也在文章中详细讲解了,就是在这个范围内均匀分布,其中表示第k层卷积层的参数。
其实还有一个HE初始化,这个的思想和Xavier其实相同,都是为了让正向传播和反向传播的过程中,输入数据和输出数据的方差保持不变。最终Xavier是一个均匀分布,而He初始化是一个以0为均值,以为标准差的高斯分布。
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):