
Qwen-VL:最新国产多模态大模型,基于通义千问-7B
鱼羊 发自 凹非寺 量子位 | 公众号 QbitAI
阿里开源大模型,又上新了~
继通义千问-7B(Qwen-7B)之后,阿里云又推出了大规模视觉语言模型Qwen-VL,并且一上线就直接开源。

具体来说,Qwen-VL是基于通义千问-7B打造的多模态大模型,支持图像、文本、检测框等多种输入,并且在文本之外,也支持检测框的输出。
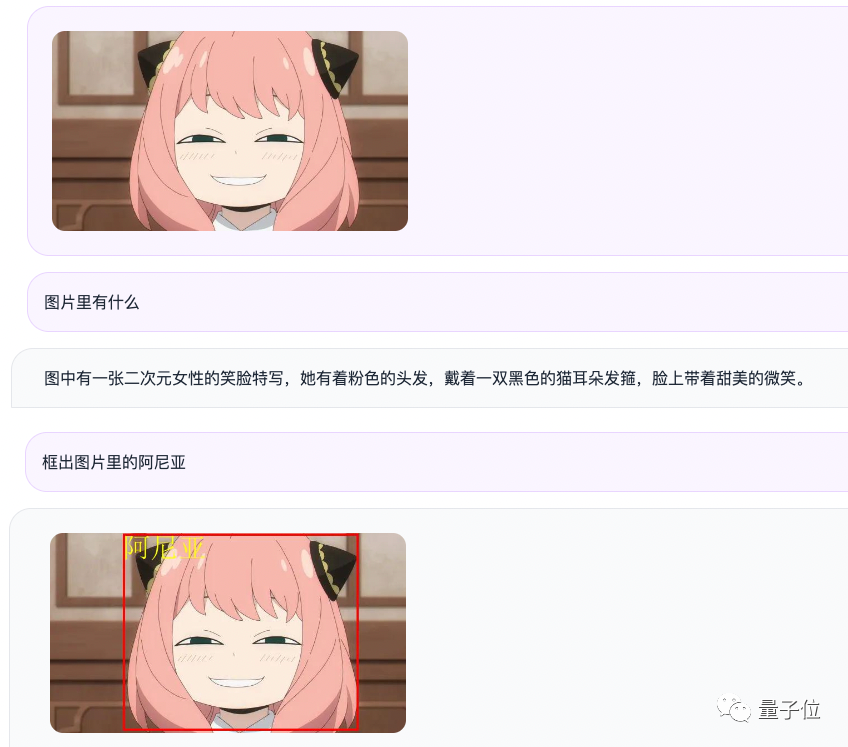
举个🌰,我们输入一张阿尼亚的图片,通过问答的形式,Qwen-VL-Chat既能概括图片内容,也能定位到图片中的阿尼亚。
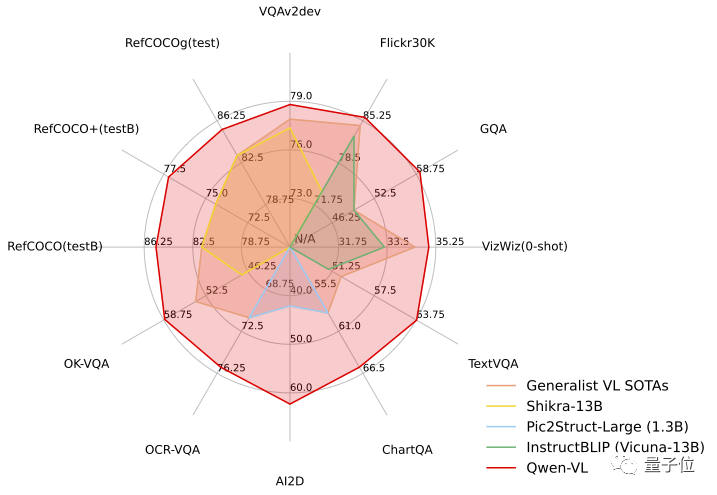
测试任务中,Qwen-VL展现出了“六边形战士”的实力,在四大类多模态任务的标准英文测评中(Zero-shot Caption/VQA/DocVQA/Grounding)上,都取得了SOTA。
开源消息一出,就引发了不少关注。

具体表现如何,咱们一起来看看~
首个支持中文开放域定位的通用模型
先来整体看一下Qwen-VL系列模型的特点:
多语言对话:支持多语言对话,端到端支持图片里中英双语的长文本识别;
多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
首个支持中文开放域定位的通用模型:通过中文开放域语言表达进行检测框标注,也就是能在画面中精准地找到目标物体;
细粒度识别和理解:相比于目前其它开源LVLM(大规模视觉语言模型)使用的224分辨率,Qwen-VL是首个开源的448分辨率LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
按场景来说,Qwen-VL可以用于知识问答、图像问答、文档问答、细粒度视觉定位等场景。
比如,有一位看不懂中文的外国友人去医院看病,对着导览图一个头两个大,不知道怎么去往对应科室,就可以直接把图和问题丢给Qwen-VL,让它根据图片信息担当翻译。

再来测试一下多图输入和比较:
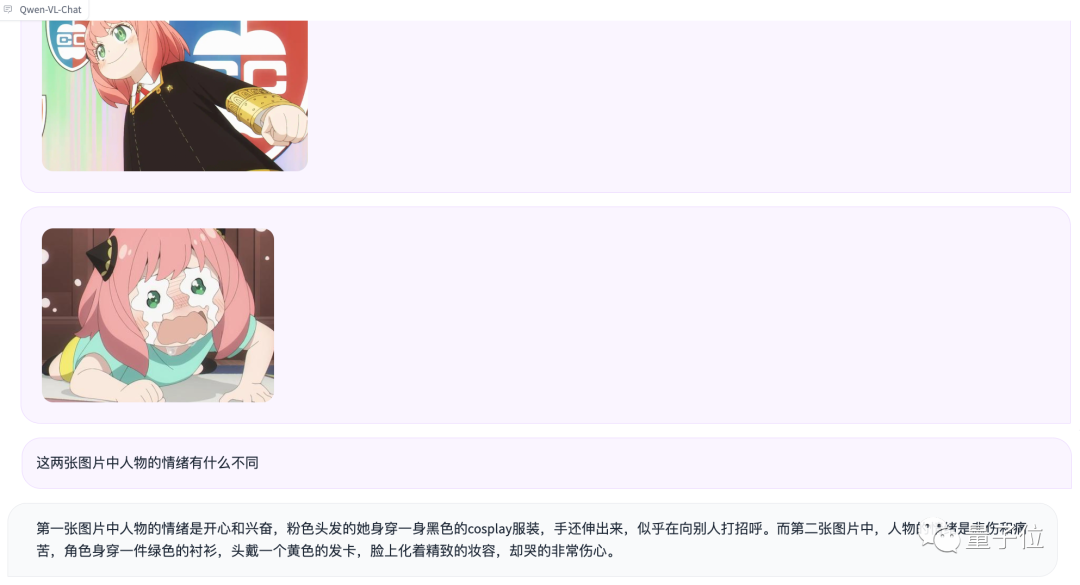
虽然没认出来阿尼亚,不过情绪判断确实挺准确的(手动狗头)。
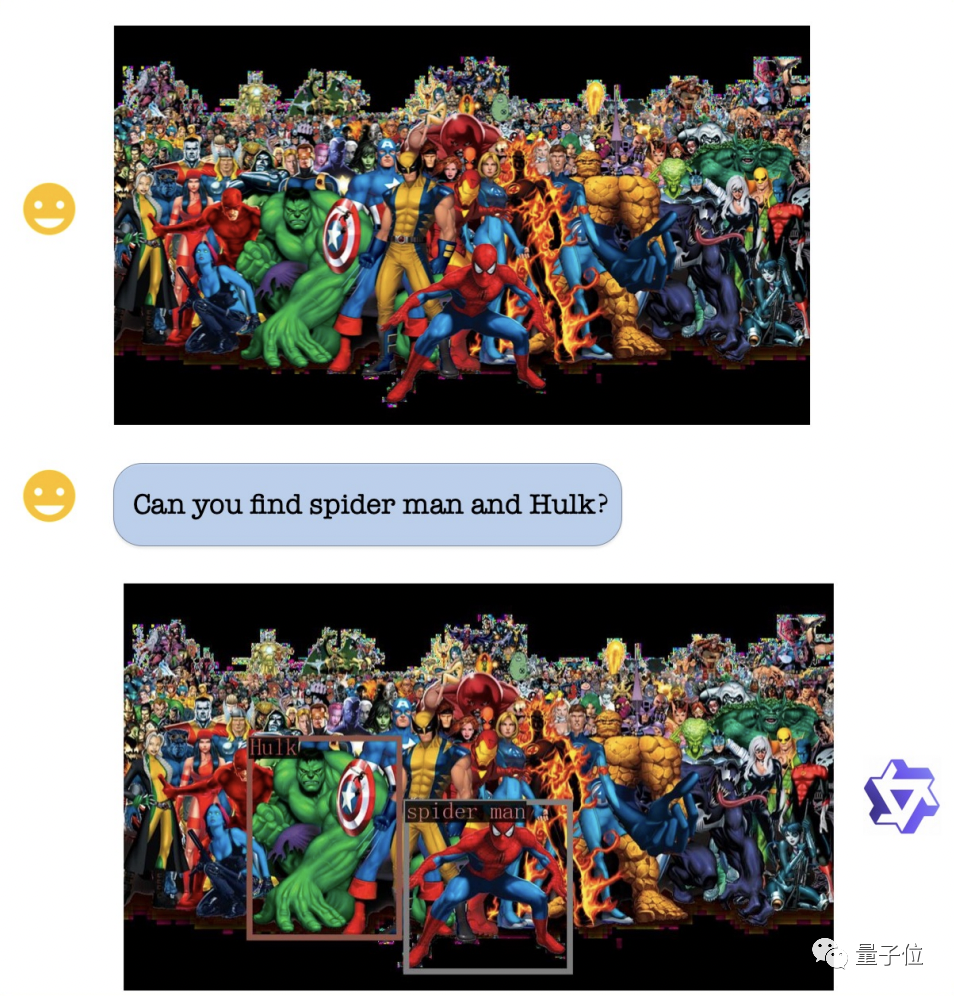
视觉定位能力方面,即使图片非常复杂人物繁多,Qwen-VL也能精准地根据要求找出绿巨人和蜘蛛侠。
技术细节上,Qwen-VL是以Qwen-7B为基座语言模型,在模型架构上引入了视觉编码器ViT,并通过位置感知的视觉语言适配器连接二者,使得模型支持视觉信号输入。
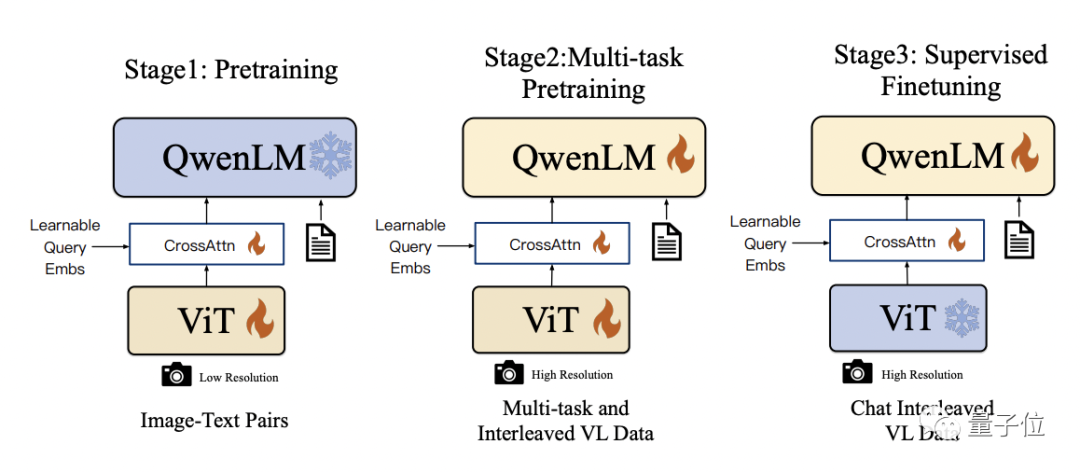
具体的训练过程分为三步:
预训练:只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224x224。
多任务预训练:引入更高分辨率(448x448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
监督微调:冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
研究人员在四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)的标准英文测评中测试了Qwen-VL。
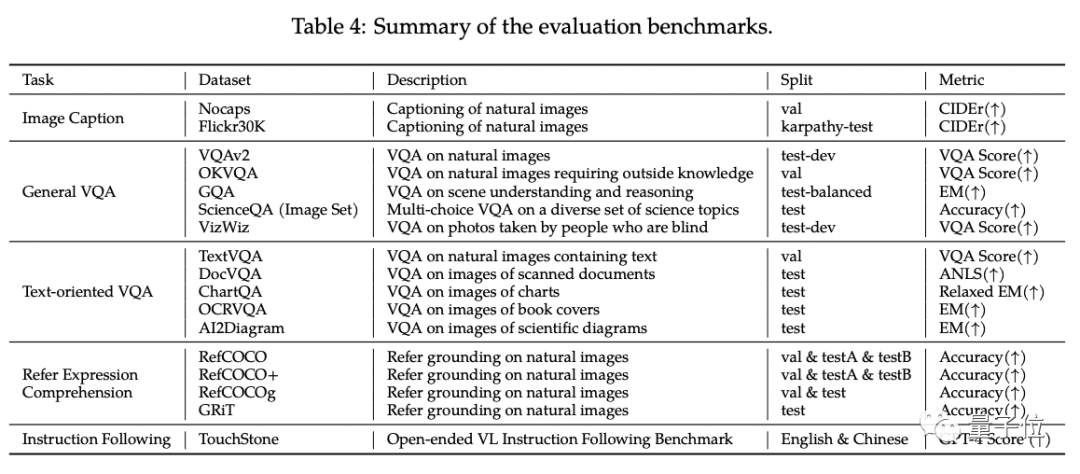
结果显示,Qwen-VL取得了同等尺寸开源LVLM的最好效果。
另外,研究人员构建了一套基于GPT-4打分机制的测试集TouchStone。

在这一对比测试中,Qwen-VL-Chat取得了SOTA。
如果你对Qwen-VL感兴趣,现在在魔搭社区和huggingface上都有demo可以直接试玩,链接文末奉上~
Qwen-VL支持研究人员和开发者进行二次开发,也允许商用,不过需要注意的是,商用的话需要先填写问卷申请。
项目链接:
https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/QwenLM/Qwen-VL
论文地址:
https://arxiv.org/abs/2308.12966
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!