
关于编码的那些事——前端应该了解的字符编码
本文为来自 字节教育-成人与创新前端团队 成员的文章,已授权 ELab 发布。
背景
工作中我们会不会遇到以下问题:
可能你知道 JavaScript 中 '😁'.length = 2,但 '👨👩👧👦'.length 呢?可以自行实验下,思考为何如此 困惑于 Unicode 和 UTF-8 的关系? 学计算机时会遇到这样的提问:一个汉字是几个字节? 读取二进制数据时,为何有大端序小端序的分别? 为何 UTF-8 文件最好存储为无 BOM 头格式? 数据乱码时总会看到“锟斤拷”、“烫烫烫”,这是什么鬼?
这些问题都涉及计算机中基础的知识点:字符集及字符编码的概念,希望通过这篇文章可以让你彻底清晰的理解这些问题。
字符集与字符编码
首先通过 wiki 中关于字符编码(Character_encoding)的定义来引入几个概念:
Character encoding is the process of assigning numbers to graphical characters, especially the written characters of human language, allowing them to be stored, transmitted, and transformed using digital computers.
The numerical values that make up a character encoding are known as "code points" and collectively comprise a "code space", a "code page", or a "character map".
字符编码是将数字分配给图形字符的过程,特别是人类语言的书写字符,使它们能够使用计算机进行存储、传输和转换。组成字符编码的数值称为“码位”,它们共同组成“代码空间”、“代码页”或“字符映射”。
这里所说的代码页(Code Page)其实就可以理解为编码字符集(coded character set),如 Unicode、GBK 字符集等。
简单来说,字符编码就是将字符映射为固定的码位值,存储在对应的编码字符集中。在不同的字符集中,同一个字符的码位不同。其中码位也有翻译成码点或者内码。
ASCII 字符集
我们知道在计算机存储数据时要使用二进制进行表示。而最初计算机只在美国使用,因此人们要考虑如何使用二进制来表达 52 个英文字母(包括大小写)、阿拉伯数字(0-9)以及常用的符号(如! @ # $ 等)。
于是便有从电报码发展而来的 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)(发音 /ˈæski/)编码。它定义了英文字符和二进制的对应关系,一直沿用至今。
它采用了单字节编码方案(SBCS) ,一个字节的首位 bit 为 0,用其余 7 个 bit 来表示 128 个字符(范围 0x00-0x7F)
其中 0-31 和 127 (0x00-0x1F 和 0x7F) 为控制字符,共 33 个。这些字符是不可见的,用于进行终端的换行、响铃、删除等动作。 32-126 (0x20-0x7E) 位可见字符,共 95 个,存储了空格、0-9 十个阿拉伯数字、52 个大小写英文字母,以及标点、运算符号等。
虽然现代英语使用 128 个字符就足够了,但表示其他语言就远远不够了。因此当 ASCII 进入欧洲后,又被扩展为了 EASCII(Extended ASCII),将 7 bit 扩展为 8 bit,并且前 127 个编码含义和 ASCII 保持一致。
但 256 个字符依旧无法解决众多使用拉丁字母的语言(主要是欧洲语言)问题。于是又扩展出了 15 个 ISO 8859 字符集。举几个字符集作为了解 ISO/IEC 8859-1 (Latin-1) - 西欧语言 ISO/IEC 8859-2 (Latin-2) - 中欧语言 ISO/IEC 8859-3 (Latin-3) - 南欧语言 ISO/IEC 8859-4 (Latin-4) - 北欧语言 ...
中文字符集
前面讲到拉丁文所使用是 ASCII 和 EASCII,但在亚洲——主要是中日韩(CJK)——光常用汉字就 6000 多个,而汉字总共有 5、6 万之多,单靠一个字节是远远没办法做到的。因此聪明的中国人(也可能是日本人)就想到使用双字节编码(DBCS) 来表示一个汉字,这样理论上 2 个字节可以表达 65535 个字符(当然很理论,实际上要少很多)。这样就可以表示大部分常用字符了,接下来就要讲到和中文有关的 GB 系列(如 GB2312、GBK、GB18030)的字符集了。
其实 GB 就是“国标”汉语拼音的首字母,而 GBK 就是“国标扩展”的意思,而 GB18030 是在保留 GBK 编码基础上再度扩展为可变的 4 字节编码空间的编码规范。
这里我们着重介绍下 GB2312 的编码结构。
GB/T 2312
GB2312 全称《信息交换用汉字编码字符集·基本集》,收录了 6763 个汉字,682 个拉丁、希腊、日文假名等字符。就将其中汉字覆盖了大陆 99.75% 的使用频率,足够大部分的场景使用的。
同时还把 ASCII 中标点符号、阿拉伯数字、英文字符用双字节收录在内,这里为了区别于 ASCII 中的字符,就将其做成了与汉字等宽的正方型效果(即拉丁字母的两倍宽),以表示和编码存储方式一一对应。因为字符编码和字宽的对应关系,我们这就称这类字符为「全角」字符,而 ASCII 中的字符则为「半角」字符。(这种叫法源于日本,因为在日本中“角”有“方块”的意思)
接下来看看如何编码的。规范将收录的汉字分成 94 个区,每个区又包含 94 个汉字,用所在的区位来表示一个字符(这种方法也称为区位码) 。每个字符用 2 个字节表示,其中第一个字节称为「高位字节」表示分区号,第二个字节称为「低位字节」表示区段内的码位。另外实际 GB2312 仅用了 87 个区,88-94 区保留待扩展。
为了避开 ASCII 中前面的 31 个不可见控制符和空格,在区位码基础上 +32(0x20),这样获得的编码就称为 ISO-2022 国标码。
但是实际使用时,英文字符和汉字混用的情况很常见,国标码仅避让开了控制字符,依然和 ASCII 的英文字符有重合,因此决定在国标码的基础上将单字节的最高位 bit 存为 1,即在国标码上 +128(0x80),也就是区位码上 +160 (0xA0),这样就完美的避让开了 ASCII 字符区间。这样种编码就叫做 EUC-CN 机内码。
EUC-CN 机内码 = 区位码 + 160
而目前 GB2312 所采用的就是 EUC 这种主流编码方式,以便于兼容 ASCII 码。同时也可以根据最高位 bit 来判断是读取 1 个字符(ASCII)还是 2 个字符来进行解析。在 GB2312 内,高位字节范围 0xA1-0xF7(01-87 区+160 或 0xA0),低位字节范围 0xA1-0xFE(01-94 + 160 或 0xA0)。
以“节”为例:
区位码是 29-58 EUC 编码就是 <29+160, 58+160> = <189, 218>, 十六进制就是 <0xBD, 0xDA>。
GBK/GB18030
但是新的问题来了,GB2312 仅收入了 6763 个常用的汉字,一些在标准推出以后的简化字(如 啰)、港澳台使用的的繁体字、某些领导人的名字(朱镕基的镕),以及各地区户籍中用到奇奇怪怪的名字、古籍中的汉字都没法正确表示。因此在 GB2312 的基础上又扩展出了 GBK 和 GB18030,并且向下兼容(严格来讲 GB18030 完全兼容 GB2312,基本兼容 GBK)。
GBK 的基本原理就是继续扩展了 GB2312 中未使用的双字节空间,字符多达 23940 个。而 GB18030 则更为激进,干脆将存储空间变成可变的 1、2、4 字节,理论上可以存储 161 万个字符,完全涵盖 Unicode 范围。同时 GB18030 还收录了中日韩、繁体字、少数民族文字等多种语言。
Big5
于此同时,海峡对岸的程序员也发明出了一套自己的繁体中文标准,由于起初项目名称是「五大中文套装软件」,因此称为 Big5,也叫大五码。记得当年想要玩台湾“流入”的游戏,MagicWin 这类的转码软件是装机必备。
Unicode 字符集
随着世界各个地区编码方式越来越多,给不同地区间数据传输造成非常大的困难,比如一个从中国发送到日本邮件的,在不知道其编码的情况下,就会出现乱码。因此终于有人开始想用一种更加通用的方案,来涵盖世界上所有的字符和符号——这就是 Unicode,如其名字本身的含义一样。
首先 Unicode 也采用了 16 位的编码空间,即 2 个字节表示一个字符,用 "U+"接 4 个十六进制数字表示(例如U+4AE0),每个字符分配一个唯一的「码点」(CodePoint,也称码位)。同时又定义了 17 个编组,每组称为一个「平面」(Plane)。这样字符范围从 0x00000 - 0x10FFFF,这样就可以最多表示 17 * 65536 也就是 100多万个字符,完全可以存储全世界所有的语言和符号了。
这其中将常用的字符存放在第一个编组,即 0 号平面(Plane 0),也称之为「基本多文种平面 」(BMP - Basic Multilingual Plane),其范围是 0x0000 - 0xFFFF 。而 1-16 号平面被称为「辅助平面」(Supplementary Planes),用于存储很少使用的文字或者图形符号(emoji 表情符号就存于这些平面),其范围是 0x10000-0x10FFFF。
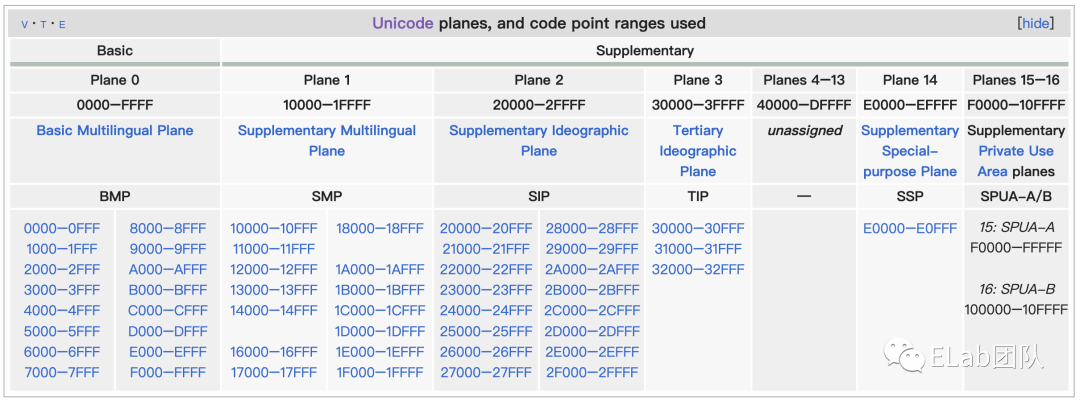
Unicode 字符表的范围涵盖的字符和符号非常广,不仅收录了表情符号、麻将、音乐符号等表意符号外,还收录了一些早已不再使用的文字,比如甲骨文、古埃及的圣书体,甚至收录了为影视剧而创造的语言——克林贡语。并且还在持续更新中,截止此文完成,最近的一次更新是在2022年9月。
但是这里有个比较严重的问题:
不同码位的字符使用不同的字符长度,但计算机无法知道到底是按照 2 个还是 4 个字符解析; 即便只使用英文字符前一个字节也必须是 0,严重浪费了空间。
由于这个问题导致 Unicode 的在初期完全没法推广,直到互联网的普及,急需一种对 Unicode 字符的编码方式出现,这就是 ****UTF(Unicode Transformation Format)。在 UTF 中又出现了 UTF-8、UTF-16、UTF-32 这些不同的编码方式。
UTF-32
首先人们想到的就是干脆所有字符直接用 4 个字节存储,不足 4 位的就补 0 代替。但是这样简单粗暴,尤其仅使用英文的数据,会造成了空间的极大浪费。
比如拉丁字母 A 的 Unicode 码点为 U+0065,十六进制为 0x41,如果使用 UTF-32 编码就是 0x00000041。
于是人们又开始设计一种可以节省空间的编码方式——UTF-8。
UTF-8
UTF-8 最大的特点是可变长编码,它使用 1-4 个字节表示一个字符。它的编码方式如下:
由于 Unicode 在 0+0000-0+007F 范围和 ASCII 完全相同,因此使用单字节表示,这样 ASCII 和 UTF-8 的编码一样,是完全兼容的。
在大于 0+007F 的字符时,是由 1 个前导字节(leading bytes)和 n 个(n >=1 )尾字节(trailing bytes)的多字节结构组成。前导字节从最左侧起用
1来表示这个字符有多少位,直到遇到0为止。尾字节前两位都是10,其余的 bit 位就是可用编码空间。比如,第一个字节是 0xxxxxxx,就表示该字符只有 1 个字节; 第一个字节是 110xxxxx,表示该字符有 2 个字节,第二个字节是 10xxxxx; 第一个字符是 1110xxxx,表示该字符有 3 个字节,后面字节分别是 10xxxxx 10xxxxx; 第一个字节是 11110xxx,表示该字节有 4 个字节,后面字节分别是 10xxxxx 10xxxxx 10xxxxx。
这里 x 就表示可用的编码空间,这也就是 UTF-8 中 8 表示至少 8 位表示一个字符,同时也是以 8 位为一组实现可变字节的编码方式。(这里之所以跳过了 10xxxxxx,是因为 10 表示尾字节)
以下就是完整编码方式,当然 5、6 字节的编码方式不会出现,因为已经远超 Unicode 最大码点范围 U+10FFFF 了。

接下来我们用“兔” 和 emoji “🐰” 来举例,来说明下 UTF-8 是如何编码的。
兔:
码点为 U+5154 二进制表示为 101000101010100, 从末尾按 6 个 bit 分组 101 000101 010100 需要 3 个字节,则开头插入 1110,中间不足 8 位用 0 补足,剩余前面插入 10,则得到 11100101 10000101 10010100 转为十六进制,E5 85 94
🐰 的 emoji
码点为 U+1F430 二进制为 11111010000110000 从末尾按 6 个 bit 分组 11111 010000 110000 第一部分为 5 位,插入 1110 位后占 9 位,超出一个字节,所以前面补一个字节,用 4 个字节表示。不足 8 位的用 0 补足。则得到 11110000 10011111 10010000 10110000 转为十六进制,F0 9F 90 B0
由于 JS 中 encodeURI 是按照 UTF-8 进行百分号编码,因此感兴趣的同学可以进行验证下
encodeURI('兔');
// %E5%85%94
encodeURI('🐰');
// %F0%9F%90%B0
除了相对于 4 字节编码更省空间外,UTF-8 编码还以下比较优秀的特性:
ASCII 是 UTF-8 的一个子集,一个纯 ASCII 字符串也是一个合法的 UTF-8 字符串。因此现存的 ASCII 数据可以不经修改即可使用。 单字节范围 0x00-0x7F,而多字节的前导字节范围总是在 0xC0-0xFD,尾字节都在 0x80-0xBF 中,三者完全没有重叠。通过范围就可以确定字节的类型,如果字节流在传输时中断,不完整的字节也不会被解码。这样数据有损坏、丢失,影响的范围也会很小。试想下,如果有一个按照每 4 个字节为一组的编码方法,如果丢失了第一个字节的数据,那么继续按照 4 字节一组的方式读取数据,后面的数据都将无法读取。 另外由于前导字节和尾字节范围互不重叠,即便从一个字符的某个中间字节开始读取,也不会错把它和下一个字符拼接错。这种特性也叫自同步码。比如,“兔子”的编码为 E5 85 94 / E5 AD 90,你不会错把 85 94 E5 或者 AD 90 当做一个字符,因为根本不存在这样规则的 UTF-8 编码。 仅通过首字节就能确定整体字节长度,而无需等待下一个字节的读取。 理论 6 个字节可以存放 2^31 个字符,即 21 亿个字符!即便是 4 字节也可以存放 200 多万个字符。其范围已超 Unicode 的容量了。 UTF-8 中未使用 0xFE 和 0xFF。 UTF-8 字节串的排列顺序是固定的,和系统无关。没有字节序(即是按大端序还是小端序的先后顺序)的问题。因此也无需使用 BOM 头(虽然其 BOM 头是 0xEF 0xBB 0xBF,但仅表示 UTF-8 编码格式,不表示字节顺序)。
虽然 UTF-8 有诸多优势,但是也有缺点:
中日韩文字至少需要 3 个字节存储,比 GBK 这类双字节存储要多一个字节。 由于其是变长字节,一个字符可能是 1、2、3 个字节,因此当计算一组字节中包含多少个字符,就要从头遍历,才能确定到底有多少个字符。当我们需要获取指定位置的字符时,依然要从头遍历。这也为程序的实现带来了很大的麻烦。
因此一些程序在内部处理字符串时,就使用了另外一种编码方式 UTF-16,其中 JavaScript、Python 就使用了这种编码方式来存储字符串。
UTF-16
UTF-16 也采用了变长的编码方式。使用 2 个或者 4 个字节表示一个字符。其规则是:
在基本平面 BMP 内(U+0000 至 U+FFFF)的字符用 2 个字节表示; 在辅助平面内(U+10000 至 U+10FFFF)的字符用 4 个字节表示。
其中 BMP 的字符直接使用 Unicode 码点对应即可,比如“兔”的码点 U+5154,UTF-16 编码就是 0x5154。
可是 BMP 外,要如何使用 4 个字节表示呢?假如我们使用 UTF-32 的方式,直接使用码点映射会遇到什么问题?还以“🐰”为例,其码点是 U+1F430。如果直接映射为 0x0001F430,头 2 个字节 0x0001 对应的字符在 BMP 中已经存在,这样在读取数据时就无法区分到底是按照 2 字节解析,还是按照 4 个字节解析了。
幸而在 BMP 中,从 U+D800 到 U+DFFF 是一个永远保留不做映射的空段,于是 UTF-16 将辅助平面内的字符 —— 共需要 20 个 bit 表示(由 0x10FFFF - 0x100000 = 0xFFFFF 计算得来) —— 拆分成 2 段,前 10 个 bit 位映射到 U+D800 - U+DBFF(正好 1024 个),后 10 个 bit 映射到 0xDC00 - 0xDFFF(也正好 1024 个)。这样刚好就可以在范围互不重复的情况下,用 4 个字节表示一个字符了。
这种用 4 个字节表示的方式,就被称作「代理对」(Surrogate Pair),高位的 10 bit 被称为「前导代理」(lead surrogates),低位 10 bit 被称为「后尾代理」(trail surrogates)。
其具体的算法如下:
BMP 内字符,直接使用码点作为对应的字节,长度为 2 个字节。
辅助面内的字符
码位减去 0x10000高位的 10 bit 的值加上 0xD800,得到前导代理低位的 10 bit 的值加上 0xDC00,得到后尾代理
用公式计算如下
// 高位
H = Math.floor((c-0x10000) / 0x400)+0xD800
// 低位
L = (c - 0x10000) % 0x400 + 0xDC00
我们依旧使用“🐰”来举例,看下 UTF-16 是如何进行编码的
🐰:
码点为 U+1F430 减去 0x10000,为 0xF430 二进制为 1111010000110000 前 10 bit 111101,十六进制 0x3D。后 10 bit 0000110000,十六进制 0x30 分别加上 0xD800 和 0xDC00,得到 0xD83D 和 0xDC30 最终得到 D8 3D DC 30
JS 中 escape 方法(已不推荐,这里仅验证用)返回的就是 UTF-16 编码,可以进行验证
escape('🐰')
// %uD83D%uDC30
同时 ES6 中支持用 Unicode 码点和 UTF-16 编码表示一个字符,也可验证
'\u{1F430}' == '\uD83D\uDC30'
// true
由于前导代理、后尾代理、BMP 中的有效字符的码位,三者互不重叠,因此在检查字符时,可以很容易的确定字符的边界。这也意味着 UTF-16 也是一种自同步的编码方式,这点和 UTF-8 是一样的。
UTF-16 相对于 UTF-8 更容易进行随机访问和索引,是因为 UTF-16 中每个字符都使用固定的2个或4个字节表示,因此可以通过简单的数学运算来快速计算出每个字符的位置。而 UTF-8 需要解析整个数据流才能确定每个字符的位置,这使得 UTF-8 在进行随机访问和索引时比 UTF-16 更加复杂和耗时。
UCS-2
在谈及 UTF-16 时,通常会涉及到 UCS-2 的概念,这里着重讲下两者的区别。
UCS-2 是 Universal Character Set coded in 2 octets 的简称,由于 1989 年 UCS 标准发布时,只有 Unicode 基本面字符,因此使用 2 个字节就可以表示一个字符了。而 1996 年 UTF-16 发布时,已经扩展出了辅助平面,可使用代理对方式表示辅助平面的字符了,因此 UTF-16 已明确表示是 UCS-2 的超集。所以目前 UCS-2 已经是过时的叫法了,UTF-16 已经取代了 UCS-2 的概念。
如果某个程序说自己支持 UCS-2 可能就意味着仅支持 BMP 内的字符集。
大端序和小端序
将字符转换为 UTF-16(或 UTF-32) 后,在使用时需要读取并存储在内存中。以“乙”字为例,转成 UTF-16 后,编码为 0x4E59,需要用 2 个字节来存储——0x4E 0x59。
如果 4E 在前,59 在后,我们就称作为大端序(Big-Endian)
内存地址 内存值
0x00000000 4E
0x00000001 59
反之 59 在前,4E 在后,就称之为小端序(Little-Endian)
内存地址 内存值
0x00000000 59
0x00000001 4E
之所以会有这样不同的存储方式,是因为有的系统或者处理器,在处理多字节数据时,会从低位内存地址到高位内存地址的顺序读取数据,因此为了保证读取后数据的正确,就采用了不同字节序(Endianness)的方式。
为了标识一段数据的字节序,通常使用字节顺序标记 (Byte-Order Mark,BOM)来进行标识。通常 BOM 会出现在文件、字节流的头部,用来标识接下来数据的字节顺序。
在 UTF-16,0xFEFF 表示大端序,0xFFFE 表示小端序。
我们来验证下,使用 VSCode 安装 HexEditor 插件,然后新建一个空白文件,输入“乙”和“🐰”,然后分别使用两种编序,通过 HexEditor 查看。
UTF-16 BE


UTF-16 LE


另外 UTF-8 也存在 BOM 头,值为 0xEF 0xBB 0xBF。但它只用来标识文件的编码方式,而不用来说明字节顺序。因为 UTF-8 本身有着固定的编码顺序,字节序对于 UTF-8 来说毫无意义。
在实际使用中,也应该尽量避免带 BOM 头的 UTF-8,因为 BOM 头可能会影响一些程序的解析器(如 Unix下的Shebang)的处理。另外由于 UTF-8 是一种稀疏的编码,很大一部分可能的字符组合不会产生有效的 UTF-8 文本,因此许多程序的在解析 UTF-8 文件时,使用启发式的分析方法可以很有把握地检测出文件是否使用 UTF-8,而无需加入 BOM。
锟斤拷烫烫烫
“锟斤拷”和“烫烫烫”恐怕是程序界中最经典的故事(事故)之一了,了解了前面的编码知识,就会很容易理解它的由来了。

锟斤拷
由于 Unicode 字符集在不断更新中,因此会出现 A 系统发送的字符,在 B 系统中无法识别的情况。于是 Unicode 规定对于无法识别的字符,一律使用 �(0xFFFD) (Replacement character) 字符来代替。而 0xFFFD 在 UTF-8 编码下为 0xEF 0xBF 0xBD,当多 � 出现时,就会产生连续的 0xEF 0xBF 0xBD 0xEF 0xBF 0xBD。
如果这些字符又被使用了 GB 编码的程序中打开,就会按照 GB 双字节编码将其解析。这样刚好就对应了 「0xEFBF 锟」 ,「0xBDEF 斤」,「0xBFBD 拷」 这几个字。
烫烫烫
C\C++ 编译器在 debug 模式下,引入的一种内存保护机制,会给特定的内存赋一个特定的初值。其中未被初始化的栈内存,会被写入 0XCC。当连续的 0xCCCC 在 GB 编码下就是「0xCCCC 烫」了。
当然一千人眼中有一千个哈姆雷特,程序员也是如此。比如台湾是“嚙踝蕭”,而日本是“フフフフフフ”了。
JavaScript 与 Unicode
薛定谔的 length
前面我们提到 JavaScript 中 '😁'.length = 2,要说明这个问题之前,先简单介绍下 JavaScript 与编码的历史。
1990 年 UCS-2 编码发布,1995 年 JavaScript 诞生,第一个 JS 解释器被使用,1996 年 UTF-16 发布。从时间线上来看 JavaScript 解释器只能采用了 UCS-2 的编码方式。而 length 统计的是代码单元而非真正的字符数量,因此按照 UCS-2 的编码方式,每个字符由 2 个字节构成,即两个 2 字节组成字符的 length = 1。
而 😁 是辅助平面的字符,其 UTF-16 的编码为 D8 3D DE 01,因此 JavaScript 会把它当做 0xD83D 和 0xDE01 两个字符。这也就是 length = 2 的原因。
除 length 以外,JavaScript 中和字符串处理相关的函数,大都存在这类问题,如:
var s = "🐰";
s.length // 2
s.charAt(0) // '\uD83D'
s.charAt(1) // '\uDC30'
s.charCodeAt(0) // 55357
s.charCodeAt(1) // 56368
var s = "🐰子";
s.substring(1); // '\uDC30子'
s.slice(1); // '\uDC30子'
/^.$/.test('🐰') // false
ES6 的字符处理
但在 ES6 中,大大增强了对 Unicode 的支持,提供了新的方法解决了以上问题。
为了保持兼容,length 属性还是原来的行为方式。为了得到字符串的正确长度,可以采用如下的方式
[...str].length;
// or
Array.from(str).length
原 Unicode 表示字符法,仅支持 \uxxxx的表示,仅支持\u0000-\uffff范围。如:“兔”也可以用\u5154表示
var a = '\u5154';
a == '兔' // true
而超出 \uffff 的部分需要使用双字节方式表示,如:“🐰”需要用 \uD83D\uDC30 表示,而不能用码位值 \u1F430 表示
var a = ' \uD83D\uDC30';
a == '🐰' // true
var a = '\u1F430';
// 'ὃ0'
而在 ES6 中只要将码点放入 {} 中,即可正确表示其含义
var a = '\u{1F430}';
// 🐰
ES6 新增了几个专门处理 4 字节码点的函数,如:
String.fromCodePoint():从 Unicode 码点返回对应字符 String.prototype.codePointAt():从字符返回对应的码点 String.prototype.at():返回字符串给定位置的字符 ES6 正则提供了 u 修饰符,对正则表达式添加 4 字节码点的支持。
// '\u{1F430}'
/^.$/.test('🐰'); // false
/^.$/u.test('🐰'); // true
var s = '\u0065\u0323\u0301'; // 'ẹ́'
/^.$/.test(s); // false
/^.$/u.test(s); // false
length 依旧不准的合成字符
上面解释了为什么 length=2,是否意味着 length 非 1 即 2 呢?别急,我们运行下 '👨👩👧👦'.length

居然 length=11,为什么整整齐齐的一家人要这么长?这到底发生了什么?
要解释这个问题,就要讲到 Unicode 的**合成字符** (combining character)。
在一些语言中,会在字符的上面添加一些符号,以表示不同的发音或表示不同的含义。例如:汉语拼音有 ā 的音标、ü 上面的两点,法语和西班牙语中的 é 表示重音,越南国语字中的 Ô 表示一个字母。
而在 Unicode 中有两种表示方法
使用一个独立的码点,例如 Ô 的码点为 U+00D4。 使用基本字符+**附加符号**组合的方式,如 O 的码点是 U+004F,扬抑符 ˆ 的码点是 U+0302,组合后同样展示 Ô,其表意与第一种相同。
'\u00d4'
// Ô
'\u004f\u0302'
// Ô
这两种方式表示虽然在视觉和语义上含义相同,但是在 js 中却无法理解
'\u004f\u0302' == '\u00d4'
// false
因此在 ES6 中提供了 String.prototype.normalize(),用来将字符的不同表示方法统一为同样的形式,称为 Unicode 正规化(该方法有局限性,后文会讲)。
'\u004f\u0302'.normalize() == '\u00d4'
// true
'\u004f\u0302'.normalize().codePointAt(0).toString(16)
// 'd4'
那么回到 '👨👩👧👦'.length 问题上来,这个 emoji 就使用了合成符号表示(这个表情没有单独的码点),其组合是由 7 个 Unicode 组合而成,分别是 ['👨', '', '👩', '', '👧', '', '👦'], 使用了 U+ 200D 零宽连字符(Zero-Width Joiner,ZWJ)将四个 emoji 链接。
这类表情也被称为 Emoji ZWJ Sequences 。

而 👨 👩 👧 👦 的 length 分别为 2,而零宽连字符的 length 为 1,因此最终 length 就是 24 + 31 = 11。
通过下面的方式也可以验证其组合
[...'👨👩👧👦']
// ['👨', '', '👩', '', '👧', '', '👦']
'\u{1F468}\u{200D}\u{1F469}\u200D\u{1F467}\u200D\u{1F466}'
// 👨👩👧👦
当然这里想通过 normalize() 判断是否等价是不行的,首先 👨👩👧👦 没有独立的码点, 其次该方法目前不能识别三个或三个以上字符的合成。
[...'👨👩👧👦'.normalize()];
// ['👨', '', '👩', '', '👧', '', '👦']
// '\u0065\u0323\u0301' => 'ẹ́'
[...'ẹ́'.normalize()]
// ['ẹ', '́']
合成字符的大麻烦
上面提到关于 Unicode 的问题不仅限于 JavaScript,在 Python、Java 等语言中也会遇到。通常这类合成符号在实际开发中会造成很多棘手的问题。
input 的 maxlength
在设置 input 的 maxLength 属性时,就会遇到不同浏览器的差异。
<input maxlength="10">
Chrome 将 👨👩👧👦 粘贴后,会按照 String.prototype.length 进行裁剪,多出的字符会被裁剪掉
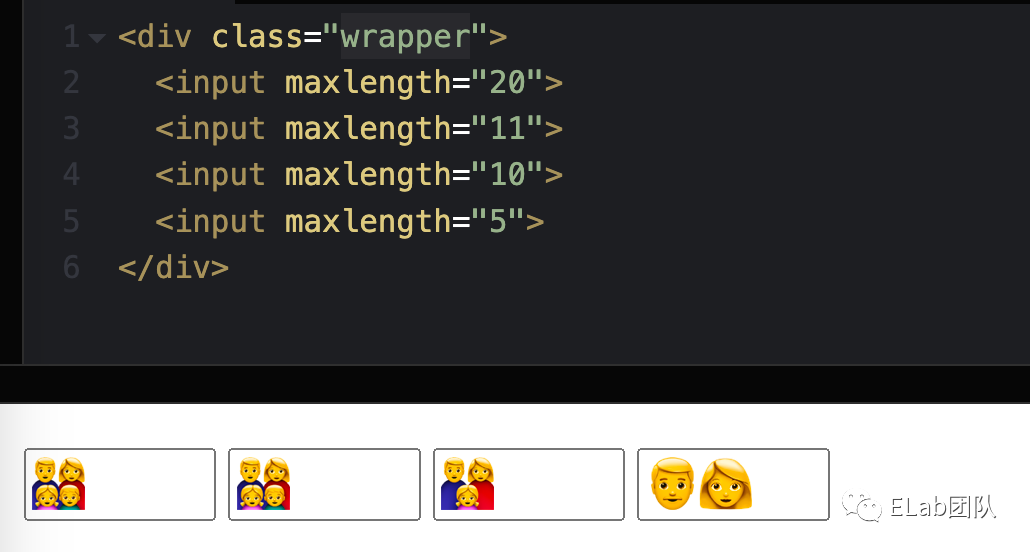
例子在这里
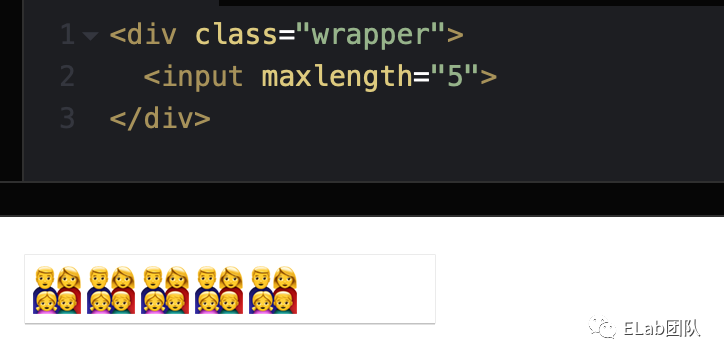
Safari(PC 16.3+Moblie)则会按照实际字符个数计算
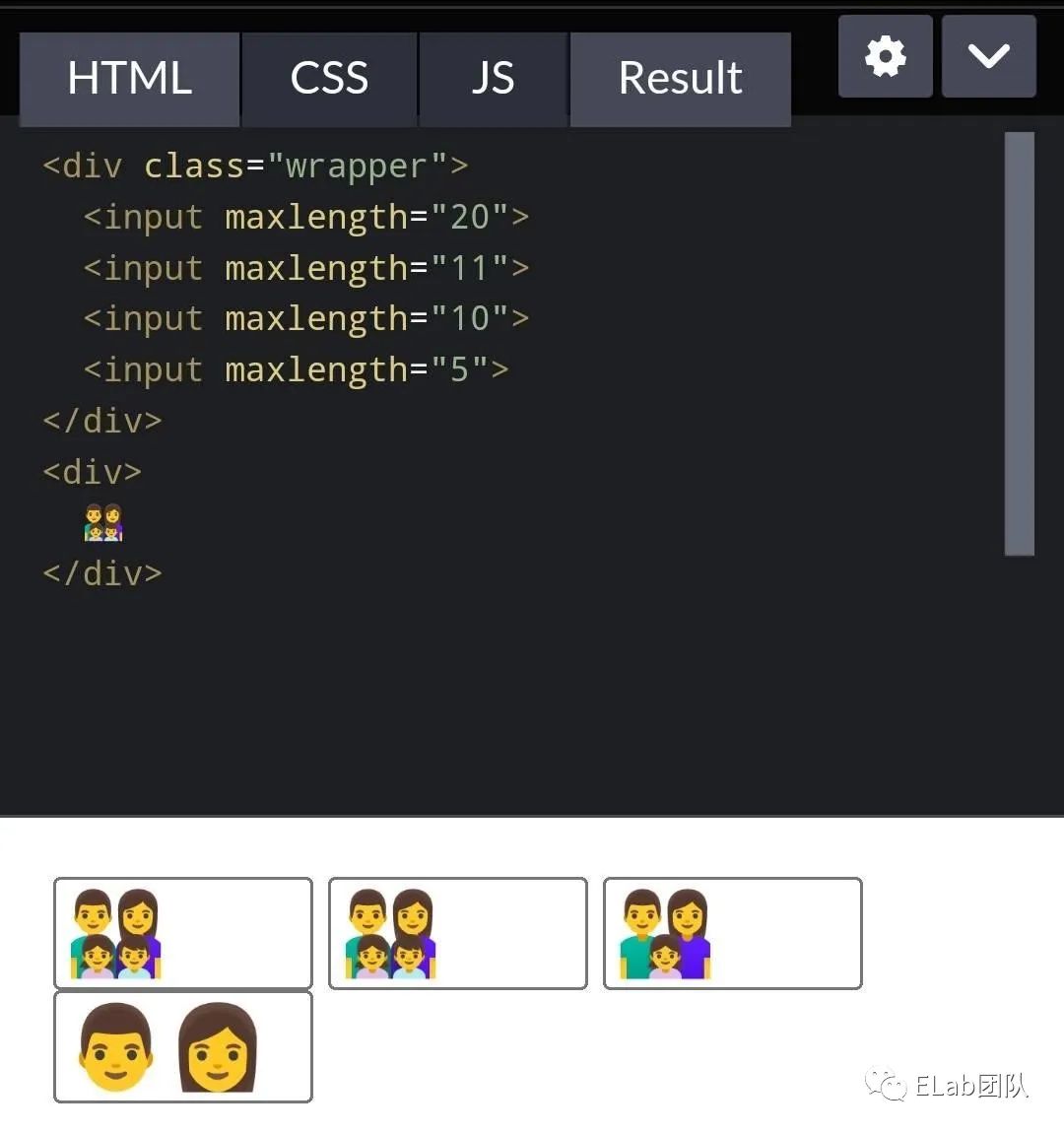
在华为默认的浏览器测试,行为和 Chrome 的相同
该问题在开发多语言业务中,可能会更加明显(如后台的字符数限制、前端展示等)。如果希望正确计算需要使用三方库,例如:https://github.com/orling/grapheme-splitter (抛砖引玉,未验证覆盖情况)。
带音标的文字
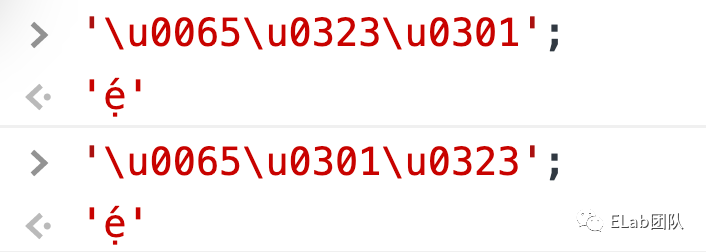
在一些场景下,会有多个附加音标修饰一个字符的情况。例如 'ẹ́' 是由字母“e” \u0065、尖音符 “◌́” ****\u0301 、 下句点 ****“◌̣” \u0323 ****组成。其中后两个音标的顺序可互换, 甚至也可以是 'ẹ' + '́' 或者 'é' + '̣' 的组合。
'\u0065\u0301\u0323'; // ẹ́
'\u0065\u0323\u0301'; // ẹ́
'\u1eb9\u0301'; // 'ẹ' + '́'
'\u00e9\u0323'; // 'é' + '̣'

这时要使用正则匹配字符变得异常复杂。虽然 Unicode 属性转义表达式(Unicode property escapes),但可惜的是ES2018 以前的版本并不支持,因此可以考虑使用 XRegExp 来实现。
// 例子在这里
var reg = XRegExp('\pL\pM*', 'g');
XRegExp.match('ẹ́', reg);
// ["ẹ́"]
其中 \pL 和 \pM 的含义如下:
\p{L} or \p{Letter}: any kind of letter from any language,匹配一个字母 \p{M} or \p{Mark}: a character intended to be combined with another character (e.g. accents, umlauts, enclosing boxes, etc.). 匹配附加符号
虽然在 ES2018 中引入了 Unicode 属性转义符,但在浏览端上依然要考虑使用 XRegExp 来实现,当然可以考虑在服务端处理,因为 Python 3.6、Perl 5.24 、Ruby 2.4 、.NET 4.6、Go 10 等已经支持这些表达式了,当然不同语言的支持程度可能略有不同。
数据库中存储表情
另外在数据库存储时使用了不同的表示方式存储同一含义的字符,会导致检索失败。MySQL 存储时也要考虑使用 utf8mb4_unicode 编码格式,才能正确存储表情符。
总结
最后关于 Unicode 字符编码模型,可以概况为四个层级:
抽象字符库(ACR, Abstract Character Repertoire):即要编码的字符,比如某些字母表和符号集。这一层级会将语言中的字符进行抽象。 编码字符集(CCS, Coded Character Set):从抽象字符库到一组非负整数(即代码点)的映射。这一层级可以理解为字符到 Unicode 码点映射的过程。 字符编码形式(CEF, Character Encoding Form):从代码点到特定宽度(比如32-bit整数)的代码单元序列的映射。这一层级理解为 UTF-8、UTF-16、UTF-32 的编码过程。 字符编码方案(CES, Character Encoding Scheme):从代码单元序列到字节序列的映射。这一层级就涉及到了如大端序、小端序的设计和存取过程。

往期推荐


最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...

参考资料
https://zh.wikipedia.org/wiki/ASCII https://zh.wikipedia.org/wiki/EASCII https://zh.wikipedia.org/wiki/ISO/IEC_8859 https://zh.wikipedia.org/wiki/GB_2312#cite_note-1 https://web.archive.org/web/20090719012802/http://www.knowsky.com/resource/gb2312tbl.htm https://zh.wikipedia.org/wiki/Unicode https://www.unicode.org/glossary/#code_point https://www.ruanyifeng.com/blog/2014/12/unicode.html https://en.wikipedia.org/wiki/UTF-8 https://www.unicode.org/charts/ https://www.zhihu.com/question/23374078 https://zhuanlan.zhihu.com/p/260192496 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html https://zh.wikipedia.org/wiki/UTF-16 What is the difference between UCS-2 and UTF-16? https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/length https://es6.ruanyifeng.com/#docs/string https://en.wikipedia.org/wiki/Byte_order_mark https://en.wikipedia.org/wiki/Combining_character https://withblue.ink/2019/03/11/why-you-need-to-normalize-unicode-strings.html https://unicode.org/emoji/charts/emoji-zwj-sequences.html https://en.wikipedia.org/wiki/Zero-width_joiner https://dmitripavlutin.com/what-every-javascript-developer-should-know-about-unicode/ https://github.com/slevithan/xregexp https://stackoverflow.com/questions/17357716/javascript-regex-unicode-diacritic-combining-characters https://www.regular-expressions.info/unicode.html#prop https://github.com/anjia/blog/issues/86