没有这些,别妄谈做ChatGPT了

大数据文摘授权转载自夕小瑶的卖萌屋
文|卖萌酱
ChatGPT破圈爆火后,越来越多人开始问:
“啥时候出现中国版的ChatGPT?”
国内学术界和工业界,都纷纷躁动起来——百度、阿里、字节等大厂纷纷喊口号,一众创业公司也开始争做中国版OpenAI;学术界也在用行动来表明战斗力,比如前些天复旦大学推出的MOSS模型,一经开放试用,便冲上热搜。
一时间眼花缭乱,让人生疑。
有钱就能训出模型?
以美团大佬带资入组为代表,很多创业者和投资人盯上了ChatGPT,作为一个NPLer,我乐见其成,相信不用几个月,在热钱的助推下,NLP算法工程师的薪资要和芯片看齐了。
但我还是要泼个冷水,创业公司想做ChatGPT,想训练模型,不是有钱招几个算法就能搞定的。
先不说ChatGPT,只说较为成熟、参数量“较小”的BERT模型,其 Large版本参数量“仅有”3.4亿,比现在的ChatGPT模型足足小了3个数量级。但如果一个从业者真正从0开始训练过BERT模型,那他一定不会认为训练BERT这个“小模型”是很容易的事情。

更何况,2018年BERT发布的时候,模型参数、训练代码是全面开源的,训练数据BookCorpus和Wikipedia也非常容易获取。在这种情况下,国内各大厂训练出内部版本的BERT模型,也经历了差不多半年的摸索时间。在此期间,算力就位、训练精度优化、训练性能优化、底层框架支持、训练策略优化、数据策略优化等都有不少的坑要趟。
如今ChatGPT既没有公开代码,也没有公开训练数据,更没有公开模型参数,甚至都没有公开前置模型的模型参数,模型的体量还比BERT大了3个数量级。
ChatGPT没有捷径
相对创业团队,中国的互联网大厂在大模型方向有积累,有先发优势,但这绝不意味着高枕无忧。
在语言模型方面,国内各大厂大多沿着“以掩码语言模型MLM为核心的BERT路线”进行深耕,这种技术路线更加注重提升语言模型的文本理解能力,弱化文本生成能力。真正沿着ChatGPT这种生成式语言模型的路线深耕的研究团队,无论国内外,都不是太多。
这就注定了,ChatGPT的复现不是一朝一夕就能完成的,补功课很可能要从三年前OpenAI发布的GPT-3开始。如果没有GPT-3提供的世界知识和强大的长文本生成能力,训练ChatGPT就无异于建造空中楼阁了。

可惜,GPT-3至今也没有开源,未来也大概率不会开源了。要从头训这么一个1750亿参数的大型生成式语言模型,难度非常大。
有人可能要说,那我们训一个小点的模型,比如百亿参数的,可行吗?
目前来看不可行。AI的表现并非随着模型规模增加而线性增加,而是在参数规模超过特定临界值后显著提升,甚至涌现出小模型不具备的能力。 比如论文表明,模型的规模至少要达到620亿参数量后,才可能训练出来思维链(Chain-of-Thought,CoT)能力。如下图所示:
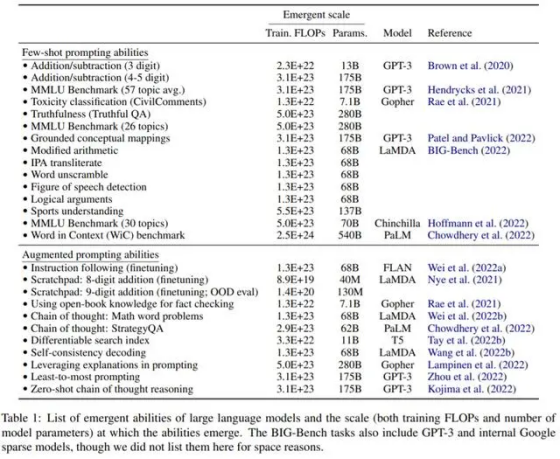
而像Truthful(可信的)这种能力,甚至ChatGPT/GPT-3这样的模型规模都是不够的,要达到2800亿参数量才能涌现出这样的能力。是的,复现和超越ChatGPT,目前来看没有捷径,必须一步一步来,首先要先把GPT-3搞定。
国内有人真正复刻了GPT-3?
是的,有且只有一家,阿里达摩院,他们从小到大(从base到175B),全面、完整地复刻了GPT-3,并且开放在魔搭社区上。
https://modelscope.cn/models/damo/nlp_gpt3_text-generation_chinese-large/summary
达摩院的复刻不是没有来由的,他们应该在大模型各个方向都进行了探索,布局完整。早在2021年4月就发布了首个中文语言大模型PLUG(当时参数是270亿)。该模型首次在中文语言理解榜单CLUE上面,以86.685分的成绩超越人类。
同年10月份,达摩院还探索实现了10万亿参数模型——M6,达摩院团队通过大量的底层优化和算法设计,仅仅使用了512卡便实现了这一庞大的模型工程。此前,M6模型将AI图片生成清晰度从OpenAI DALL·E的256×256成功提升到了1024×1024,效果十分惊艳。
M6模型的发布引发了国内外的大量关注,其中,OpenAI前政策主管Jack Clark公开点评:“这个模型的规模和设计都非常惊人。这看起来像是众多中国的AI研究组织逐渐发展壮大的一种表现。”
从达摩院的经历我们基本可以判断:如果一个研发团队此前没有训练过千亿级别的大型语言模型,那就很难在可以接受的时间窗口内训练出真正具备生产力价值的类ChatGPT模型。
不过,我们也要看到,
云基础设施
OpenAI的解决方式是向微软求助。同样的道理,国内如果有初创企业想要成为中国版OpenAI,自研ChatGPT,恐怕也要先跟几个云计算厂商好好聊一聊了。
没有做过大模型训练的人,可能会误以为多买几张A100卡就可以了。
当你实操的时候,你就会发现:
单机多卡根本训不动千亿参数模型,你需要多机多卡分布式训练 当你开始多机训练时,你发现A100的算力都被网络通信延迟给吃掉了,多机可能还没有你单机训的快 然后你会发现训练ChatGPT的海量数据存储也是个问题,就算存下来了,数据读取的IO效率又极大的制约了模型的训练效率 一通基础设施问题下来,A100的算力被浪费了7、8成,模型训练实验无法开展
怎么把计算,存储,网络,从物理资源变成虚拟的概念,“批发转零售”; 如何在这种虚拟环境下把利用率做上去,或者说超卖; 怎么更加容易地部署软件,做复杂软件的免运维(比如说,容灾、高可用)等等,不一而足。
并不要求特别强的虚拟化。一般训练会“独占”物理机,除了简单的例如建立虚拟网络并且转发包之外,并没有太强的虚拟化需求。 需要很高性能和带宽的存储和网络。例如,网络经常需要几百 G 以上的 RDMA 带宽连接,而不是常见的云服务器几 G 到几十 G 的带宽。 对于高可用并没有很强的要求,因为本身很多离线计算的任务,不涉及到容灾等问题。 没有过度复杂的调度和机器级别的容灾。因为机器本身的故障率并不很高(否则 GPU 运维团队就该去看了),同时训练本身经常以分钟级别来做 checkpointing,在有故障的时候可以重启整个任务从前一个 checkpoint 恢复。 也就是说,对于 AI 训练而言,尤其是今天那么大规模的训练,性能和规模是第一位的,传统云服务所涉及到的一些能力,是第二位的。
作为NLPer,我能深刻的感受到,自从2020年GPT-3模型发布后,AI的研究生态正变得愈加封闭。虽然这对于已经取得竞争优势的商业化公司而言是利好,但对全人类实现AGI的终极梦想而言,却是一个不好的文化趋势。
客观上,我们需要承认与OpenAI的差距,正因如此,倘若有一个更加开放的大模型生态,使得能有更多的AI研究人员避免“重复造轮子”,那国内“ChatGPT复现”的进程无疑会大大加快。
一枝独放不是春。