
一道头条面试题:如何设计哈希函数并解决冲突问题
引言
本节由一道头条面试题:如何设计哈希函数以及如何解决冲突问题展开,由以下几个方面进行循序渐进的阐述:
- 什么是散列表?
- 什么是散列函数?
- 常见的散列函数有哪些?
- 冲突又怎么解决喃?
- 散列表的动态扩容
- 解答
- +面试题
一、散列表(哈希表、Hash 表)
不同与之前我们介绍的线性表,所有的数据都是顺序存储,当我们需要在线性表中查找某一数据时,当线性表过长,需要查找的数据排序比较靠后的话,就需要花费大量的时间,导致查找性能较差。
例如学号,如果你想通过学号去找某一名学生,假设有 n 学生,难道你要一个一个的找,这时间复杂度就为 O(n),效率太低。当然你也可以使用二分查找算法,那时间复杂度就为 O(logn),有没有更高效的解决方案喃?
我们知道数组通过下标查找的时间复杂度为 O(1),如果我们将学号存储在数组里,那就简单多了,我们可以直接通过下标(key)找到对应的学生。
但日常生活中,key 一般都赋予特定的含义,使用 0,1,2 ... 太过简单了。学号通常都需要加上年级、班级等信息,学号为 010121 代表 1年级,1 班,21号。我们知道某一同学的学号就可以直接找到对应的学生。
这就是散列! 通过给定的学号,去访问一种转换算法(将学号010121转换为1年级,1 班,21号的方法),得到对应的学生所在地址(1年级,1 班,21号)。
其中这种转换算法称为散列函数(哈希函数、Hash 函数),给定的 key 称为关键字,关键字通过散列函数计算出来的值则称为散列值(哈希值、Hash 值)。通过散列值到 散列表(哈希表、Hash 表)中就可以获取检索值。
如下图:
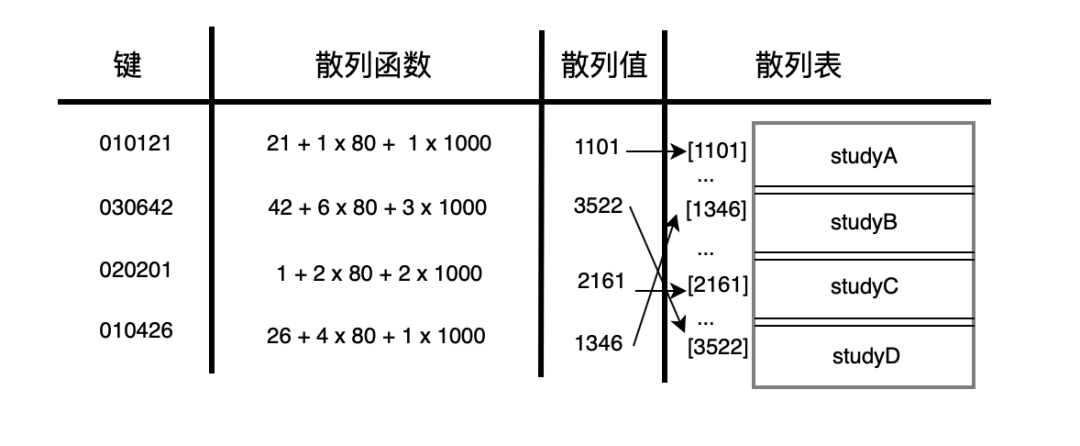
也可以说,散列函数的作用就是给定一个键值,然后返回值在表中的地址。
// 散列表
function HashTable() {
let table = []
this.put = function(key, value) {}
this.get = function(key) {}
this.remove = function(key) {}
}
继续看上面学号的例子,每个学生对应一个学号,如果学生较多,假如有 10w 个,那我们需要存储的就有
- 10w 个学号,每个学号 6 个十进制数,一个十进制数用 4 bit 表示(1个字节=8bit)
- 散列函数
- 10w 个学生信息
这就需要多花 100000 * 6 / 2 / 1024 = 292.97 KB 的存储容量用于存储每个学生的学号,所以,散列表是一种空间换时间的存储结构,是在算法中提升效率的一种比较常用的方式,但是所需空间太大也会让人头疼,所以通常需要在二者之间权衡。
二、散列函数
这里,需要了解的是,构造散列函数应遵循的 原则 是:
- 散列值(value)是一个非负数:常见的学号、内存寻址呀,都要求散列值不可能是负数
- key 值相同,通过散列函数计算出来的散列值(value)一定相同
- key 值不同,通过散列函数计算出来的散列值(value)不一定不相同
再看一个例子:学校最近要盖一个图书馆,用于学生自习,如果给每位学生提供单独的小桌子的话,就需要 10w 张,这显然是不可能的,那么,有没有办法在得到 O(1) 的查找效率的同时、又不付出太大的空间代价呢?
散列函数就提供了这种解决方案,10w 是多,但如果我们除以 100 喃,那就 0~999,这就很好找了,也不需要那么多桌子了。
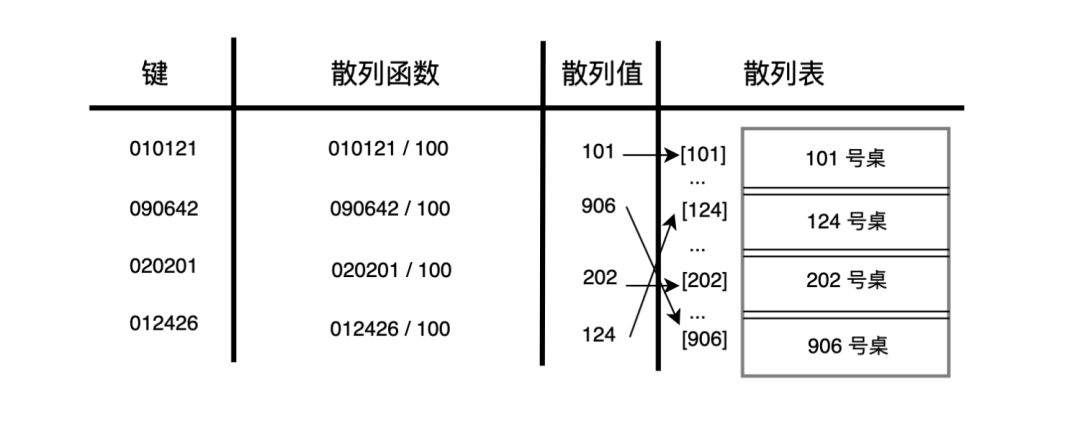
对应的散列函数就是:
function hashTables(key) {
return Math.floor(key / 100)
}
但在实际开发应用中,场景不可能这么简单,实现散列函数的方式也可能有很多种,例如上例,散列函数也可以是:
function hashTables(key) {
return key >= 1000 ? 999 : key
}
这个实现的散列函数相对于上一个在 999 号桌的冲突概率就高得多,所以,选择一个表现良好的散列函数就至关重要
1. 创建更好的散列函数
一个表现良好的散列函数可以大量的提高我们代码的性能,它有更快的查找、插入、删除等操作,更少的冲突,占用更小的存储空间。所以构建一个高性能的散列函数对我们至关重要。
一个好的散列函数需要具有以下基本要求:
- 易于计算:它应该易于计算,并且不能成为算法本身。
- 统一分布:它应该在哈希表中提供统一分布,不应导致群集。
- 较少的冲突:当元素对映射到相同的哈希值时发生冲突。应该避免这些。
2. 常见的散列函数
- 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。
- 数字分析法:通过对数据的分析,发现数据中冲突较少的部分,并构造散列地址。例如同学们的学号,通常同一届学生的学号,其中前面的部分差别不太大,所以用后面的部分来构造散列地址。
- 平方取中法:当无法确定关键字里哪几位的分布相对比较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为散列地址。这是因为:计算平方之后的中间几位和关键字中的每一位都相关,所以不同的关键字会以较高的概率产生不同的散列地址。
- 取随机数法:使用一个随机函数,取关键字的随机值作为散列地址,这种方式通常用于关键字长度不同的场合。
- 除留取余法:取关键字被某个不大于散列表的表长 n 的数 m 除后所得的余数 p 为散列地址。这种方式也可以在用过其他方法后再使用。该函数对 m 的选择很重要,一般取素数或者直接用 n。
注意:无论散列函数有多健壮,都必然会发生冲突。因此,为了保持哈希表的性能,通过各种冲突解决技术来管理冲突是很重要的。
例如上例会存在一个问题,学号为 011111 与 021111 的学生,他们除以 100 后都是 111 ,这就冲突了。
三、冲突解决
在散列里,冲突是不可避免的。那怎样解决冲突喃?
常见的解决冲突方法有几个:
- 开放地址法(也叫开放寻址法):实际上就是当需要存储值时,对Key哈希之后,发现这个地址已经有值了,这时该怎么办?不能放在这个地址,不然之前的映射会被覆盖。这时对计算出来的地址进行一个探测再哈希,比如往后移动一个地址,如果没人占用,就用这个地址。如果超过最大长度,则可以对总长度取余。这里移动的地址是产生冲突时的增列序量。
- 链地址法:链地址法其实就是对Key通过哈希之后落在同一个地址上的值,做一个链表。其实在很多高级语言的实现当中,也是使用这种方式处理冲突的,我们会在后面着重学习这种方式。
- 再哈希法:在产生冲突之后,使用关键字的其他部分继续计算地址,如果还是有冲突,则继续使用其他部分再计算地址。这种方式的缺点是时间增加了。
- 建立一个公共溢出区:这种方式是建立一个公共溢出区,当地址存在冲突时,把新的地址放在公共溢出区里。
我们这里介绍两个最简单的:开放寻址法里的线性探测,以及链地址法。
1. 线性探测
线性探测是开放寻址里最简单的方法,当往散列表中增加一个新的元素值时,如果索引为 index 的位置已经被占用了,那么就尝试 index + 1 的位置,如果 index + 1 的位置也被占用了,那就尝试 index + 2 的位置,以此类推,如果尝试到表尾也没找到空闲位置,则从表头开始,继续尝试,直到放入散列表中。
如下图:
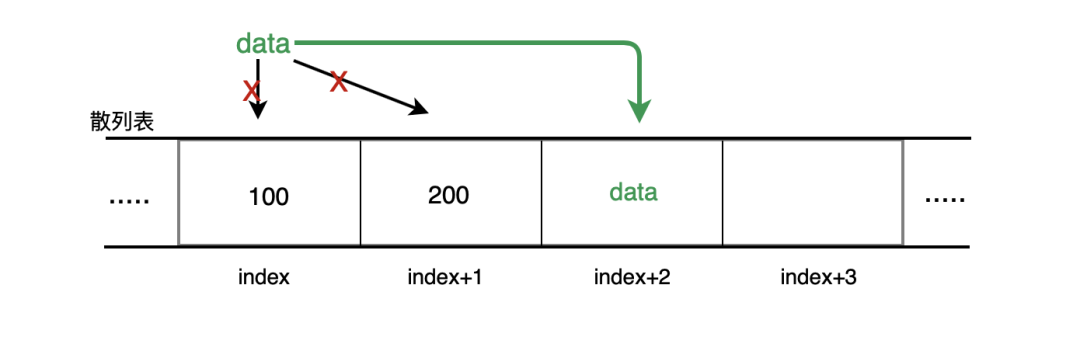
如果是删除喃:首先排查由散列函数计算得出的散列值,与要查找的散列值对比,相同则删除元素,如果该节点为空了,则设为 undefined ,不相等则继续比较 index + 1 ,以此类推,直到相等或遍历完整个散列表。
如果是查找喃:首先排查由散列函数计算得出的散列值,与要查找的散列值对比是否相等,相等则查找完成,不相等继续排查 index + 1 ,直到遇到空闲节点( undefined 节点忽略不计),则返回查找失败,散列表中没有查找值。
很简单,但它也有自己的局限性,当散列表中元素越来越多时,冲突的几率就越来越大。
最坏情况下的时间复杂度为 O(n)。
2. 链地址法
链地址也很简单,它给每一个散列表中的节点建立一个链表,关键字 key 通过散列函数转换为散列值,找到散列表中对应的节点时,放入对应链表中即可。
如下图:
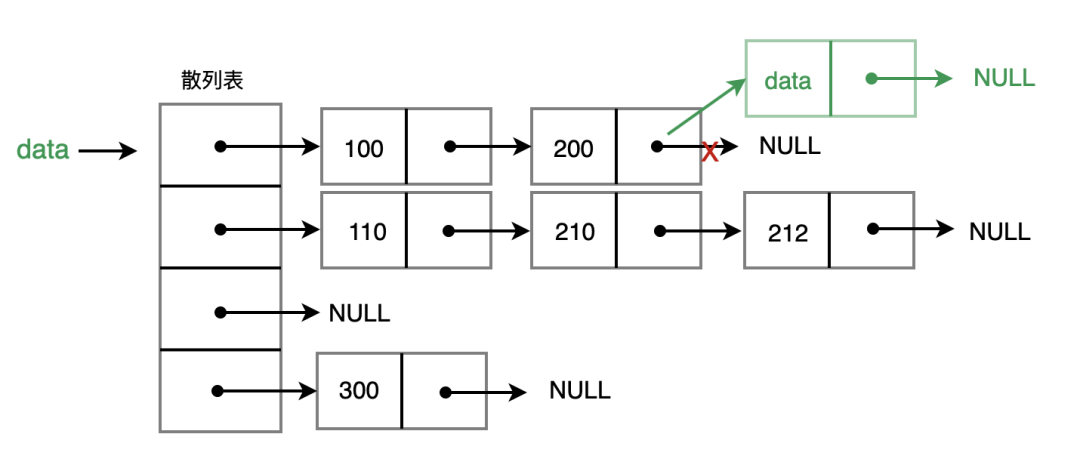
插入:像对应的链表中插入一条数据,时间复杂度为 O(1)
查找或删除:从链头开始,查找、删除的时间复杂度为 O(k),k为链表的长度
四、动态扩容
前面在介绍数组的时候,我们已经介绍过扩容,在 JavaScript 中,当数组 push 一个数据时,如果数组容量不足,则 JavaScript 会动态扩容,新容量为老的容量的 1.5 倍加上 16。
在散列表中,随着散列值不断的加入散列表中,散列表中数据越来越慢,冲突的几率越来越大,查找、插入、删除等操作的时间复杂度越来越高,散列表也需要不断的动态扩容。
五、回答开头问题
如何设计哈希函数以及如何解决冲突,这是哈希表考察的重要问题。
如何设计哈希函数?
一个好的散列函数需要具有以下基本要求:
- 易于计算:它应该易于计算,并且不能成为算法本身。
- 统一分布:它应该在哈希表中提供统一分布,不应导致群集。
- 较少的冲突:当元素对映射到相同的哈希值时发生冲突。应该避免这些。
如何解决冲突?
常见的解决冲突方法有几个:
- 开放地址法(也叫开放寻址法):实际上就是当需要存储值时,对Key哈希之后,发现这个地址已经有值了,这时该怎么办?不能放在这个地址,不然之前的映射会被覆盖。这时对计算出来的地址进行一个探测再哈希,比如往后移动一个地址,如果没人占用,就用这个地址。如果超过最大长度,则可以对总长度取余。这里移动的地址是产生冲突时的增列序量。
- 链地址法:链地址法其实就是对Key通过哈希之后落在同一个地址上的值,做一个链表。其实在很多高级语言的实现当中,也是使用这种方式处理冲突的,我们会在后面着重学习这种方式。
- 再哈希法:在产生冲突之后,使用关键字的其他部分继续计算地址,如果还是有冲突,则继续使用其他部分再计算地址。这种方式的缺点是时间增加了。
- 建立一个公共溢出区:这种方式是建立一个公共溢出区,当地址存在冲突时,把新的地址放在公共溢出区里。
六、常见的哈希表问题
我们已经刷过的(https://github.com/sisterAn/JavaScript-Algorithms):
- 腾讯&leetcode349:给定两个数组,编写一个函数来计算它们的交集
- 字节&leetcode1:两数之和
- 腾讯&leetcode15:三数之和
今天刷一道 leetcode380:常数时间插入、删除和获取随机元素
leetcode380:常数时间插入、删除和获取随机元素
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构。
insert(val):当元素 val 不存在时,向集合中插入该项。remove(val):元素 val 存在时,从集合中移除该项。getRandom:随机返回现有集合中的一项。每个元素应该有 相同的概率 被返回。
示例 :
// 初始化一个空的集合。
RandomizedSet randomSet = new RandomizedSet();
// 向集合中插入 1 。返回 true 表示 1 被成功地插入。
randomSet.insert(1);
// 返回 false ,表示集合中不存在 2 。
randomSet.remove(2);
// 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。
randomSet.insert(2);
// getRandom 应随机返回 1 或 2 。
randomSet.getRandom();
// 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。
randomSet.remove(1);
// 2 已在集合中,所以返回 false 。
randomSet.insert(2);
// 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
randomSet.getRandom();
欢迎将解答提到 https://github.com/sisterAn/JavaScript-Algorithms/issues/48 ,这里我们提交了前端所用到的算法系列文章以及题目(已解答),欢迎star,如果感觉不错,点个在看支持一下呗?
瓶子君将明日解答?
阅读❤️
欢迎关注「前端瓶子君」,回复「交流」加入前端交流群!
欢迎关注「前端瓶子君」,回复「算法」自动加入,从0到1构建完整的数据结构与算法体系!
在这里,瓶子君不仅介绍算法,还将算法与前端各个领域进行结合,包括浏览器、HTTP、V8、React、Vue源码等。
在这里,你可以每天学习一道大厂算法题(阿里、腾讯、百度、字节等等)或 leetcode,瓶子君都会在第二天解答哟!
》》面试官也在看的算法资料《《“在看转发”是最大的支持