
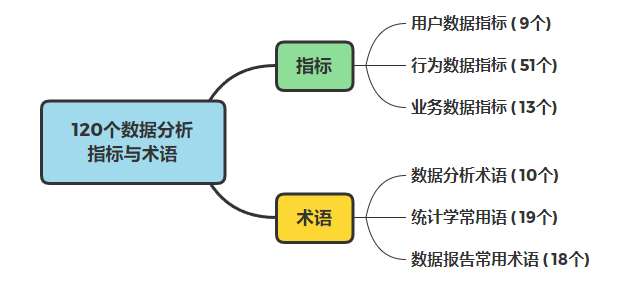
花了一周,我总结了120个数据指标与术语

导读:数据分析总是离不开各种指标和术语,最近我花了一周整理了共120个数据分析指标与术语:用户数据指标、行为数据指标、业务数据指标、数据分析术语、统计学常用语、数据报告常用术语。
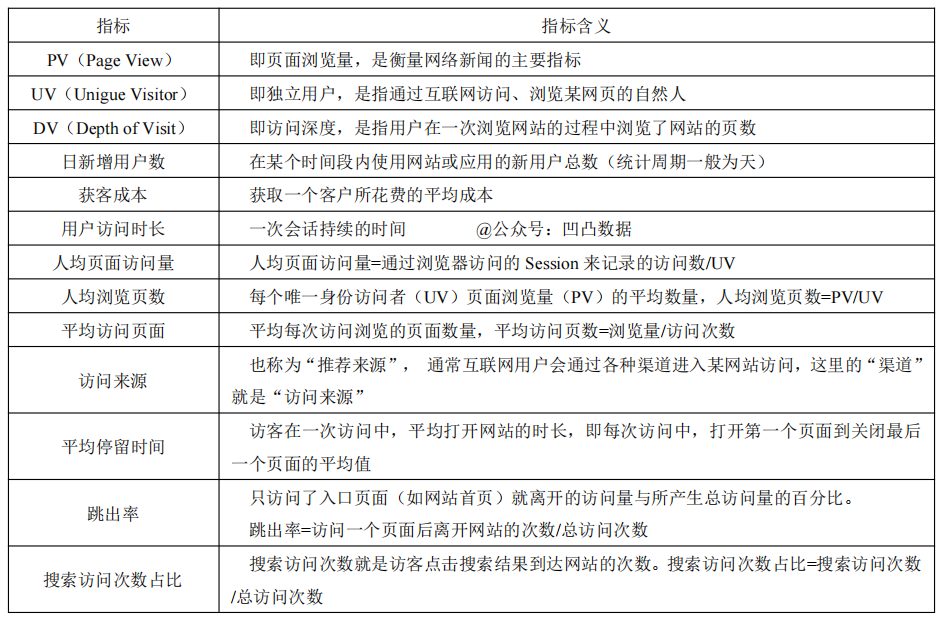
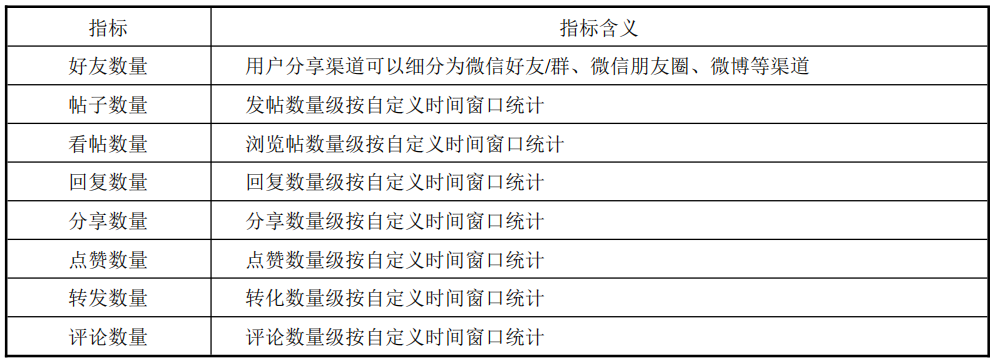
IP、UV、PV、VV
IP(Internet Protocol):独立IP数。 UV(Unique Visitor):独立访问客数。 PV(Page View):页面浏览量/阅读量。 VV(Visit View):访问次数。
注:在对视频产品的数据分析中,VV(Video View)是播放类指标,是指在一个统计周期内,视频被打开的次数之和。
DAU(Daily Active User):日活跃用户数 MAU(Monthly Active users):月活跃用户数

DNU(Day New User):日新增用户。 活跃留存率:指某日新增用户在其后N日仍启动该APP的用户数,占所选日期新增用户数的比例。

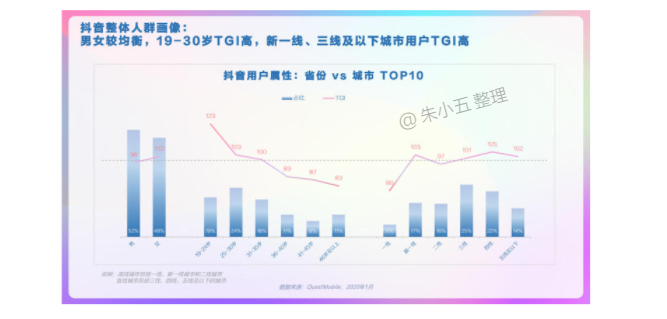
TGI(Target Group Index):目标群体指数。



ARPU(Average Revenue Per User):每用户平均收入。 ARRPU(Average Revenue Per Paying User):每付费用户平均收益。
CTR(click through rate):点击率,是衡量广告效果非常重要的一个指标:内容被点击的次数/内容展现的次数。

CVR(Click Value Rate):转化率【衡量CPA广告效果的指标】 CAC(Customer Acquisition Cost):获客成本【获取一个客户所花费的成本】 CPR(Cost Per Response):每回应成本【以浏览者的每一个回应计费】 ADPV(Advertisement Page View):载有广告的pa-geview流量 ADimp(ADimpression):单个广告的展示次数
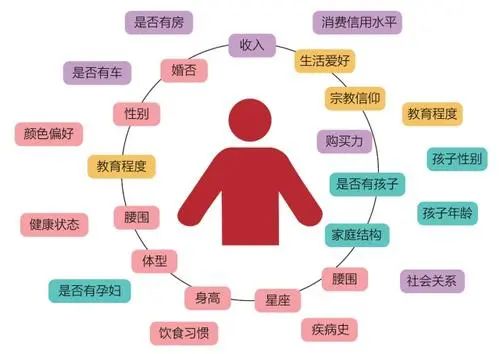
用户画像
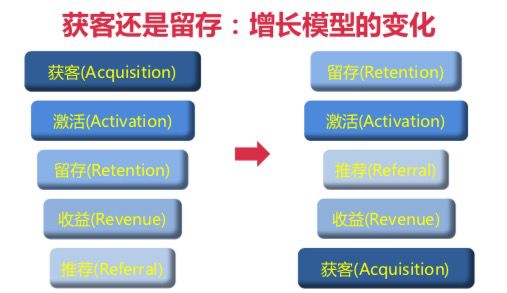
海盗模型(AARRR)
RARRA模型
OSM模型
UJM模型

RFM
ABTest

数据埋点
用户生命周期价值
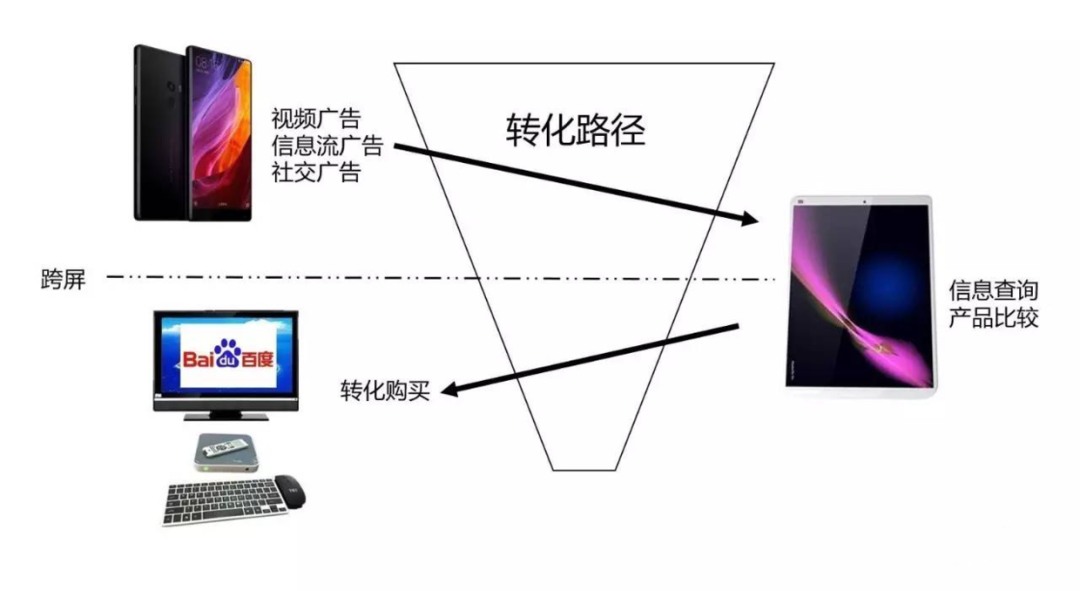
归因分析
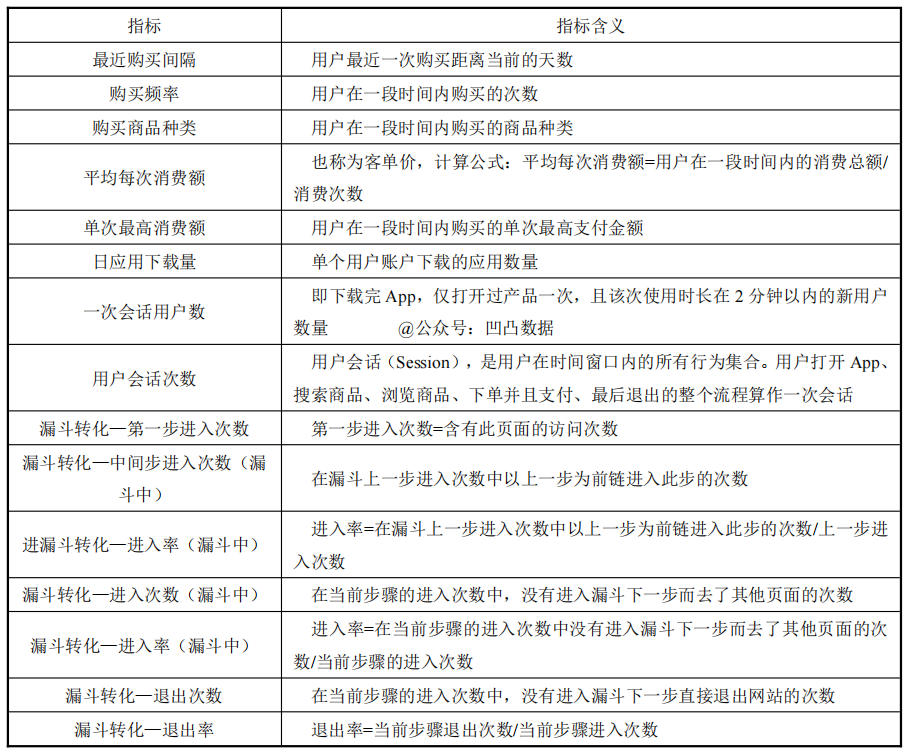
绝对数和相对数
绝对数:是反应客观现象总体在一定时间、一定地点下的总规模、总水平的综合性指标,也是数据分析中常用的指标。比如年GDP,总人口等等[4]。 相对数:是指两个有联系的指标计算而得出的数值,它是反应客观现象之间的数量联系紧密程度的综合指标。相对数一般以倍数、百分数等表示。相对数的计算公式: 相对数=比较值(比数)/基础值(基数)
百分比和百分点
百分比:是相对数中的一种,它表示一个数是另一个数的百分之几,也称为百分率或百分数。百分比的分母是100,也就是用1%作为度量单位,因此便于比较。 百分点:是指不同时期以百分数的形式表示的相对指标的变动幅度,1%等于1个百分点。
频数和频率
频数:一个数据在整体中出现的次数。 频率:某一事件发生的次数与总的事件数之比。频率通常用比例或百分数表示。
比例与比率
比例:是指在总体中各数据占总体的比重,通常反映总体的构成和比例,即部分与整体之间的关系。 比率:是样本(或总体)中各不同类别数据之间的比值,由于比率不是部分与整体之间的对比关系,因而比值可能大于1。
变量
连续变量
离散变量
定性变量
均值
中位数
缺失值
异常值
方差
标准差
皮尔森相关系数
倍数和番数
倍数:用一个数据除以另一个数据获得,倍数一般用来表示上升、增长幅度,一般不表示减少幅度。 翻n番:指原来数量的2的n次方。
同比和环比
同比:指的是与历史同时期的数据相比较而获得的比值,反应事物发展的相对性。 环比:指与上一个统计时期的值进行对比获得的值,主要反映事物的逐期发展的情况。
增量:增长的绝对量=现期量-基期量 增速:增长速度=(现期量-基期量)÷基期量 增长率:增量与基期量之比。 增幅:即增长的幅度,也可理解为增量。
基期和现期
基期:被用作参照物的时期称为基期,描述基期的量即为基期量。 现期:相对于基期的称为现期,描述现期的量即为现期量。
YTD:截止到今天为止今年的 LY:last year去年 YoY——跟上年相比 MAT(moving annual total):年度动态变化总值 Q4/Q1:4季度/1季度 GDP:国内生产总值 GNH(gross national happiness):国民幸福指数 GNP:国民生产总值
[2]通俗易懂的理解:什么是数据埋点?
[3]4个方面解析:归因分析模型
[4]一次性总结:64个数据分析常用术语!

延伸阅读👇

延伸阅读《利用Python进行数据分析》
评论