
Flink作业问题分析和调优实践
Checkpoint 机制
1.什么是 checkpoint


2.实例分析


■ CK的分析过程

■ Snapshot & Recover




■ checkpoint 的注意事项

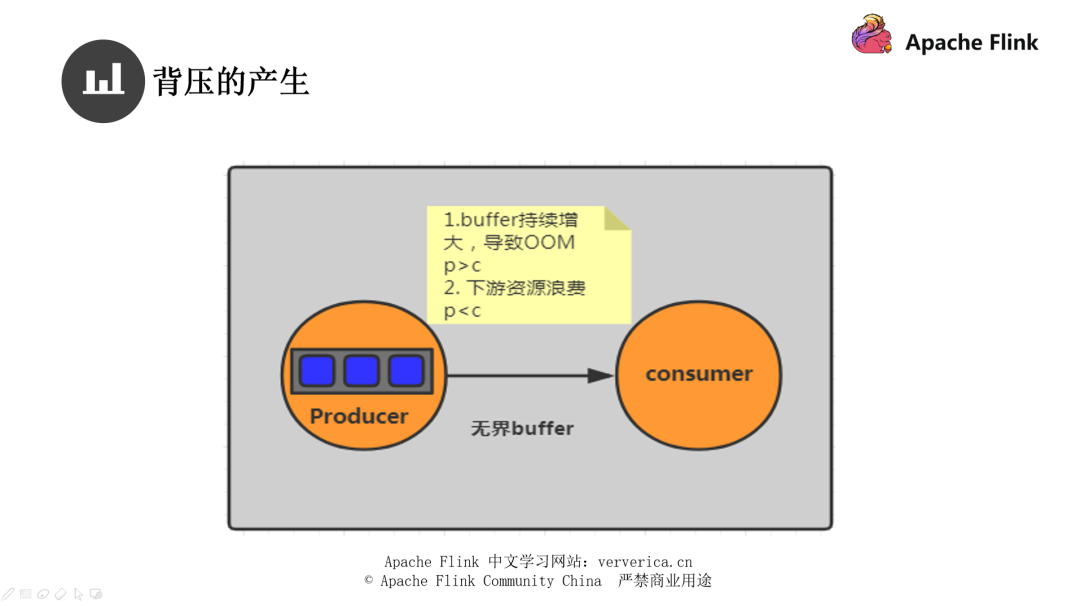
3.背压的产生及 Flink 的反压处理






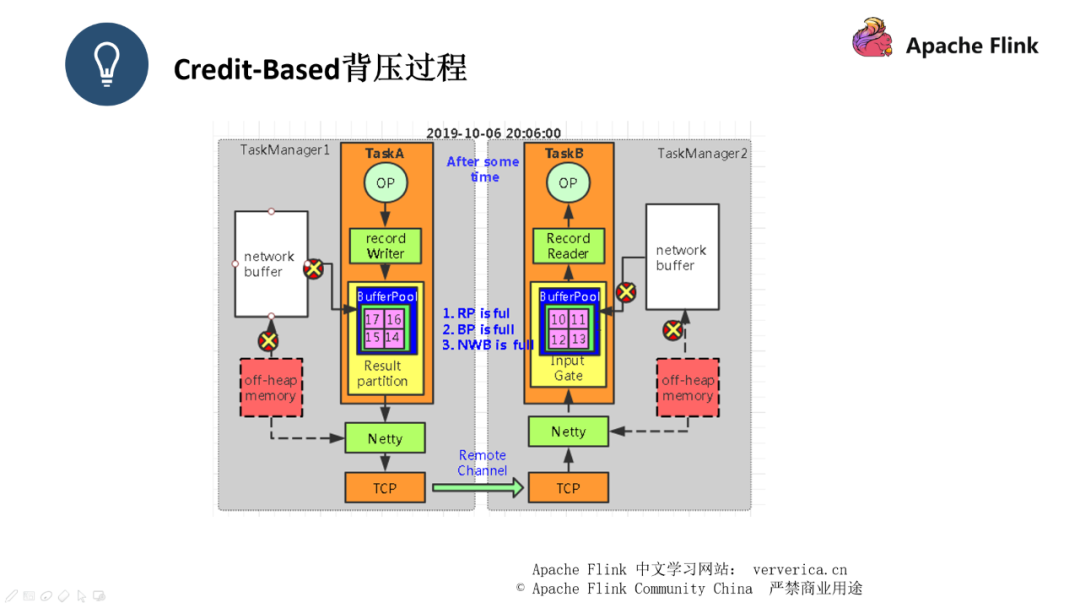
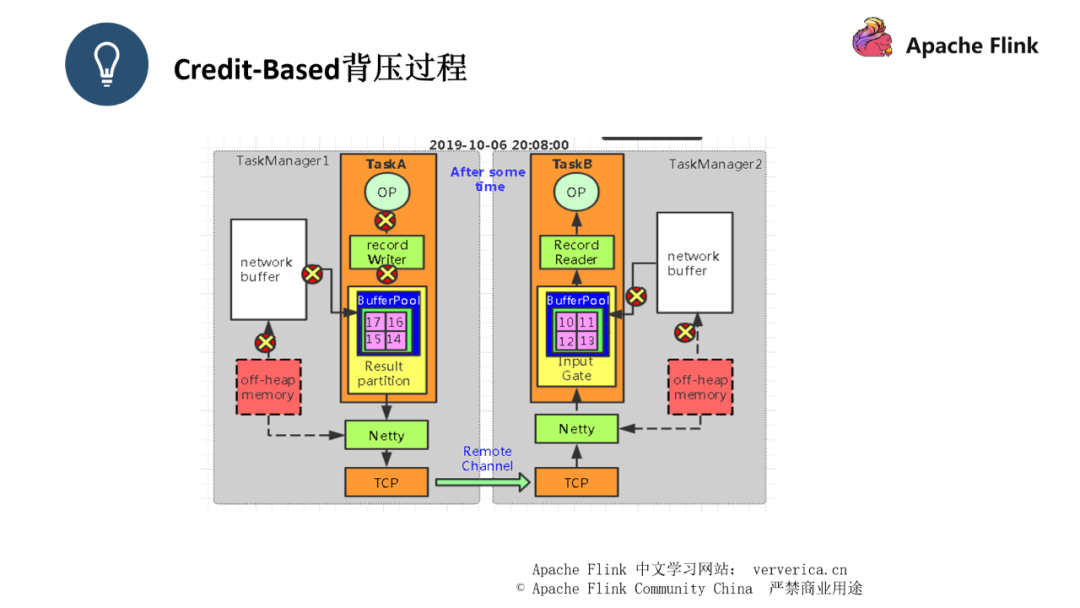
■ Credit-Based





首先是要砍掉 cutoff 的部分,默认是0.25,所以我们的可用内存就是 8gx0.75 network buffers 占用可用内存的 0.1 ,所以是 6144x0.1 堆内/堆外内存为可用内存减去 network buffers 的部分,再乘以 0.8 给到用户使用的内存就是堆内存剩下的 0.2 那部分
Flink 作业的问题定位
1.问题定位口诀
看反压:通常最后一个被压高的 subTask 的下游就是 job 的瓶颈之一。
看 Checkpoint 时长:Checkpoint 时长能在一定程度影响 job 的整体吞吐。
看核心指标:指标是对一个任务性能精准判断的依据,延迟指标和吞吐则是其中最为关键的指标。
资源的使用率:提高资源的利用率是最终的目的。
■ 常见的性能问题

在关注背压的时候大家往往忽略了数据的序列化和反序列化过程所造成的性能问题。 一些数据结构,比如 HashMap 和 HashSet 这种 key 需要经过 hash 计算的数据结构,在数据量大的时候使用 keyby 进行操作, 造成的性能影响是非常大的。 数据倾斜是我们的经典问题,后面再进行展开。 如果我们的下游是 MySQL,HBase 这种,我们都会进行一个批处理的操作,就是让数据存储到一个 buffer 里面,在达到某些条件的时候再进行发送,这样做的目的就是减少和外部系统的交互,降低网络开销的成本。 频繁 GC ,无论是 CMS 也好,G1 也好,在进行 GC 的时候,都会停止整个作业的运行,GC 时间较长还会导致 JobManager 和 TaskManager 没有办法准时发送心跳,此时 JobManager 就会认为此 TaskManager 失联,它就会另外开启一个新的 TaskManager 窗口是一种可以把无限数据切割为有限数据块的手段。比如我们知道,使用滑动窗口的时候数据的重叠问题,size = 5min 虽然不属于大窗口的范畴,可是 step = 1s 代表1秒就要进行一次数据的处理,这样就会造成数据的重叠很高,数据量很大的问题。
2.Flink 作业调优






■ 数据倾斜




■ 内存调优




总 结
https://ververica.cn/developers/flink-training-course-operation/
评论