
超越快手腾讯!度小满NLP模型登顶CLUE榜首

视学算法报道
视学算法报道
编辑:桃子 好困
【新智元导读】要说自然语言处理最厉害的兵器,非「轩辕」剑莫属。近日,度小满金融AI-Lab研发的轩辕 (XuanYuan) 预训练模型刷榜CLUE,距离人类「表现」仅差3.38分!
自然语言处理是人工智能皇冠上的明珠,近日,度小满金融AI-Lab让人类摘得明珠的步伐又前进了一步。
据中文语言理解领域的权威测评基准官网公布,度小满金融AI-Lab研发的轩辕 (XuanYuan) 预训练模型在CLUE1.1分类任务中「力压群雄」获得了排名第一的好成绩。距离人类「表现」仅差3.38分!
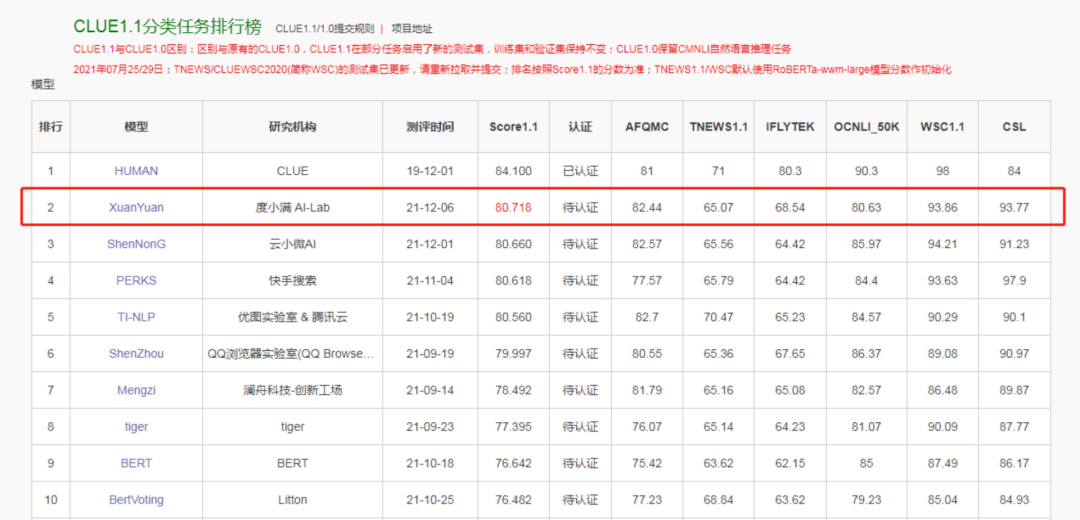
CLUE是中文语言理解领域最具权威性的测评基准之一,涵盖了文本相似度、分类、阅读理解共10项语义分析和理解类子任务。
其中,分类任务需要解决6个问题,例如传统图像分类,文本匹配,关键词分类等等,能够全方面衡量模型性能。
该榜单竞争激烈,几乎是业内兵家必争之地,例如快手搜索、优图实验室 & 腾讯云等等研究机构也都提交了比赛方案。
据悉,位居榜首的「轩辕」是基于Transformer架构的预训练语言模型,涵盖了金融、新闻、百科、网页等多领域大规模数据。因此,该模型「内含」的数据更全面,更丰富,面向的领域更加广泛。

传统预训练模型采取「训练-反馈」模式,度小满金融AI-Lab在训练「轩辕」的时候细化了这一过程,引入了任务相关的数据,融合不同粒度不同层级的交互信息,从而改进了传统训练模式。
模型设计思路有两点:
1.宏观角度,先从通用大规模的数据逐渐迁移到小规模的特定业务以及特定任务,然后去通过不同的阶段逐渐训练,直到满足目标任务。
2.微观角度,针对不同的下游分类任务,会相应的设计出定制化的分类模型。然后采用自监督学习、迁移学习等等提升模型的性能。
目前,「轩辕」还处于1.0的版本,更侧重于自然语言理解能力,在接下来的2.0版本中,研发人员会采用更大规模的数据,训练出更加通用的预训练模型,从而赋能更多的业务和领域。
度小满为何「看中」预训练模型?
预训练模型是一种迁移学习的应用,可以利用几乎无限的文本,学习输入句子的每一个成员的上下文相关的表示,它隐式地学习到了通用的语法语义知识。
换句话说,预训练模型把通用人类的语言知识先学会,然后再代入到某个具体任务。它可以将从开放领域学到的知识迁移到下游任务,以改善低资源任务;还可以使自然语言处理由原来的手工调参、依靠ML专家的阶段,进入到可以大规模、可复制的大工业施展的阶段。
不止是融合人类知识,预训练模型的「改善」、「大规模」、「可复制」等关键词背后意味着降成本、提效率。这和度小满金融CEO朱光「用科技服务小微企业是金融科技公司的价值和使命」的理念不谋而合。
今年5月21日,在度小满金融成立三周年之际,度小满金融CEO朱光表示,「未来三年,度小满将继续加大人工智能技术的研发投入,聚焦小微客户,持续降低小微企业主的整体融资成本,为3000万小微企业主提供值得信赖的综合金融服务。」
目前,除了预训练,度小满金融AI-Lab在文本分类、信息抽取和技术资源等方向亦有布局。在战略上会有两点侧重:首先加强自身的数据生态建设,合法合规使用用户数据,解决数据孤岛;其次通过产学研相结合,布局前沿技术,落地金融场景业务。
目前,度小满与北京大学光华管理学院成立了「金融科技联合实验室」,和西安交大成立了「西安交通大学-度小满金融人工智能联合研究中心」,并与中国科学院自动化研究所共建博士后工作站,共同开展人工智能及相关领域的博士后联合招收培养。
度小满研发人员一直相信人工智能技术势必会变革金融领域的已有研究范式。因此,连接理论前沿研究与业界的技术应用研究,推动人工智能技术在金融产业中发挥更大价值,会是度小满一直的追求。

点个在看 paper不断!