
送书 | 对充满诱惑的网站,你知道可以用python做什么吗?
大家好,我是啃书君。
看到文章的标题之后,想必你一定很好奇这篇文章是干什么的吧。目前网络上的很多文章写的爬虫主要是单线程的爬虫,因此,为了提高爬虫的效率,我今天就为大家带来了多线程的爬虫,带领大家一起学习线程,并为你们带来了实战演练。
线程锁
Threading模块为我们提供了一个类,Threading.Lock锁。我们创建该类的对象,在线程函数执行之前,“抢占”该锁,执行完成之后,“释放”该锁,则我们确保了每次只有一个线程占有该锁。这时对一个公共对象进行操作,则不会发生线程不安全的现象了。
当多个线程同时访问一个数据库时,需要加锁,排队变成单线程,一个一个执行。加锁可以避免并发时导致的逻辑错误,每当一个线程a要访问共享数据域时,必须先获得锁定;如果已经有别的线程b获得了锁定,那么就让线程a暂停,也就是同步阻塞;等到线程b执行完毕,释放锁之后,再让线程a继续。
线程锁的基本语法如下:
lock = threading.Lock()
lock.acquire() # 上锁
lock.release() # 释放锁
threading.Lock
实现原始锁对象的类。一旦一个线程获得一个锁,会阻塞随后尝试获得该锁的线程,直到它被释放;任何线程都可以释放它。
原始锁是一个在锁定时不属于特定线程的同步基元组件。在python中,它是能用最低级的同步基元组件,由_thread拓展模块直接实现。
acquire(blocking=True, timeout=-1)
可以阻塞或者非阻塞的获得锁。
当调用参数blocking设置为True,阻塞直到锁被释放,然后将锁锁定并返回True。
当blocking设置为False时,将不会发生阻塞。
当浮点型timeout参数设置为正值时,则阻塞特定的秒数。当timeout为-1时,则表示无限等待。
release()
释放一个锁,这个方法可以在任何线程中调用,当锁被锁定时,调用该方法可以重置为未锁定,并返回。在没有锁定的锁调用时,会引发RuntimeError异常。
实现线程保护
实现线程保护的过程,大致如下:首先要在同步的代码块前加上lock.acquire()语句,表示要先获得该锁,才能继续执行下面的代码,然后在同步代码块后加上lock.release(),表示释放该锁。
当一个线程或进程获取到该锁,但是却没有释放,那么其他的线程或者时进程是无法获取该锁的,从而无法执行下面的同步代码块,因此也就起到了保护作用。
接下来,我就带领大家来看看没有加锁的情况是怎么样的。
具体代码,如下所示:
import threading
import time
def my_print(name):
for i in range(10):
time.sleep(1)
print(name, i)
start = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('开始:', start)
t1 = threading.Thread(target=my_print, args=('threading1: ',))
t2 = threading.Thread(target=my_print, args=('threading2: ',))
t1.start()
t2.start()
t1.join()
t2.join()
end = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('结束:', end)
运行结果,如下所示:
开始:2021-06-23 18:57:58
threading2: threading1: 0 0
threading2: threading1: 1
1
threading2: threading1: 2 2
threading1: threading2: 3
3
threading2: 4threading1:
4
threading1: 5threading2: 5
threading1: threading2: 6
6
threading1: threading2: 7
7
threading2: 8
threading1: 8
threading1: 9threading2:
9
结束:2021-06-23 18:58:08
从运行结果中可以看到,每当要输出结果时,却输出了threading1或threading2,发生了线程的切换。
如果要避免该情况的发生,那就得使用线程锁了。
上锁之后的效果又是怎么样的呢?
具体代码,如下所示:
def my_print(name):
for i in range(10):
time.sleep(1)
lock.acquire()
print(name, i)
lock.release()
运行结果,如下所示:
开始:2021-06-23 19:14:08
threading2: 0
threading1: 0
threading1: 1
threading2: 1
threading2: 2
threading1: 2
threading1: 3
threading2: 3
threading1: 4
threading2: 4
threading1: 5
threading2: 5
threading2: 6
threading1: 6
threading2: 7
threading1: 7
threading1: 8
threading2: 8
threading1: 9
threading2: 9
结束:2021-06-23 19:14:18
线程锁,其实说白了就是:当两个线程都要对公共的数据域出手的时候,那就必须添加上线程锁,防止出现逻辑错误。因为不同的线程是负责不同的任务的,如果没有使用锁的话,发生线程切换,那整个程序就没有太大的意义了。
线程对象
threading.Thread目前还没有优先级和线程组的功能,而创建的线程也无法被销毁、停止、暂定或中断。
非守护线程
一般创建的线程都是非守护线程,包括主线程也是,即在python程序退出时,如果还有非守护线程在运行,程序会等待所有非守护线程退出之后,才退出。
那么,这就会造成一个问题,当其中一个非守护线程是个死循环,那么整个程序将无法退出。
具体代码,如下所示:
import threading
import time
def kitchen_cleaner():
while True:
print('Olivia cleaned the kitchen')
time.sleep(1)
if __name__ == '__main__':
olivia = threading.Thread(target=kitchen_cleaner)
olivia.start()
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('done!')
当你运行上面代码的时候,你会发现该程序是无法退出的。上面举的例子是主线程无法退出的情况,因此守护线程的到来便解决了此类问题。
守护线程
只有所有的守护线程都结束,整个python程序才会退出,并不是说python程序会等待守护线程运行完毕,相反,当程序退出时,如果还有守护线程在运行,程序会强制终结所有的守护线程,当守护线程都终结后程序才会退出,可以通过修改daemon属性来指定某个线程为守护线程。
具体代码,如下所示:
import threading
import time
def kitchen_cleaner():
while True:
print('Olivia cleaned the kitchen')
time.sleep(1)
if __name__ == '__main__':
olivia = threading.Thread(target=kitchen_cleaner)
olivia.daemon = True # 修改olivia为守护线程
olivia.start()
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('Barron is cokking...')
time.sleep(0.6)
print('done!')
Thread类创建线程对象
下面,我们将使用threading.Thread类创建线程的简单示例。
具体代码,如下所示:
import time
import threading
def test_thread(para='hi', sleep=3):
# 线程运行函数
time.sleep(3)
print(para)
def main():
# 创建线程
thread_hi = threading.Thread(target=test_thread)
thread_hello = threading.Thread(target=test_thread, args=('hello', 1))
# 启动线程
thread_hi.start()
thread_hello.start()
print('main thread has end')
if __name__ == '__main__':
main()
运行结果,如下所示:
main thread has end
hi
hello
target:在run方法中调用的可调用对象,即需要开启线程的可调用对象。 args:在参数target中传入可调用对象的参数元组,默认为空元组。 start():开启线程活动,它将使得run()方法在一个独立的控制程序中被调用,同一个线程对象只能被调用1次。
阻塞主线程
在上面的代码中想必你会发现,按照代码运行的顺序来说,应该是这样的顺序输出:hi、hello、main thread has end
但是却并非这样,原因是这样的,由于子线程创建之后,主线程与子线程开始轮流获取CPU资源,因为子线程需要等待,因此CPU将资源给了主线程,因此就会看到这样的输出效果。
为了让主线程等待或者说是阻塞主线程,因此可以采用join()方法来实现。
具体代码,如下所示:
import time
import threading
def test_thread(para='hi', sleep=3):
# 线程运行函数
time.sleep(3)
print(para)
def main():
# 创建线程
thread_hi = threading.Thread(target=test_thread)
thread_hello = threading.Thread(target=test_thread, args=('hello', 1))
# 启动线程
thread_hi.start()
thread_hello.start()
print('马上执行join()方法啦')
# 执行join方法会阻塞调用线程(主线程),直到调用join方法的线程(thread_hi)结束
thread_hi.join()
print('thread_hi已经结束')
thread_hello.join()
print('thread_hello已经结束')
print('main thread has end')
'''
当然这里只是为了展示join()方法的作用
如果想要等待所有线程都运行完毕,再做其他操作,可以使用for循环
for thd in (thread_hi, thread_hello):
thd.join()
print('所有线程运行结束后的其他操作')
'''
if __name__ == '__main__':
main()
实战演练
可爱图片网双线程抓取
本次实战主要采用多线程的方式进行爬取图片,既实现了提速,同时还有意外的收货哦!
网页分析
可爱图片网的网址如下:
https://www.keaitupian.net/
图片的分类非常丰富:可爱女生、帅气男生、唯美图片、幸福爱情、性感美女等。
不过你们要知道,啃书君写这篇文章的目的仅仅只是为了教你们技术而已,小孩子能有什么坏心思呢?因此为了更好的教大家技术,我就以可爱宠物为例。
本次爬虫使用的模块:
requests、re,threading
列表页与详情页分析
列表页抓取可爱宠物图片,故列表页为:https://www.keaitupian.net/pet/,点击多个页面可以得到,如下所示的URL链接:
https://www.keaitupian.net/pet/list-1.html https://www.keaitupian.net/pet/list-2.html https://www.keaitupian.net/pet/list-{不定页码}.html
由于总页数无法获取,经过我的大胆猜测,发现最终锁定在56页,也就是说,对于宠物这一块的列表页是56页。
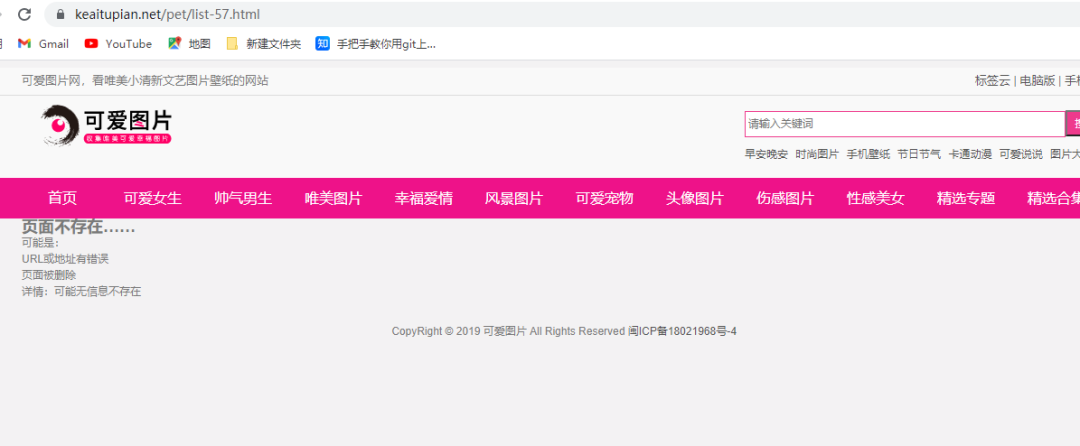
当我写57时,页面是不存在的。
点击任意详情页,查看图片的具体内容,发现详情页也是存在翻页的。并且翻到最后一页时,可以直接到下一份套图,因此可以考虑直接对详情页进行抓取。

当翻到最后一个套图的最后一张图片时,发现向右翻页的代码是为空的,即无法翻页。
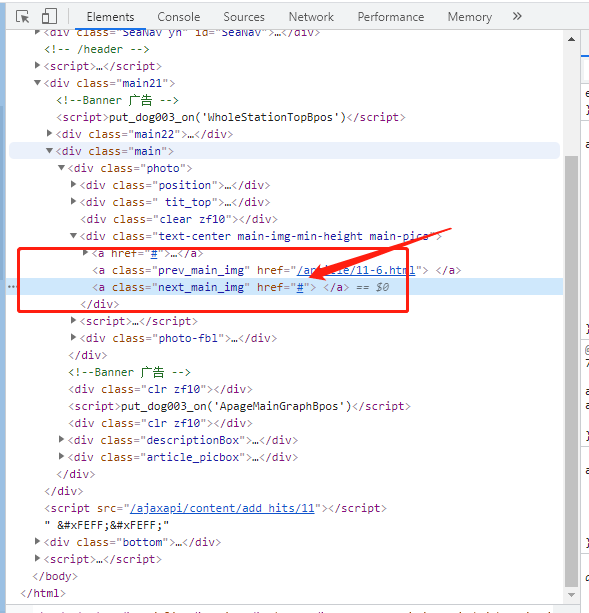
整理逻辑分析
选择第一张图片作为详情页的起始连接。 一线程保存图片 一线程保存下一页地址
基于上述需求,首先实现循环获取URL的线程,该线程主要用于反复爬取URL地址,保存至全局列表中。需要使用threading.Thread创建线程与启动线程,同时为了保证线程之间不会发生逻辑错误,因此需要使用线程互斥锁。
获取URL地址
import requests
import re
import threading
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
# 全局 urls
urls = []
lock = threading.Lock()
# 循环获取URL
def get_image(start_url):
global urls
urls.append(start_url)
next_url = start_url
while next_url != "#":
res = requests.get(url=next_url, headers=headers)
if res is not None:
html = res.text
pattern = re.compile('<a class="next_main_img" href="(.*?)">')
match = pattern.search(html)
if match:
next_url = match.group(1)
if next_url.find('www.keaitupian') < 0:
next_url = f"https://www.keaitupian.net{next_url}"
print(next_url)
# 上锁
lock.acquire()
urls.append(next_url)
# 释放锁
lock.release()
if __name__ == '__main__':
# 获取图片线程
gets = threading.Thread(target=get_image, args=(
"https://www.keaitupian.net/article/202473.html",))
gets.start()
提取目标地址图片
下面为最后一个步骤,通过上述代码抓取到链接的地址,提取图片地址,并保存图片,保存图片也为一个线程。
具体代码如下所示:
def save_image():
global urls
print(urls)
while True:
# 上锁
lock.acquire()
if len(urls) > 0:
# 获取列表第一项
img_url = urls[0]
# 删除列表第一项
del urls[0]
# 释放锁
lock.release()
res = requests.get(url=img_url, headers=headers)
if res is not None:
html = res.text
pattern = re.compile(
'<img class="img-responsive center-block" src="(.*?)"/>')
img_match = pattern.search(html)
if img_match:
img_data_url = img_match.group(1)
print("抓取图片中:", img_data_url)
try:
res = requests.get(img_data_url)
with open(f"images/{time.time()}.png", "wb+") as f:
f.write(res.content)
except Exception as e:
print(e)
else:
print("等待中,长时间等待,可以直接关闭")
在写代码的时候,顺手把性感美女的图片给抓下来了,可以看看图,看你喜不喜欢。
注意哟,该网站反爬比较厉害,建议上代理。
总结
对于线程锁来说,其实就是当多个线程要访问同一个数据域的时候,防止线程出现切换,因此我们需要对线程上锁,做到保护该线程。
对于守护线程与非守护线程,相信就更容易理解了。程序不会等待守护线程的结束,而是主线程结束之后便会直接关闭守护线程,对于非守护线程无法退出的情况相当好用。
本次的爬虫实战主要是带领大家,熟悉了解并掌握线程锁的应用。
最后
看完这篇文章,觉得对你有帮助的话,可以给啃书君点个[再看],我会继续努力,和你们一起成长前进。
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。
点个[再看],让我知道你们也在为自己的人生拼尽全力。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多,更多精彩内容,我们下期再见!
送书
又到了每周三的送书时刻,今天给大家带来的是《吃透Ansible》,本书从Ansible的模块运行以及Playbook的解析和执行两个方面剖析了三个版本的Ansible源码。此外,还优化和改造了用于部署Ceph集群的ceph-ansible项目。

点击下方回复:送书 即可!