
当你的模型不起作用的时候应该怎么做?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

译者 | VK
来源 | Towards Data Science
你的团队几个月来一直在收集数据、构建预测模型、创建用户界面,并与一些早期的用户一起部署新的机器学习产品。但你现在听到的并不是大家一起庆祝项目胜利的声音,而是听到产品经理对那些早期用户的抱怨,这些早期用户对模型精度不满意并开始认为“模型不起作用”。所以你现在应该做什么?
我们常常在很多模式识别实验室里给相关组织应用机器学习算法到新产品见到这种情况。这不是一个容易迅速解决的问题。真实世界的机器学习模型的性能受到许多因素的影响,其中一些因素可能在控制之下,而另一些因素则可能不在控制之下。最重要的是,当试图对真实世界的现象建模时,每个建模问题都有一个固有的噪声或随机性被混合在信号中,这使得很难理解我们使用一个预测模型真正能够达到的准确度。再加上用户对你的模型准确性的期望,你的数据科学团队就突然陷入了一个棘手的境地,并试图找出从哪里开始解决问题。
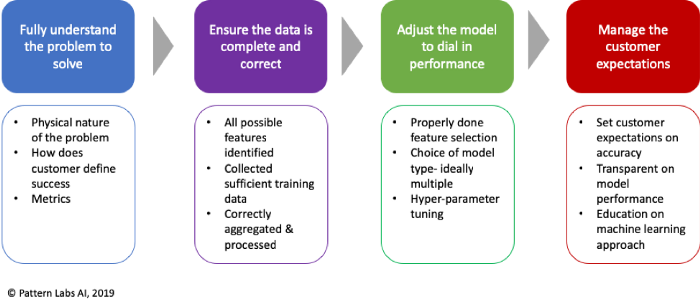
1. 了解要解决的问题
首先要确保团队对他们试图用模型解决的用户问题有很好的理解。令人惊讶的是,数据科学团队对成功的定义的理解与用户的标准经常不同。最近,我们与一家公司合作,试图预测恶劣天气对公用事业公司运营的影响。技术团队绞尽脑汁想要提高他们模型的MAPE分数。当我们深入研究时,我们发现MAPE根本不是正确的度量标准,他们所追求的目标是他们自己设定的(而不是倾听用户的意见)。用户实际上最关心的是,我们能够始终如一地将风暴的影响严重程度划分为1-5级的能力,这个划分是为他们的操作程序定义的。
要确保数据科学团队对这个问题有一个全面的理解,并且这个理解最好直接来自用户,这对于一个新计划的成功是至关重要的。如果你的团队陷入了上面描述的模型“不能工作”的情况,那么第一步就是回去,确保你已经正确地定义了问题,并理解你的用户如何定义成功。
2. 数据是否正确、完整?
下一步是回头查看你的团队收集的输入数据。通常,在处理复杂的实际模型时,模型性能不好的主要原因是由于输入数据集和特征的问题,而不是模型本身。特别是当你运行多种类型的模型(我们建议你尽可能这样做)并得到类似的结果时,这通常是输入数据集的问题。
这一步的一个关键部分是确保你已经收集了尽可能多的相关数据。通常,现实世界的模式中有一些因素并不总是直观或者明显的,因此你可以收集的数据和特征越多越好。你可以使用许多技术来降低特征的选择,以便在最相关的特征上构建模型,我们将在下一个步骤中讨论这些特征。但是对于这一步,重点是重新检查你的假设,哪些输入的特征影响了你试图建模的输出,如果需要,还可以返回以获取额外的数据。例如,当试图为现实世界的现象建模时,通常需要考虑一些不明显的因素,因为这些不明显的因素会造成影响,特别是异常情况——例如季节性、天气、日历事件,甚至地缘政治事件。
其次,应该进行一些简单的QA检查,以确保输入数据得到正确映射和处理。最近,我们与一个想改善模型性能的客户进行了合作,但最终发现问题根本不是与模型有关——客户错误地处理了一些地理位置的特征数据,这使得他们运行的模型无法识别正确的模式。
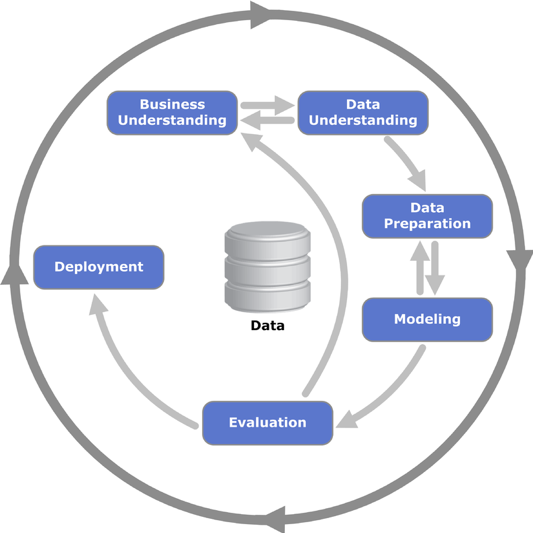
CRISP-DM流程是许多数据科学团队用于管理项目的最常见框架之一。我们喜欢它的重点在于它确保在深入建模之前就能理解业务和数据。CRISP-DM过程中的两个关键步骤是“数据理解”和“数据准备”。正确地遵循这些步骤需要深入研究输入数据以真正地理解它,通常需要可视化数据中的分布、趋势和关系。“数据准备”通常包括预处理、数据扩充与标准化,以便为建模做准备。如果处理得当,这两个步骤可以帮助数据科学家确保输入数据中的错误不会导致他以后遇到的任何模型性能问题。
3. 调整模型提升性能
既然你已经尽可能正确和完整地验证了输入数据,现在是时候关注有趣的东西了——建模本身。这一步中影响最大的部分之一是特征选择——从上到下选择最影响输出的关键特征,并对这些特征进行训练,消除冗余或高度相关的特征,以提高模型的速度和准确度。关于特征选择技术有一些很好的博客文章,包括单变量选择、递归特征消除和随机森林特征重要性。这里有一个可供参考:https://machinelearningmastery.com/feature-selection-machine-learning-python/。无论你使用的是哪种技术,或者它们的组合,都要确保在这一步上花费时间,为你的模型获得特征的最佳组合。
此步骤的另一个重要部分是重新考虑模型的选择,或者考虑添加额外的模型类型或组合多个模型。同样的,也有许多比较不同模型优缺点的好文章,但是我们建议尽可能运行至少两种模型类型(理想情况下,一种是神经网络)来比较结果。
最后,一旦你的特征和选择的模型确定了后,重新调参,并且确保你正确地定义训练集,验证集和测试集,这代表你在调参时并没有选择欺诈,所以它在新数据上可以泛化的很好,而不是在训练集上表现良好甚至过拟合导致在新数据上模型没有良好的工作。
4. 最后,也是最重要的,管理客户的期望
这是许多数据科学家忽视的另一个关键步骤,因为他们认为这“不是他们的工作”。当推出一个面向世界的新机器学习产品时,模型在真实世界的性能存在相当大的不确定性。此外,如上所述,尽管你尽了最大的努力使准确度最大化,但是在你正在解决的问题在真实世界中会出现的大量噪声,这可能会限制模型的性能。所以这个步骤是数据科学团队的责任,需要数据科学团队去与产品经理,销售人员,客户正确定义客户期待在模型中看到的性能,并且在时间的推移拥有额外的数据的情况下,指导他们如何去训练改善模型。
所以下次你的团队在模型放入真实世界里遇到性能问题时,不要玩指责游戏或直接一头扎进调参工作进行优化与拟合,后退一步,跟着这个简单的,结构化的过程一步一步来解决这个问题,在你的新模型上最大化性能。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~