
为什么索引可以让查询变快?终于有人说清楚了!
点击关注公众号,Java干货及时送达
概述
人类存储信息的发展历程大致经历如下:

由于是个人凭着自己理解总结的,因此可能不一定精确,但是毋庸置疑的是,在当代,各大公司机构部门的数据都是维护在数据库当中的。
数据库作为数据存储介质发展的最新产物,必然是具有许多优点的,其中一个很大的优点就是存储在数据库中的数据访问速度非常快。
数据库访问速度快的一个很重要的原因就在于索引index的作用。也就是这篇文章的主要想介绍的内容,为什么索引可以让数据库查询变快?
计算机存储原理
在理解索引这个概念之前,我们需要先了解一下计算机存储方面的基本知识。
我们知道数据持久化之后存在了数据库里,那么我现在的问题是数据库将数据存在了哪里?答案显然是存在了计算机的存储设备上。就个人电脑而言,数据被存在了我们的电脑存储设备上。
计算机的存储设备有很多种,其中速度越快的越贵,因此容量也往往越小例如我们的RAM随机存储器,也就是大家平时说的内存条,速度慢的就相对便宜例如我们的硬盘。而我们的数据往往都是被存在最慢的存储设备硬盘上的,因为存在当中的数据在断电之后依然存在。
计算机的存储介质有多种,例如硬盘,例如告诉缓存,不同的存储介质的数据读取速度是不一样的。例如,像RAM这样的易失性存储设备的读写操作就非常快,访问其中的数据几乎没有延迟性。
由于这个原因,计算机操作系统的设计是这样的:数据永远不会直接从硬盘等机械设备中取出,而是首先从硬盘转移到更快的存储设备,例如RAM,从RAM当中应用程序直接按需获取数据。
计算机内部的机械硬盘是下面这样的:

在一个典型的硬盘驱动器中可以有很多个盘片,“盘片”在外观上非常类似于一个光盘(但具有很高的存储容量)。盘片又被磁道分条,同时一个盘片又可以分为扇区。
要获取数据,“盘片”需要由主轴进行旋转。大多数硬盘供应商都提到了主轴旋转的速度,例如,7200转/分和15000转/分。磁盘中的数据总是以扇区的固定大小倍数表示。因此,如果要从硬盘访问数据,需要执行以下步骤,这也是性能开销的主要来源。
如果数据恰好分布在连续扇区上,那么它将提高获取数据的性能。因为主轴和磁头本身不需要移动/旋转,也就没有太多开销,但是大多数时候这种开销是存在的。
由于存在这种开销,我们不能直接从硬盘获取数据。RAM的存储器高性能的背后的主要原因是它没有像硬盘那样的机械运动部件。但是尽管RAM的性能很高,但它当中的数据却不会用作永久存储,断电之后就会消失,重新启动之后就什么都没有了,这是我们需要硬盘来进行持久化的原因所在。数据库中的数据毫无疑问就是存放在硬盘当中的,因此访问数据库中的数据不可避免的会经历磁盘操作的开销。
索引是如何工作的?
知道上述知识后,索引就更容易理解了。另外,MySQL 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
举个例子,想象一下,现在有一本500页厚包含几十万字的字典,同时里面的字是无序排列的,现在我需要你从中找出某几个字出来同时不允许查看目录。毫无疑问,我们只能一页一页的翻,这是非人类能接受的工作,我们必然想的是先看目录,找到相关的字或者偏旁,然后去对应的地方查找文字,这样效率就大大提高了。目录事实上就是一种索引,其思想一脉相承。
数据库的索引类似于书中的这个目录。索引会帮助我们快速检索数据库,查询不需要通过整个表来获取数据,而是从索引中找到数据块。以一张数据库表为例:
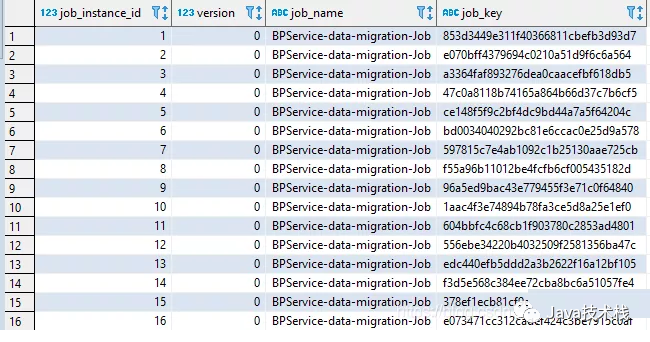
上表是一张真实的数据库表,其中每一行是一条记录,每条记录都有字段。假设上面的数据库是一个有10万条记录的大数据库。现在,我们想从10万条记录中搜索一些内容,那么挨着一个一个搜索无疑将花费很长的时间,这个时候我们在数据结构与算法里学的二分查找法就派上了用场。
二分查找法
使用二分查找法,需要将数据先排序,但是其查询效率将大大提高。2021 最新 Java 面试题出炉!(带全部答案)关 注Java技术栈获取。
例子如下:
假设我们在上面的数据库中使用的是固定长度的记录,固定块记录大小为205个字节, 默认块大小是1024字节。则:
固定记录大小=204字节,块大小=1024字节
所以每个数据块的记录数=1024/204=5条记录,10万条记录就是2万个块
不使用任何算法,我们要查询100000条记录中的某一条,,在最坏的情况下我们需要遍历一遍2万block才能获得全部100000条记录。但如果进行二分查找,则只需要进行20000的对数基数2,即14.287712次即可。这意味着我们只需对排序后的值进行14次搜索,就可以使用二分查找到您感兴趣的唯一值。
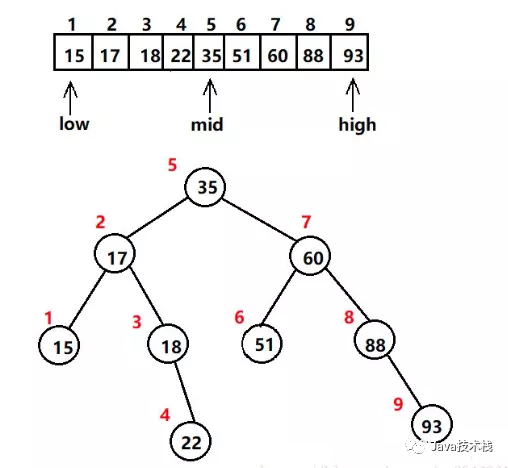
上图是对一串数字生成的二叉查找树。其时间复杂度为O(n)=O(log2N),即以2为底,n的对数。其中n为查找目标群体的总数据量。
例如,假设N为8,则O(n) = O(2为底8的对数) = O(3).
遍历方式,其时间复杂度为O(n)
在上述例子当中,n就是10000。使用索引的时间复杂度为O(2为底10000的对数) 大约等于 13. 和O(10000)之间差大概800倍。
索引为何使得查询变快?
这个时候我们就能直接回答上述问题了,建立了索引的数据,就是通过事先排好序,从而在查找时可以应用二分查找来提高查询效率。这也解释了为什么索引应当尽可能的建立在主键这样的字段上,因为主键必须是唯一的,根据这样的字段生成的二叉查找树的效率无疑是最高的。
为什么索引不能建立的太多?
如果一个表中所有字段的索引很大,也会导致性能下降。想象一下,如果一个索引和一个表一样长,那么它将再次成为一个需要检查的开销。这就好比字典的目录非常详细,但是其长度已经和所有的文字一样长,这个时候目录本身的效率就大大下降了。
索引有弊端吗?
肯定是有的,索引可以提高查询读取性能,而它将降低写入性能。当有索引时,如果更改一条记录,或者在数据库中插入一条新的记录,它将执行两个写入操作(一个操作是写入记录本身,另一个操作是将更新索引)。因此,在定义索引时,必须牢记以下几点:
索引表中的每个字段将降低写入性能。 建议使用表中的唯一值为字段编制索引。 在关系数据库中充当外键的字段必须建立索引,因为它们有助于跨多个表进行复杂查询。 索引还使用磁盘空间,因此在选择要索引的字段时要小心。
什么是聚集索引
聚集索引clustered index也叫聚簇索引,它的定义是:聚集索引的表中数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
例如:

结合上面的表格就很好理解了:数据行的物理顺序与列值的顺序相同,如果我们查询id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。
为什么查询更快呢?我们通过上面的分析知道了索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
主键一般会默认创建聚集索引。
在创建聚集索引之前,应先了解您的数据是如何被访问的。可考虑将聚集索引用于:
包含大量非重复值的列。使用下列运算符返回一个范围值的查询:BETWEEN、>、>=、< 和 <=。被连续访问的列。返回大型结果集的查询。经常被使用联接或 GROUP BY 子句的查询访问的列;一般来说,这些是外键列。对 ORDER BY 或 GROUP BY 子句中指定的列进行索引,可以使 SQL Server 不必对数据进行排序,因为这些行已经排序。这样可以提高查询性能。OLTP型的应用程序,这些程序要求进行非常快速的单行查找(一般通过主键)。应在主键上创建聚集索引。聚集索引不适用于:
频繁更改的列 这将导致整行移动,因为 SQL Server 必须按物理顺序保留行中的数据值。这一点要特别注意,因为在大数据量事务处理系统中数据是易失的
索引失效的典型例子
条件中用or,即使其中有条件带索引,也不会使用索引查询,这就是查询尽量不要用or的原因,用in吧。
常见的sql优化手段有哪些
1.避免全表扫描
全表扫描往往发生在下面几种情况:
2.避免索引失效
不在索引列上做任何操作(计算,函数、自动or手动类型转换),这样会导致索引失效而转向全表扫描。另外,关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 MySQL 系列面试题和答案,非常齐全。
存储引擎不能使用索引中范围条件右边的列。这个是因为age中查询时范围查询了,pos列的索引就没有生效了。
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *。
对于MySQL而言:
mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描 is null,is not null也无法使用索引 like 通配符开头'%abc..',mysql索引会失效会变成全表扫描的操作
3.避免排序,不能避免,尽量选择索引排序
4.避免查询不必要的字段
5.避免临时表的创建,删除
原文链接:https://blog.csdn.net/topdeveloperr/article/details/88742503
版权声明:本文为CSDN博主「topEngineerray」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。







关注Java技术栈看更多干货
