
攻读计算机视觉和机器学习硕士给我带来了什么?
本文转自:机器学习算法那些事
人工智能就业市场持续火热,越来越多的学子投身这一领域。然而,攻读计算机视觉和机器学习研究生需要哪些先决条件?你将学到哪些知识?攻读机器学习硕士是一种怎样的体验?英国萨里大学机器学习与计算机视觉专业硕士 Richmond Alake 对以上问题做了较为全面的解答。

对线性代数和微积分(微分 / 优化)有充分的理解;
统计和概率学基础;
编程语言相关背景;
本科阶段毕业于计算机科学、数学、物理或电子与机械工程等专业。
线性插值(linear interpolation)
无监督聚类(K - 均值)
视觉词袋模型(视觉搜索系统)
团块追踪模块(Blob trackers)
卡尔曼滤波器
粒子滤波器
马尔科夫过程


多层感知机(Mutiplayer Perceptron, MLP):多层感知机是一些连续堆叠的若干层感知器模型。MLP 由一个输入层、一个或多个被称为隐藏层的 TLU、以及最终的输出层组成;
神经风格迁移(NST):这是一种利用深度卷积神经网络和相关算法从一张图像中提取内容信息,并从另一张参考图像中提取风格信息的技术。在提取了风格和内容信息之后,会生成一个组合图像,这里生成图像的内容和风格来自于不同的图像;
循环神经网络(RNN)和 LSTM:它们是神经网络架构的变体,可以接受任意大小的输入,产生随机大小的输出数据。RNN 神经网络架构可以学习时序关系;
人脸检测:用于实现图像和视频中的人脸自动识别和定位的系统。人脸检测在面部识别、摄影技术、运动捕捉等领域有广泛的应用;
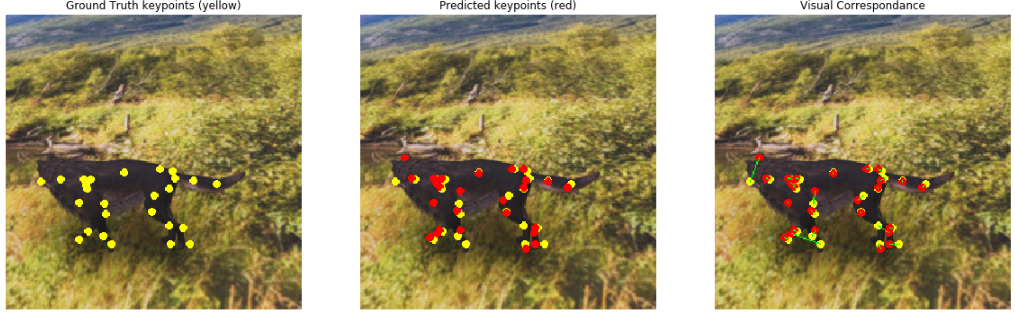
姿态估计:从提供的数字资源(如图像、视频或一段图像序列)中推理出身体主要关节位置的过程。各种姿态估计技术被用于动作识别、人机交互、虚拟现实和 3D 图形游戏资源创建、机器人等应用中;
目标识别:识别与目标对象相关联的类的过程。目标识别和目标检测这两种技术的最终结果和实现方法是类似的。虽然在各种各样的系统和算法中,目标识别过程是先于目标检测进行的;
目标追踪:在一段时间内的图像序列中识别、检测并跟踪一个感兴趣目标的方法。在监控摄像头和交通监控设备的系统中存在诸多目标跟踪应用;
目标检测:目标检测是一种可以识别图像中是否存在特定目标以及其位置的系统。请注意,需要检测的对象可能是单数,也可能不止一个。
迁移学习 / 调优
Python 编程语言
C# 编程语言
姿态估计的理论知识
使用 Unity3D 进行仿真的知识
Google 云平台的使用经验
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。