
scrapy使用cookie的三种方式
点击上方“Python学习开发”,选择“加为星标”
第一时间关注Python技术干货!
1.如果是在headers中使用
def start_requests(self):
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"cookie":"你的微博cookie"
}
url = "https://weibo.com/u/{}".format("你的微博id")
yield Request(url, callback=self.parse, headers=headers)
那么需要把settings.py的COOKIES_ENABLED设置为false
COOKIES_ENABLED = False
2.如果使用cookies=cookies的方式设置cookie
那么需要把settings.py的COOKIES_ENABLED设置为true
COOKIES_ENABLED = True
3.多个url使用cookiejar
此方法也受COOKIES_ENABLED=True的影响
代码示例
class CookieTestSpider(scrapy.Spider):
name = 'usecookie'
cookie_dict = {
"SUB": "你的微博cookie"}
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
weibo_id = "你的微博主页id"
def start_requests(self):
url = "https://weibo.com/u/{}".format(self.weibo_id)
yield Request(url, callback=self.parse, headers=self.headers, cookies=self.cookie_dict, meta={'cookiejar': 1})
def parse(self, response):
source = response.text
url = "https://weibo.com/u/{}".format(self.weibo_id)
if u"我的主页" in source:
print "找到了"
yield scrapy.Request(url, headers=self.headers, meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_page, dont_filter=True)
else:
print "没有cookie"
def parse_page(self, response):
source = response.text
if u"我的主页" in source:
print "又找到了"
else:
print "没有cookie"
首先在start_requests中,在meta里添加一个cookiejar属性,这个键必须这个名,然后是后面值可以从0开始,如果多个start_url可以使用列表的里url对应的下标作为cookiejar的值,
程序可以通过传入的不同值传递多个start_url的cookie。
后面需要使用cookie地方使用meta={'cookiejar': response.meta['cookiejar']}即可。
这种方法的好处:
这种是通过meta的方式,将为spider维护多个独立的cookie会话。如果使用cookies ={},则必须手动维护单独的cookie会话。
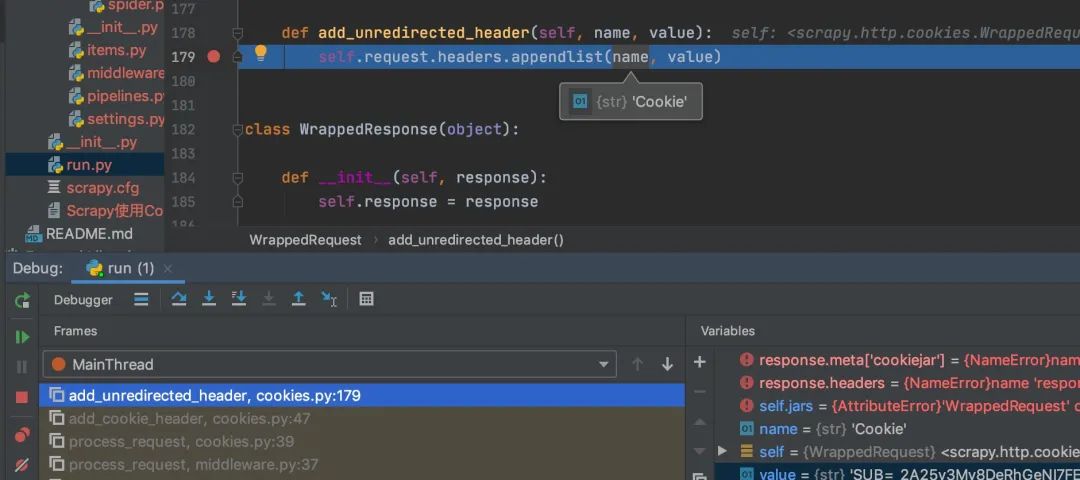
下面这个图是cookiejar的调用栈
评论