
绝对干货!Python 从业十年的程序员,写的万字经验分享
阅读本文大概需要 9 分钟。

作者:laisky(基于 CC BY 4.0 授权许可)
原题:Python之路(内容略有调整)
来源:https://laisky.com/p/python-road
本文起源于我在 Twitter 上发布的关于 Python 经历的一系列话题。
出于某些原因,想记录一下我过去数年使用 Python 的经验和一些感悟。毕竟算是一门把我带入互联网行业的语言,而我近期已经几乎不再写 Py 代码, 做一个记录,也许会对他人起到些微的帮助,也算是纪念与感恩了。
最早接触 py 是 2010 年左右,那之前主要是使用 c、fortran 和 matlab 做数值运算。当时在做一些文件文本处理时觉得很麻烦,后来看到 NASA 说要用 py 取代 matlab,就去接触了 py。
python 那极为简洁与优美的语法给了当时的我极大的震撼,时至今日,写 py 代码对我而言依然是一种带有艺术意味的享受。
首先开宗明义的说一句:python 并不慢,至少不够慢。拿一个 web 后端来说,一台垃圾 4 核虚机,跑 4 个同步阻塞的 django,假设 django 上合理利用线程分担了阻塞操作,假设每节点每秒可以处理 50 个请求(超低估),在白天的 10 小时内就可以处理 720 万请求。而这种机器跑一天仅需要 20 块钱。

在学习 Python 以前需要强调的是:基础语法非常重要。虽然我们都不推崇过多的死记硬背,但是少量必要的死背是以后所有复杂思维活动的基础,就像五十音对于日语,通假字和常用动名词对于文言文,你不会就是不行。
一般认为,这包括数据类型(值/引用)、作用域(scope)、keyword、builtin 函数等
关于 Python 版本的选择,很多公司老项目依然在用 2.6、2.7,新项目的话建议至少选择 3.6(拥有稳定的 asyncio)。
从 2.7 到 3.4 https://blog.laisky.com/p/whats-new-in-python3-4/ 从 3.4 到 3.5 https://blog.laisky.com/p/whats-new-in-python3-5/ 从 3.5 到 3.6 https://blog.laisky.com/p/whats-new-in-python3-6/ 从 3.6 到 3.7 https://docs.python.org/zh-cn/3/whatsnew/3.7.html
关于版本最后在说几点,建议在本地和服务器上都通过 pyenv 来管理版本,而不要去动系统自带的 python(以免引起额外的麻烦) https://blog.laisky.com/p/pyenv/
另外一点就是,如果你想写一个兼容 2、3 的工具包,你可以考虑使用 future http://python-future.org/compatible_idioms.html
最后提醒一下,2to3 这个脚本是有可能出错的。
学完基础就可以开始动手写代码了,这时候应该谨记遵守一些“通行规范”,几年前给公司内分享时做过一个摘要:
风格指引 https://laisky.github.io/style-guide-cn/style-guides/source-code-style-guides/ 一些注意事项 https://laisky.github.io/style-guide-cn/style-guides/consensuses/
有了一定的实践经验后,你应该学习更多的包来提高自己的代码水平。
值得学习的内建包 https://pymotw.com/3/ 值得了解的第三方包 https://github.com/vinta/awesome-python
因为 py 的哲学(import this)建议应该有且仅有一个完美的方式做一件事,所以建议优先采用且完善既有项目而不建议过多的造轮子。
一个小插曲,写这段的 Tim Peters 就是发明 timsort 的那位。
https://en.wikipedia.org/wiki/Tim_Peters_(software_engineer)
有空时候,建议尽可能的完整读教材和文档,建立系统性的知识体系,这可以极大的提升你的眼界和思维能力。我自己读过且觉得值得推荐的针对 py 的书籍有:
https://docs.python.org/3/ learning python 核心编程 改进Python的91个建议 Python高手之路 Python源码剖析 数据结构与算法:Python语言描述
如果你真的很喜欢 Python 的话,那我觉得你应该也会喜欢阅读 PEP,记得几年前我只要有空就会去翻阅 PEP,这相当于是 Py 的 RFC,里面记录了几乎每一项语法的设计理念与目的。我特别喜欢的 PEP 有:
8 3148 380 484 & 3107 492: async 440 3132 495 你甚至能学到历史知识
以前听别人讲过一个比喻,静态语言是吃冒菜,一次性烫好。而动态语言是涮火锅,吃一点涮一点。
那么我觉得,GIL 就是仅有一双筷子的火锅,即使你菜很多,一次也只能涮一个。
但是,对于 I/O bound 的操作,你不必一直夹着菜,而是可以夹一些扔到锅里,这样就可以同时涮很多,提高并行效率。
GIL 在一个进程内,解释器仅能同时解释执行一条语句,这为 py 提供了天然的语句级线程安全,从很多意义上说,这都极大的简化了并行编程的难度。对于 I/O 型应用,多线程并不会受到多大影响。对于 CPU 型应用,编写一个基于 Queue 的多进程 worker 其实也就是几行的事。
(订正:应为伪指令级的线程安全)
from time import sleep
from concurrent.futures import ProcessPoolExecutor, wait
from multiprocessing import Manager, Queue
N_PARALLEL = 5
def worker(i: int, q: Queue) -> None:
print(f'worker {i} start')
while 1:
data = q.get()
if data is None: # 采用毒丸(poison pill)方式来结束进程池
q.put(data)
print(f'worker {i} exit')
return
print(f'dealing with data {data}...')
sleep(1)
def main():
executor = ProcessPoolExecutor(max_workers=N_PARALLEL) # 控制并发量
with Manager() as manager:
queue = manager.Queue(maxsize=50) # 控制缓存量
workers = [executor.submit(worker, i, queue) for i in range(N_PARALLEL)]
for i in range(50):
queue.put(i)
print('all task data submitted')
queue.put(None)
wait(workers)
print('all done')
main()
我经常给新人讲,是否能谨慎的对待并行编程,是一个区分初级和资深后端开发的分水岭。业界有一句老话:“没有正确的并行程序,只有不够量的并行度”,由此可见并行开发的复杂程度。
我个人认为思考并行时主要是在考虑两个问题:同步控制和资源用量。
对于同步控制,你在 thread, multiprocessing, asyncio 几个包里都会发现一系列的工具:
Lock 互斥锁 RLock 可重入锁 Queue 队列 Condition 条件锁 Event 事件锁 Semaphore 信号量
这个就不展开细谈了,属于另一个语言无关的大领域。(以前写过一个很简略的简介:并行编程中的各种锁(https://blog.laisky.com/p/concurrency-lock/))
对于资源控制,一般来说主要就是两个地方:
缓存区有多大(Queue 长度) 并发量有多大(workers 数量)
一般来说,前者直接确定了你内存的消耗量,最好选择一个恰好或略高于消费量的数。后者一般直接决定了你的 CPU 使用率,过高的并发量会增加切换开销,得不偿失。
既然提到了 workers,稍微简单展开一下“池”这个概念。我们经常提到线程池、进程池、连接池。说白了就是对于一些可重用的资源,不必每次都创建新的,而是使用完毕后回收留待下一个数据继续使用。比如你可以选择不断地开子线程,也可以选择预先开好一批线程,然后通过 queue 来不断的获取和处理数据。
所以说使用“池”的主要目的就是减少资源的消耗。另一个优点是,使用池可以非常方便的控制并发度(很多新人以为 Queue 是用来控制并发度的,这是错误的,Queue 控制的是缓存量)。
对于连接池,还有另一层好处,那就是端口资源是有限的,而且回收端口的速度很慢,你不断的创建连接会导致端口迅速耗尽。
这里做一个用语的订正。Queue 控制的应该是缓冲量(buffer),而不是缓存量(cache)。一般来说,我们习惯上将写入队列称为缓冲,将读取队列称为缓存(有源)。
对前面介绍的 python 中进程/线程做一个小结,线程池可以用来解决 I/O 的阻塞,而进程可以用来解决 GIL 对 CPU 的限制(因为每一个进程内都有一个 GIL)。所以你可以开 N 个(小于等于核数)进程池,然后在每一个进程中启动一个线程池,所有的线程池都可以订阅同一个 Queue,来实现真正的多核并行。
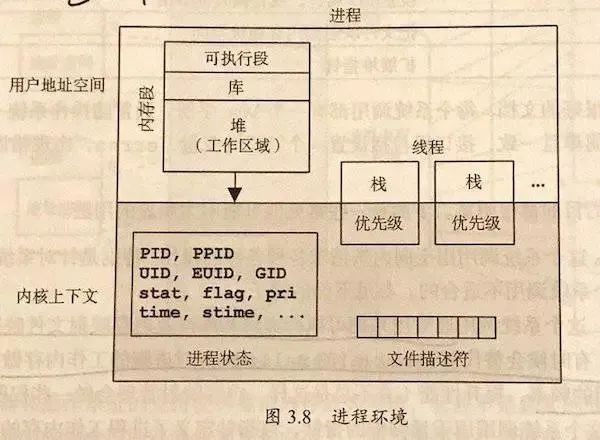
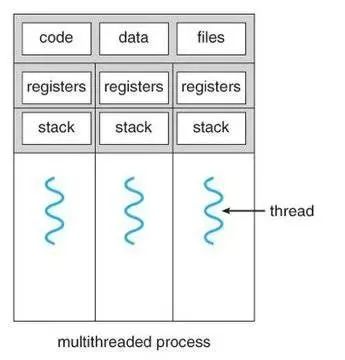
非常简单的描述一下进程/线程,对于操作系统而言,可以认为进程是资源的最小单位(在 PCB 内保存如图 1 的数据)。而线程是调度的最小单位。同一个进程内的线程共享除栈和寄存器外的所有数据。
所以在开发时候,要小心进程内多线程数据的冲突,也要注意多进程数据间的隔离(需要特别使用进程间通信)
操作系统笔记:进程(https://blog.laisky.com/p/os-process/) 操作系统笔记:调度(https://blog.laisky.com/p/os-scheduler/)
再简单的补充一下,进程间通信的手段有:管道、信号、消息队列、信号量、共享内存和套接字。不过在 Py 里,单机上最常用的进程间通信就是 multiprocessing 里的 Queue 和 sharedctypes。
顺带一提,因为 CPython 的 refcnt 机制,所以 COW(copy on write)并不可靠。
人们在见到别人的“错误写法”时,倾向于无视或吐槽讽刺。但是这个行为除了让自己爽一下外没有任何意义,不懂的还是不懂,最后真正发挥影响的还是那些能够描绘一整条学习路径的方法。
我一直希望能看到一个“朴素诚恳”的切合工程实践的教程,而不是网上流传的入门大全和网课兜售骗钱的框架调参速成。
关于进程间的内存隔离,补充一个简单直观的例子。可以看到普通变量 normal_v在两个子进程内变成了两个独立的变量(都输出 1),而共享内存的shared_v仍然是同一个变量,分别输出了 1 和 2。
from time import sleep
from concurrent.futures import ProcessPoolExecutor, wait
from multiprocessing import Manager, Queue
from ctypes import c_int64
def worker(i, normal_v, shared_v):
normal_v += 1 # 因为进程间内存隔离,所以每个进程都会得到 1
shared_v.value += 1 # 因为使用了共享内存,所以会分别得到 1 和 2
print(f'worker[{i}] got normal_v {normal_v}, shared_v {shared_v.value}')
def main():
executor = ProcessPoolExecutor(max_workers=2)
with Manager() as manager:
lock = manager.Lock()
shared_v = manager.Value(c_int64, 0, lock=lock)
normal_v = 0
workers = [executor.submit(worker, i, normal_v, shared_v) for i in range(2)]
wait(workers)
print('all done')
main()
顺带一提,在 3.8 里有了 sharedmemory:
"""
shared memory
=============
Output:
::
worker[0] got normal_v 1, shared_v 1
worker[2] got normal_v 1, shared_v 2
worker[3] got normal_v 1, shared_v 3
worker[1] got normal_v 1, shared_v 4
worker[4] got normal_v 1, shared_v 5
worker[5] got normal_v 1, shared_v 6
worker[6] got normal_v 1, shared_v 7
worker[8] got normal_v 1, shared_v 8
worker[7] got normal_v 1, shared_v 9
worker[9] got normal_v 1, shared_v 10
all done
"""
from traceback import print_exc
from time import sleep
from concurrent.futures import ProcessPoolExecutor, wait
from multiprocessing import Event, RLock
from multiprocessing.shared_memory import ShareableList
from multiprocessing.managers import SharedMemoryManager, SyncManager
from ctypes import c_int64
def worker(l: RLock, evt: Event, i: int, normal_v: int, shared_v: ShareableList):
try:
evt.wait() # 确保任务同时开始
normal_v += 1 # 因为进程间内存隔离,所以每个进程都会得到 1
with RLock(): # 需要自行处理锁
shared_v[0] += 1 # 因为使用了共享内存,所以会得到连续累加的值
print(f"worker[{i}] got normal_v {normal_v}, shared_v {shared_v[0]}")
except Exception:
print_exc()
raise
def main():
executor = ProcessPoolExecutor(max_workers=10)
with SharedMemoryManager() as smm, SyncManager() as sm:
evt = sm.Event()
shared_v = smm.ShareableList([0])
normal_v = 0
workers = [
executor.submit(worker, sm.RLock(), evt, i, normal_v, shared_v)
for i in range(10)
]
evt.set()
wait(workers)
[f.result() for f in workers]
print("all done")
if __name__ == "__main__":
main()
从过去的工作经验中,我总结了一个简单粗暴的规矩:如果你要使用多进程,那么在程序启动的时候就把进程池启动起来,然后需要任何资源都请在进程内自行创建使用。如果有数据需要共享,一定要显式的采用共享内存或 queue 的方式进行传递。
见过太多在进程间共享不该共享的东西而导致的极为诡异的数据行为。
最早,一台机器从头到尾只能干一件事情。
后来,有了分时系统,我们可以开很多进程,同时干很多事。
但是进程的上下文切换开销太大,所以又有了线程,这样一个核可以一直跑一个进程,而仅需要切换进程内子线程的栈和寄存器。
直到遇到了 C10K 问题,人们发觉切换几万个线程还是挺重的,是否能更轻?
这里简单的展开一下,内存在操作系统中会被划分为内核态和用户态两部分,内核态供内核运行,用户态供普通的程序用。
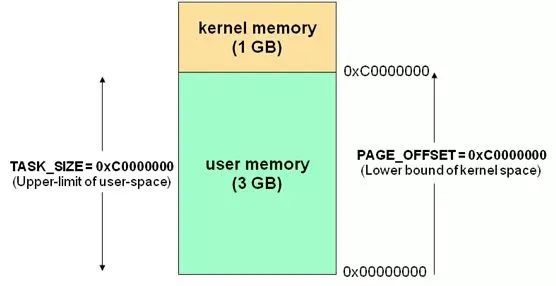
应用程序通过系统 API(俗称 syscall)和内核发生交互。拿常见的 HTTP 请求来说,其实就是一次同步阻塞的 socket 调用,每次调用都会导致线程阻塞等待内核响应(内核陷入)。
而被阻塞的线程就会导致切换的发生。所以自然会问,能不能减少这种切换开销?换句话说,能不能在一个地方把事情做完,而不要切来切去的。
这个问题有两个解决思路,一是把所有的工作放进内核去做(略)。
另一个思路就是把尽可能多的工作放到用户态来做。这需要内核接口提供额外的支持:异步系统调用。
如 socket 这样的调用就支持非阻塞调用,调用后会拿到一个未就绪的 fp,将这个 fp 交给负责管理 I/O 多路复用的 selector,再注册好需要监听的事件和回调函数(或者像 tornado 一样采用定时 poll),就可以在事件就绪(如 HTTP 请求的返回已就绪)时执行相关函数。
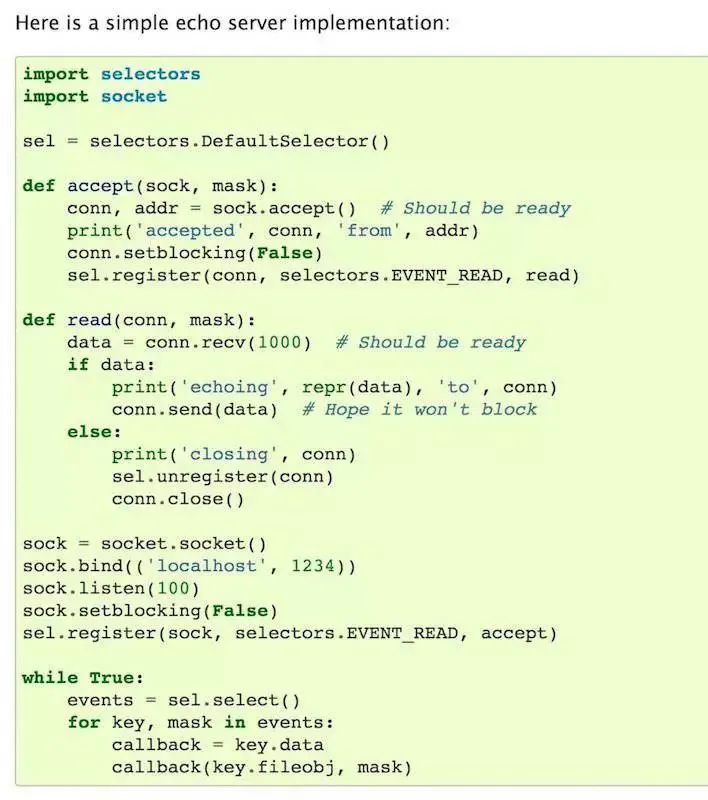
https://github.com/tornadoweb/tornado/blob/f1824029db933d822f5b0d02583e4e6137f2bfd2/tornado/ioloop.py#L746

这样就可以实现在一个线程内,启动多个曾经会导致线程被切换的系统调用,然后在一个线程内监听这些调用的事件,谁先就绪就处理谁,将切换的开销降到了最小。
有一个需要特别注意的要点,你会发现主线程其实就是一个死循环,所有的调用都发生在这个循环之内。所以,你写的代码一定要避免任何阻塞。

听上去很美好,这是个万能方案吗?
很可惜不是的,最直接的一个问题是,并不是所有的 syscall 都提供了异步方法,对于这种调用,可以用线程池进行封装。对于 CPU 密集型调用,可以用进程池进行封装,asyncio 里提供了 executor 和协程进行联动的方法,这里提供一个线程池的简单例子,进程池其实同理。
from time import sleep
from asyncio import get_event_loop, sleep as asleep, gather, ensure_future
from concurrent.futures import ThreadPoolExecutor, wait, Future
from functools import wraps
executor = ThreadPoolExecutor(max_workers=10)
ioloop = get_event_loop()
def nonblocking(func) -> Future:
@wraps(func)
def wrapper(*args):
return ioloop.run_in_executor(executor, func, *args)
return wrapper
@nonblocking # 用线程池封装没法协程化的普通阻塞程序
def foo(n: int):
"""假装我是个很耗时的阻塞调用"""
print('start blocking task...')
sleep(n)
print('end blocking task')
async def coroutine_demo(n: int):
"""我就是个普通的协程"""
# 协程内不能出现任何的阻塞调用,所谓一朝协程,永世协程
# 那我偏要调一个普通的阻塞函数怎么办?
# 最简单的办法,套一个线程池…
await foo(n)
async def coroutine_demo_2():
print('start coroutine task...')
await asleep(1)
print('end coroutine task')
async def coroutine_main():
"""一般我们会写一个 coroutine 的 main 函数,专门负责管理协程"""
await gather(
coroutine_demo(1),
coroutine_demo_2()
)
def main():
ioloop.run_until_complete(coroutine_main())
print('all done')
main()
Python3 asyncio 简介(https://blog.laisky.com/p/asyncio/)
上面的例子全部都基于 3.7,如果你还在使用 Py2,那么你也可以通过 gevent、tornado 用上协程。
我个人倾向于 tornado,因为更为白盒,而且写法和 3 接近,如果你也赞同,那么可以试试我以前给公司写的 kipp 库,基于 tornado 封装了更多的工具。
https://github.com/Laisky/kipp/blob/2bc5bda6e7f593f89be662f46fed350c9daabded/kipp/aio/init.py
Gevent Demo:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Gevent Pool & Child Tasks
=========================
You can use gevent.pool.Pool to limit the concurrency of coroutines.
And you can create unlimit subtasks in each coroutine.
Benchmark
=========
cost 2.675039052963257s for url http://httpbin.org/
cost 2.66813588142395s for url http://httpbin.org/ip
cost 2.674264907836914s for url http://httpbin.org/user-agent
cost 2.6776888370513916s for url http://httpbin.org/get
cost 3.97711181640625s for url http://httpbin.org/headers
total cost 3.9886841773986816s
"""
import time
import gevent
from gevent.pool import Pool
import gevent.monkey
pool = Pool(10) # set the concurrency limit
gevent.monkey.patch_socket()
try:
import urllib2
except ImportError:
import urllib.request as urllib2
TARGET_URLS = (
'http://httpbin.org/',
'http://httpbin.org/ip',
'http://httpbin.org/user-agent',
'http://httpbin.org/headers',
'http://httpbin.org/get',
)
def demo_child_task():
"""Sub coroutine task"""
gevent.sleep(2)
def demo_task(url):
"""Main coroutine
You should wrap your each task into one entry coroutine,
then spawn its own sub coroutine tasks.
"""
start_ts = time.time()
r = urllib2.urlopen(url)
demo_child_task()
print('cost {}s for url {}'.format(time.time() - start_ts, url))
def main():
start_ts = time.time()
pool.map(demo_task, TARGET_URLS)
print('total cost {}s'.format(time.time() - start_ts))
if __name__ == '__main__':
main()
tornado demo:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
cost 0.5578329563140869s, get http://httpbin.org/get
cost 0.5621621608734131s, get http://httpbin.org/ip
cost 0.5613000392913818s, get http://httpbin.org/user-agent
cost 0.5709919929504395s, get http://httpbin.org/
cost 0.572376012802124s, get http://httpbin.org/headers
total cost 0.5809519290924072s
"""
import time
import tornado
import tornado.web
import tornado.httpclient
TARGET_URLS = [
'http://httpbin.org/',
'http://httpbin.org/ip',
'http://httpbin.org/user-agent',
'http://httpbin.org/headers',
'http://httpbin.org/get',
]
@tornado.gen.coroutine
def demo_hanlder(ioloop):
for i, url in enumerate(TARGET_URLS):
demo_task(url, ioloop=ioloop)
@tornado.gen.coroutine
def demo_task(url, ioloop=None):
start_ts = time.time()
http_client = tornado.httpclient.AsyncHTTPClient()
r = yield http_client.fetch(url)
# r is the response object
end_ts = time.time()
print('cost {}s, get {}'.format(end_ts - start_ts, url))
TARGET_URLS.remove(url)
if not TARGET_URLS:
ioloop.stop()
def main():
start_ts = time.time()
ioloop = tornado.ioloop.IOLoop.instance()
ioloop.add_future(demo_hanlder(ioloop), lambda f: None)
ioloop.start()
# total cost will equal to the longest task
print('total cost {}s'.format(time.time() - start_ts))
if __name__ == '__main__':
main()
tornado demo:
from time import sleep
from kipp.aio import coroutine2, run_until_complete, sleep, return_in_coroutine
from kipp.utils import ThreadPoolExecutor, get_logger
executor = ThreadPoolExecutor(10)
logger = get_logger()
@coroutine2
def coroutine_demo():
logger.info('start coroutine_demo')
yield sleep(1)
logger.info('coroutine_demo done')
yield executor.submit(blocking_func)
return_in_coroutine('yeo')
def blocking_func():
logger.info('start blocking task...')
sleep(1)
logger.info('blocking task return')
return 'hard'
@coroutine2
def coroutine_main():
logger.info('start coroutine_main')
r = yield coroutine_demo()
logger.info('coroutine_demo return: {}'.format(r))
yield sleep(1)
return_in_coroutine('coroutine_main yo')
def main():
f = coroutine_main()
run_until_complete(f)
logger.info('coroutine_main return: {}'.format(f.result()))
if __name__ == '__main__':
main()
kipp demo:
from time import sleep
from kipp.aio import coroutine2, run_until_complete, sleep, return_in_coroutine
from kipp.utils import ThreadPoolExecutor, get_logger
executor = ThreadPoolExecutor(10)
logger = get_logger()
@coroutine2
def coroutine_demo():
logger.info('start coroutine_demo')
yield sleep(1)
logger.info('coroutine_demo done')
yield executor.submit(blocking_func)
return_in_coroutine('yeo')
def blocking_func():
logger.info('start blocking task...')
sleep(1)
logger.info('blocking task return')
return 'hard'
@coroutine2
def coroutine_main():
logger.info('start coroutine_main')
r = yield coroutine_demo()
logger.info('coroutine_demo return: {}'.format(r))
yield sleep(1)
return_in_coroutine('coroutine_main yo')
def main():
f = coroutine_main()
run_until_complete(f)
logger.info('coroutine_main return: {}'.format(f.result()))
if __name__ == '__main__':
main()
使用 tornado 时需要注意,因为它依赖 generator 来模拟协程,所以函数无法返回,只能用 raise gen.Return 来模拟。3.4 里引入了 yield from 到 3.6 的 async/await 才算彻底解决了这个问题。还有就是小心 tornado 里的 Future 不是线程安全的。
至于 gevent,容我吐个槽,求别再提 monkey_patch 了…
https://docs.python.org/3/library/asyncio-task.html 官方文档对于 asyncio 的描述很清晰易懂,推荐一读。一个小提示,async 函数被调用后会创建一个 coroutine,这时候该协程并不会运行,需要通过 ensure_future 或 create_task 方法生成 Task 后才会被调度执行。
另外,一个进程内不要创建多个 ioloop。
做一个小结,一个简单的做法是,启动程序后,分别创建一个进程池(进程数小于等于可用核数)、线程池和 ioloop,ioloop 负责调度一切的协程,遇到阻塞的调用时,I/O 型的扔进线程池,CPU 型的扔进进程池,这样代码逻辑简单,还能尽可能的利用机器性能。一个简单的完整示例:
"""
✗ python process_thread_coroutine.py
[2019-08-11 09:09:37,670Z - INFO - kipp] - main running...
[2019-08-11 09:09:37,671Z - INFO - kipp] - coroutine_main running...
[2019-08-11 09:09:37,671Z - INFO - kipp] - io_blocking_task running...
[2019-08-11 09:09:37,690Z - INFO - kipp] - coroutine_task running...
[2019-08-11 09:09:37,691Z - INFO - kipp] - coroutine_error running...
[2019-08-11 09:09:37,691Z - INFO - kipp] - coroutine_error end, cost 0.00s
[2019-08-11 09:09:37,693Z - INFO - kipp] - cpu_blocking_task running...
[2019-08-11 09:09:38,674Z - INFO - kipp] - io_blocking_task end, cost 1.00s
[2019-08-11 09:09:38,695Z - INFO - kipp] - coroutine_task end, cost 1.00s
[2019-08-11 09:09:39,580Z - INFO - kipp] - cpu_blocking_task end, cost 1.89s
[2019-08-11 09:09:39,582Z - INFO - kipp] - coroutine_main got [None, AttributeError('yo'), None, None]
[2019-08-11 09:09:39,582Z - INFO - kipp] - coroutine_main end, cost 1.91s
[2019-08-11 09:09:39,582Z - INFO - kipp] - main end, cost 1.91s
"""
from time import sleep, time
from asyncio import get_event_loop, sleep as asleep, gather, ensure_future, iscoroutine
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor, wait
from functools import wraps
from kipp.utils import get_logger
logger = get_logger()
N_FORK = 4
N_THREADS = 10
thread_executor = ThreadPoolExecutor(max_workers=N_THREADS)
process_executor = ProcessPoolExecutor(max_workers=N_FORK)
ioloop = get_event_loop()
def timer(func):
@wraps(func)
def wrapper(*args, **kw):
logger.info(f"{func.__name__} running...")
start_at = time()
try:
r = func(*args, **kw)
finally:
logger.info(f"{func.__name__} end, cost {time() - start_at:.2f}s")
return wrapper
def async_timer(func):
@wraps(func)
async def wrapper(*args, **kw):
logger.info(f"{func.__name__} running...")
start_at = time()
try:
return await func(*args, **kw)
finally:
logger.info(f"{func.__name__} end, cost {time() - start_at:.2f}s")
return wrapper
@timer
def io_blocking_task():
"""I/O 型阻塞调用"""
sleep(1)
@timer
def cpu_blocking_task():
"""CPU 型阻塞调用"""
for _ in range(1 << 26):
pass
@async_timer
async def coroutine_task():
"""异步协程调用"""
await asleep(1)
@async_timer
async def coroutine_error():
"""会抛出异常的协程调用"""
raise AttributeError("yo")
@async_timer
async def coroutine_main():
ioloop = get_event_loop()
r = await gather(
coroutine_task(),
coroutine_error(),
ioloop.run_in_executor(thread_executor, io_blocking_task),
ioloop.run_in_executor(process_executor, cpu_blocking_task),
return_exceptions=True,
)
logger.info(f"coroutine_main got {r}")
@timer
def main():
get_event_loop().run_until_complete(coroutine_main())
if __name__ == "__main__":
main()
学到这一步,你已经能够熟练的运用协程、线程、进程处理不同类型的任务。接着拿上面提到的垃圾 4 核虚机举例,你现在应该可以比较轻松的实现达到 1k QPS 的服务,在白天十小时里可以处理超过一亿请求,费用依然仅 20元/天。你还有什么借口说是因为 Python 慢呢?
人们在聊到语言/框架/工具性能时,考虑的是“当程序员尽可能的优化后,工具性能会成为最终的瓶颈,所以我们一定要选一个最快的”。
但事实上是,程序员本身才是性能的最大瓶颈,而工具真正体现出来的价值,是在程序员很烂时,所能提供的兜底性能。
如果你觉得自己并不是那个瓶颈,那也没必要来听我讲了
在性能优化上有两句老话:
一定要针对瓶颈做优化 过早优化是万恶之源
所以我觉得要开放、冷静地看待工具的性能。在一套完整的业务系统中,框架工具往往是耗时占比最低的那个,在扩容、缓存技术如此发达的今天,你已经很难说出工具性能不够这样的话了。
成长的空间很大,多在自己身上找原因。
一个经验观察,即使在工作中不断的实际练习,对于异步协程这种全新的思维模式,从学会到能在工作中熟练运用且不犯大错,比较聪明的人也需要一个月。
换成 go 也不会好很多,await 也能实现同步写法,而且你依然需要面对我前文提到过的同步控制和资源用量两个核心问题。
简单提一下性能分析,py 可以利用 cProfile、line_profiler、memory_profiler、vprof、objgraph 等工具生成耗时、内存占用、调用关系图、火焰图等。
关于性能分析领域的更多方法论和理念,推荐阅读《性能之巅》(过去做的关于性能之巅的部分摘抄 https://twitter.com/ppcelery/status/1051832271001382912)。
必须强调:优化必须要有足够的数据支撑,包括优化前和优化后。
性能优化其实是一个非常复杂的领域,虽然上面提到的工具可以生成各式各样的看上去就很厉害的图,但是优化不是简单的你看哪慢就去改哪,而是需要有极其扎实的基础知识和全局思维的。
而且,上述工具得出的指标,在性能尚未逼近极限时,可能会有相当大的误导性,使用的时候也要小心。
有一些较为普适的经验:
I/O 越少越好,尽量在内存里完成 内存分配越少越好,尽量复用 变量尽可能少,gc 友好 尽量提高局部性 尽量用内建函数,不要轻率造轮子
下列方法如非瓶颈不要轻易用:
循环展开 内存对齐 zero copy(mmap、sendfile)
测试是开发人员很容易忽视的一个环节,很多人认为交给 QA 即可,但其实测试也是开发过程中的一个重要组成部分,不但可以提高软件的交付质量,还可以增进你的代码组织能力。
最常见的划分可以称之为黑盒 & 白盒,前者是只针对接口行为的测试,后者是深入了解实现细节,针对实现方式进行的针对性测试。
对 Py 开发者而言,最简单实用的工具就是 unitest.TestCase 和 pytest,在包内任何以 test*.py 命名的文件,内含 TestCase 类的以 test* 命名的方法都会被执行。
测试方法也很简单,你给定入参,然后调用想要测试的函数,然后检查其返回是否符合需求,不符合就抛出异常。
https://docs.pytest.org/en/latest/
"""
test_demo.py
"""
from unittest import TestCase
from typing import List
def demo(l: List[int]) -> int:
return l[0]
class DemoTestCase(TestCase):
def setUp(self):
print("first run")
def tearDown(self):
print("last run")
def test_demo(self):
data = []
self.assertRaises(IndexError, demo, data)
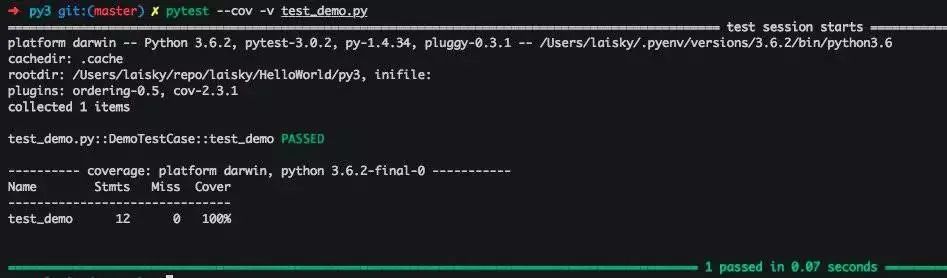
开始写测试后,你才会意识到你的很多函数非常难以测试。因为它们可能有嵌套调用,可能有内含状态,可能有外部依赖等等。
但是需要强调的是,这不但不是不写测试的理由,这其实正是写测试的目的!
通过努力地写测试,会强迫你开始编写精简、功能单一、无状态、依赖注入、避免链式调用的函数。
一个简单直观的“好坏对比”,链式调用的函数很难测试,它内含了太多其他函数的调用,一旦测试就变成了一个“集成测试”。而将其按照步骤一一拆分后,就可以对其进行精细化的“单元测试”,这可以契合你开发的步伐,步步为营稳步推进。
"""
这是很糟糕的链式调用
"""
def main():
func1()
def func1():
return func2()
def func2():
return func3()
def func3():
return "shit"
"""
这样写会好很多
"""
def step1():
return "yoo"
def step2(v):
return f"hello, {v}"
def step3(v):
return f"you know nothing, {v}"
def main():
r1 = step1()
r2 = step2(r1)
step3(r2)
顺带一提,对于一些无法绕开的外部调用,如网络请求、数据库请求。单元测试的准则之一就是“排除一切外部因素”,你不应该发起任何真正的外部调用的,因为这会引入不可控的数据。正确做法是通过依赖注入 Mock 对象,或者通过 patch 去改写调用的接口对象。
以前写过一篇简介:https://blog.laisky.com/p/unittest-mock/
单元测试应该兼顾黑盒、白盒。你既应该编写面对接口的案例,也应该尽可能的试探内部的实现路径(增加覆盖率)。
你还可以逐渐地把线上遇到的各种 bug 都编写为案例,这些案例会成为项目宝贵的财富,为回归测试提供强有力的支持。而且有这么多测试案例提供保护,coding 的时候也会安心很多。
在单元测试的基础上,人们发展出了 TDD,但是在实践的过程中,发现有些“狡猾的”开发会针对案例的特例进行编程。为此,人们决定应该抛弃形式,回归本源,从方法论的高度来探寻测试的道路。其中光明一方,就是 PBT,试图通过描述问题的实质,来自动生成测试案例。
一篇简介:https://blog.laisky.com/p/pbt-hypothesis/
另一个黑暗的方向就是 Fuzzing,它干脆完全忽略函数的实现,贯彻黑盒到底,通过遗传算法,随机的生成入参,以测试到宇宙尽头的决心,对函数进行死缠烂打,发掘出正常人根本想不到猜不着的犄角旮旯里的 bug。
py 是一门动态解释型语言,使得你几乎可以写出各种想得到的写法,但是能够写和应该写是两回事。虽然 py 支持多样化的写法,但是你还是应该有意识的限制自己的行为,按照一定的规范进行编码,以尽可能的在条件允许的情况下,提高代码的稳健型和可维护性。
一些常见的规范不用多讲,比如:
不要写 magic value,多使用常量(如枚举、或 XXX_VAR_NAME 这种写法) 不同类型的参数或返回不要放在 list 里 尽可能多用 key-value 类型,而不是到处都在用下标取值 尽可能多用不可变类型,函数尽可能做到幂等
此外,“静态化”是一种提高程序可读性和可维护性的重要手段,比如在函数定义时指明 type-hints,写清楚参数和返回值的类型。以及对于 OOP,也可以写出定义明确的的“接口-实现”型代码,比如按照 abc -> BaseClass -> Class -> Instance 的形式进行定义,就会规范很多。
from abc import ABC, abstractmethod, abstractproperty
class ThingsABC(ABC):
@abstractproperty
def etable(self):
pass
class BaseFood(ThingsABC):
etable = True
class BirdABC(ABC):
"""
在抽象类中定义抽象方法和属性,
实例化的时候会自动检查这些抽象方法和方法必须已被实现,否则会抛出一场。
具体实现的方法多种多样,比如直接在类里定义,或者多继承等等
"""
@abstractmethod
def fly(self):
pass
@abstractmethod
def eat(self, food: BaseFood):
pass
class BaseBird(BirdABC):
"""
可以定义一些鸟类都应该有的通用属性和方法
"""
pass
class Robin(BaseBird):
"""
定义一些知更鸟特有的属性和方法
"""
# def fly(self):
# pass
# def eat(self, foold: BaseFood):
# pass
r = Robin() # 会报错,因为没有实现抽象方法
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# in
# 45
# 46
# ---> 47 r = Robin() # 会报错,因为没有实现抽象方法
# TypeError: Can't instantiate abstract class Robin with abstract methods eat, fly
以上就是本篇全部的内容,如果对你有帮助,还希望大家可以点赞分享,谢谢。
推荐阅读
1
2
3
4