
这么简单的游戏还卡壳?神经网络在「生命游戏」里苦苦挣扎
新智元报道
新智元报道
来源:techtalks
编辑:小智、小匀
【新智元导读】生命游戏是一种基于网格的自动机。最近,有研究人员发表了一篇论文,指出尽管这款游戏很简单,但它对神经网络来说,仍是个挑战。他们的论文研究了神经网络是如何「探索」这款游戏的,以及为什么它们会常常错过正确玩法。


什么是生命游戏?


人工神经网络与生命游戏
 雅各布·施普林格,斯沃斯莫尔学院计算机科学专业的学生
雅各布·施普林格,斯沃斯莫尔学院计算机科学专业的学生
大型神经网络的性能
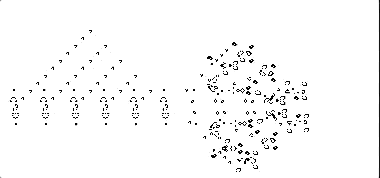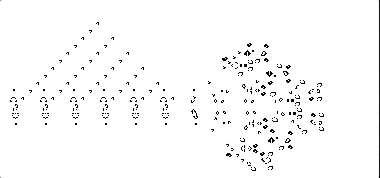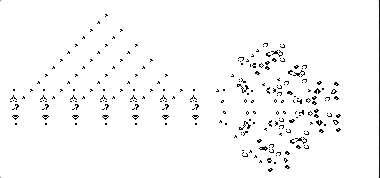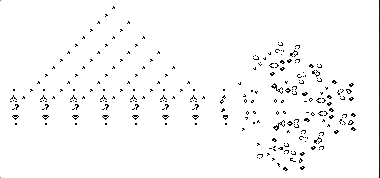
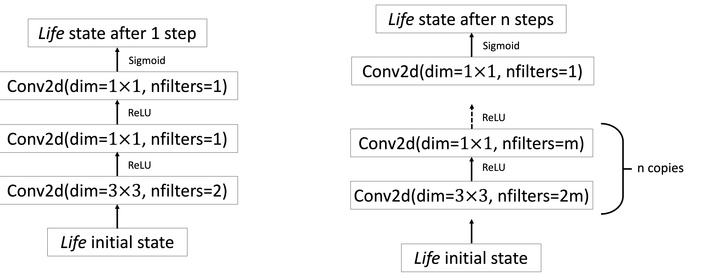 左图: 一个手动调整的卷积神经网络可以非常准确地预测生命游戏的结果。右: 实践中,当从头开始训练网络时,需要一个更大的神经网络来获得同样的结果
左图: 一个手动调整的卷积神经网络可以非常准确地预测生命游戏的结果。右: 实践中,当从头开始训练网络时,需要一个更大的神经网络来获得同样的结果
中关村软件园20周年,品牌活动“创新之源”大会再升级!
9月22日,2020创新之源大会 —“科技力量创变未来”在中关村软件园国际会议中心召开。大会由中关村软件园主办,中关村软件园孵化器、新智元、北京银行共同承办,邀请到清华大学副校长、北京量子信息科学研究院院长薛其坤院士,清华大学电子工程系主任、信息科学技术学院副院长汪玉,科大讯飞联合创始人、讯飞创投董事长徐景明,搜狗公司CEO王小川,网易集团副总裁、网易有道CEO周枫,达闼科技创始人兼CEO黄晓庆,浪潮信息副总裁、浪潮AI&HPC总经理刘军 ,腾讯自动驾驶业务中心总经理苏奎峰,新智元创始人兼CEO杨静等重磅嘉宾出席。
最新议程曝光,扫描二维码即刻报名,资格经审核后可免费参会!点击阅读原文,查看参加会议详细信息!


评论