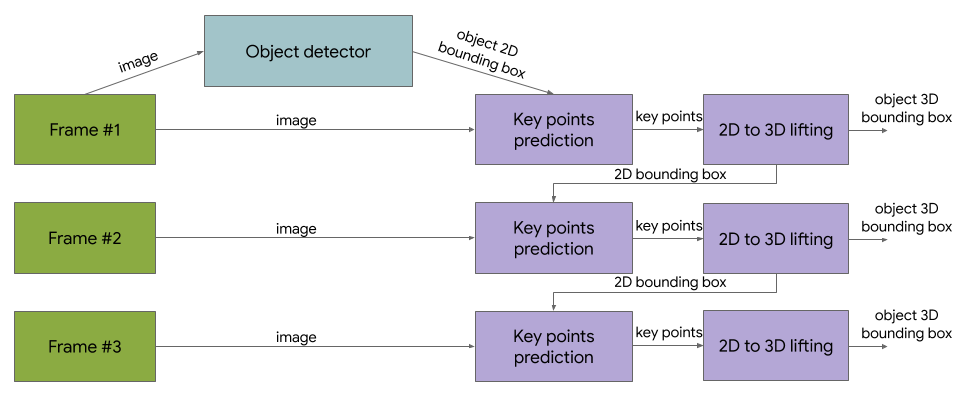
机器学习(ML)的最新技术已经在许多计算机视觉任务上取得了SOTA的结果,但仅仅是通过在2D照片上训练模型而已。 在这些成功的基础上,提高模型对 3D 物体的理解力有很大的潜力来支持更广泛的应用场景,如增强现实、机器人、自动化和图像检索。 今年早些时候,谷歌发布了 MediaPipe Objectron,一套为移动设备设计的实时 3D 目标检测模型,这个模型是基于一个已标注的、真实世界的 3D 数据集,可以预测物体的 3D 边界。
每个视频剪辑都伴随着 AR 会话元数据,其中包括摄像机姿态和稀疏点云。数据还包含为每个对象手动注释的3D 边界,这些 bounding box 描述了对象的位置、方向和尺寸。 每个视频剪辑都随附有 AR 的元数据,其中包括相机姿势和稀疏点云。数据还包含每个对象的手动注释的 3D 边界框,用于描述对象的位置,方向和尺寸。 该数据集包括15K 注释视频剪辑与超过4M 注释图像收集的地理多样性样本(涵盖10个国家横跨五大洲)。
3D 目标检测解决方案
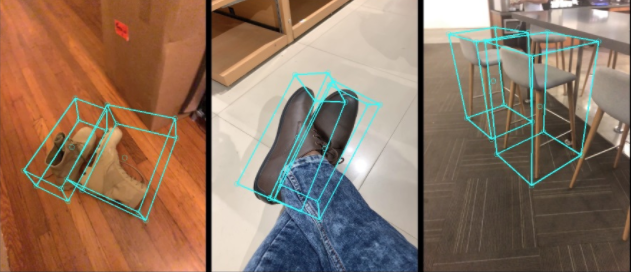
除了这个数据集,谷歌还分享了一个 3D 目标检测解决方案,可以用于4类物体:鞋子、椅子、杯子和相机。 这些模型是在 MediaPipe 中发布的,MediaPipe 是谷歌的开源框架,用于跨平台可定制的流媒体机器学习解决方案,它同时也支持机器学习解决方案,比如设备上的实时手势、虹膜和身体姿态跟踪。






 下载APP
下载APP