
“用魔法击败魔法”?一群计算神经学家正借神经网络解释大脑


Daniel Yamins
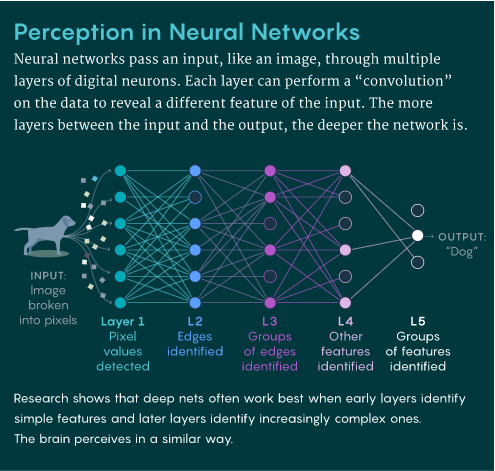
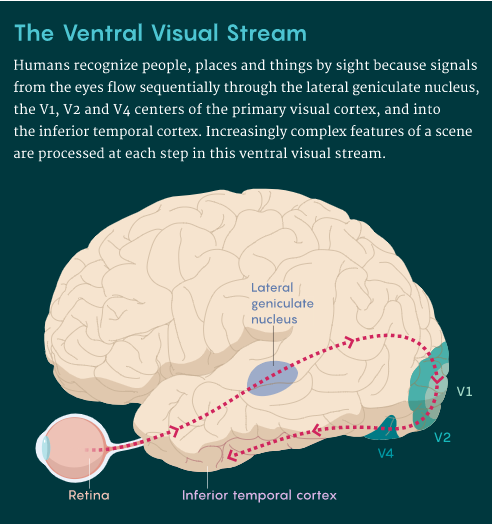
深度神经网络与视觉
深度神经网络与视觉
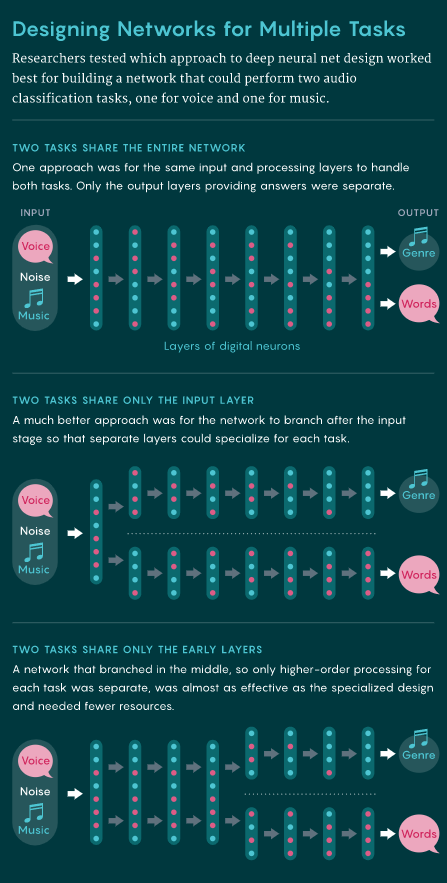
区分声音
区分声音


识别气味
识别气味
这种相似性表明,进化论和深度神经网络都达到最优解。但 Yang 仍然对他们的成绩持谨慎态度。他说:“也许我们只是运气好,也许它没有普适性。”
不只是黑箱
不只是黑箱
模型的局限
模型的局限

实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
评论