
2024,知乎坐实「预言家」
 文 | 阑夕 2017年,知乎在北京地铁刷墙打广告,引用的问题是「人工智能会产生感情吗?」
文 | 阑夕 2017年,知乎在北京地铁刷墙打广告,引用的问题是「人工智能会产生感情吗?」  这也 是Google发布论文「Attention Is All Your Need」的同一年,论文开创性的提出了Transformer架构,直接启发了OpenAI开始构建如今风靡全球的GPT系列产品。 我甚至在知乎上重新找到了那个提问,它的论文或是Transformer都没有关系,却吸引了科幻作家、心理学家、机器学习工程师甚至小鹏汽车官号的回答,角度各有不同且差异巨大,但是汇聚起来,恰好对这个前瞻性的好奇疑问提供了足够丰富的思辨网络。 知乎似乎总是活在叹息里,从邀请制到开放注册是让人叹息的,社区和商业的平衡过程是让人叹息的,要与斑斓多彩的短视频平台竞争用户是让人叹气的,而在诸多叹息的间隙里,像是人工智能会不会有感情这样的讨论,仍然涌现出一股力量。 我愿称之为:认真的力量。 在社区产品里,认真是有回报的,认真能够带来信任,带来专业,以及,知乎想要翻红的一切可能性。 · · · 就在昨天,知乎开完了新一年的发现大会,正式提出了「始于社区,不止于社区」。
这也 是Google发布论文「Attention Is All Your Need」的同一年,论文开创性的提出了Transformer架构,直接启发了OpenAI开始构建如今风靡全球的GPT系列产品。 我甚至在知乎上重新找到了那个提问,它的论文或是Transformer都没有关系,却吸引了科幻作家、心理学家、机器学习工程师甚至小鹏汽车官号的回答,角度各有不同且差异巨大,但是汇聚起来,恰好对这个前瞻性的好奇疑问提供了足够丰富的思辨网络。 知乎似乎总是活在叹息里,从邀请制到开放注册是让人叹息的,社区和商业的平衡过程是让人叹息的,要与斑斓多彩的短视频平台竞争用户是让人叹气的,而在诸多叹息的间隙里,像是人工智能会不会有感情这样的讨论,仍然涌现出一股力量。 我愿称之为:认真的力量。 在社区产品里,认真是有回报的,认真能够带来信任,带来专业,以及,知乎想要翻红的一切可能性。 · · · 就在昨天,知乎开完了新一年的发现大会,正式提出了「始于社区,不止于社区」。  理解知乎的意图不难——社区是根,但光有根是不够的——难的是根上能结出什么果实来, 同行都在百般尝试,失败的社区,会让深埋于土壤里的根茎吸走所有的肥料,就是开不了花、长不出树。 知乎甚至都不需要费心去找参考案例,看它曾经的老师Quora现在是什么下场就知道了,尽管知乎早就甩开Quora了,但Quora沦为一个充斥着引流、暴力、低劣内容的大型垃圾场,还是超出了即使是最悲观者的预期。 Quora的创始人曾在接受「连线」杂志采访时承认2011年是一个「由盛转衰的时间节点」,因为在那一年Quora为了争取B轮融资开始重视数据表现,通过激进的市场推广把月新增用户翻了5倍,但Quora的社区并没有做好迎接揠苗助长的准备,质量一落千丈的同时,也造成了生态上的撕裂。 所以行业里才有「增长是社区的天敌」这种苦笑式的说法。 知乎做得比Quora好,不光是在结果上——至少成功上市了,另一个的估值还在打折中——更重要的是,知乎走了一条多品牌的路线,把本来遭遇的对错题变成了选择题:不是只能接受或者拒绝,而是还有第三种解法。 在我看来,这是知乎这些年里,做得最及时且正确的事情,没有之一。 · · · 去年5月,知乎推出了独立App盐言故事,它的前身,是知乎自2019年就开始在站内分拆运营的短篇阅读业务线,时至今日,有60万人在知乎创作故事,通过用户付费等形式拿到了超过10亿人民币的收入。 在某种程度上,这是知乎对于「海贼-王路飞事件」的解决方案。 众所周知,知乎曾经的传奇用户海贼-王路飞在224个提问里分饰244个角色,从香港皇家警卫队员,到十级伤残的见义勇为者,直到被封号,他的做法都加剧了知乎试图摆脱的那种刻板印象:「分享你刚编的故事」。 事实上,除了为了吸引眼球而自编自演的内容之外,知乎确实存在着一批虚构类作品的创作者,他们会将作品投递到符合题材的提问底下,却在无意中成为了刻板流言的牺牲者,而知乎则意识到与用户群体扩大的风险并存的机会。 于是就有了签约作者平均月入接近万元的盐言故事,这些作品从知乎里走出来,被分发到App以及合作渠道——比如华为阅读、360浏览器、虎扑这些产品里——其中收效出众的,还将得到IP改编的待遇,衍生成短剧、有声书等媒介形式。 此时需要坦诚的是,社区很好,但它作为产品而言不是一个万能的解决方案,可以成为一切内容互动的终点,除了盐言故事之外,知乎还在2023年独立了职业教育品牌知乎知学堂,让社区里那些擅长写故事、擅长卖课的生产者都能得到更加垂直化的服务。 这就是「始于社区,不止于社区」的实操检验。 · · · 刚刚上市的Reddit在招股书里披露,去年有10%的收入——大约6000万美元——来自大模型公司的付款: 交了钱后,才能用Reddit的内容数据训练自家AI。 马斯克在买下推特之后,也将用户推文视为核心资产,不但调高了API的定价,还把针对推特数据的训练权限称作旗下AI产品Gork的独有特权。 甚至是前文提到过的Quora,创始人的自救措施就包括新开发了一款名为Poe的聊天机器人,尽管集成第三方AI产品的模式更像是在和Quora开展竞争。 这些积极拥抱AI的内容平台,有着高度的共同性,那就是它们的体量都相对「适中」,既不算特别大,但也不是毫无名气。 这很容易理解,大的内容平台,比如Facebook或是TikTok,需要维持主营业务的繁荣,贸然增加AI的能力对于它们而言,收益过于模糊,而且容易伤筋动骨,更适合放在母公司去做技术端的开拓。 而小的内容平台,数据存量本就不够,根本就没有坐上牌桌的筹码。 唯独规模居中的内容平台,拥有强烈的动力去追求变化,毫无疑问,知乎也属于这一类,它的中文大模型「知海图AI」已经测试了接近一整年,终于在这次发现大会上被应用到了前端产品里。 但在产品形态上,知乎的AI化,没有走到卖数据这条路上,而创始人周源的想法,则再次让人想起了李开复在投资知乎天使轮时对他的评价:和打法野蛮的市场环境相比,有点担心他们太过文人作风。 不过,可能也只有当过记者的周源,才能理解创作者对于AI爱恨交加的复杂心情,从而设计出一套回馈而非掠夺创作者的AI系统。 · · · 知乎的内容交互,是高度结构化的,一个提问对应多个回答,天然适合大模型训练推理能力。 不过站在用户的需求角度,要找答案,就必须要先找到问题——如果没有现成的,就必须自己来提问,并接受反人性的延迟满足结果——这不是最友好的体验。 所以知乎的AI能力,首先被用在了搜索上,搜索本身是可以用自然语言去提交的,而AI的作用在于,它不必先去找问题了,直接就能从海量的内容库里,追溯到所有的原始回答——哪怕是分散在多个提问底下的——以对话模式返回给用户。
理解知乎的意图不难——社区是根,但光有根是不够的——难的是根上能结出什么果实来, 同行都在百般尝试,失败的社区,会让深埋于土壤里的根茎吸走所有的肥料,就是开不了花、长不出树。 知乎甚至都不需要费心去找参考案例,看它曾经的老师Quora现在是什么下场就知道了,尽管知乎早就甩开Quora了,但Quora沦为一个充斥着引流、暴力、低劣内容的大型垃圾场,还是超出了即使是最悲观者的预期。 Quora的创始人曾在接受「连线」杂志采访时承认2011年是一个「由盛转衰的时间节点」,因为在那一年Quora为了争取B轮融资开始重视数据表现,通过激进的市场推广把月新增用户翻了5倍,但Quora的社区并没有做好迎接揠苗助长的准备,质量一落千丈的同时,也造成了生态上的撕裂。 所以行业里才有「增长是社区的天敌」这种苦笑式的说法。 知乎做得比Quora好,不光是在结果上——至少成功上市了,另一个的估值还在打折中——更重要的是,知乎走了一条多品牌的路线,把本来遭遇的对错题变成了选择题:不是只能接受或者拒绝,而是还有第三种解法。 在我看来,这是知乎这些年里,做得最及时且正确的事情,没有之一。 · · · 去年5月,知乎推出了独立App盐言故事,它的前身,是知乎自2019年就开始在站内分拆运营的短篇阅读业务线,时至今日,有60万人在知乎创作故事,通过用户付费等形式拿到了超过10亿人民币的收入。 在某种程度上,这是知乎对于「海贼-王路飞事件」的解决方案。 众所周知,知乎曾经的传奇用户海贼-王路飞在224个提问里分饰244个角色,从香港皇家警卫队员,到十级伤残的见义勇为者,直到被封号,他的做法都加剧了知乎试图摆脱的那种刻板印象:「分享你刚编的故事」。 事实上,除了为了吸引眼球而自编自演的内容之外,知乎确实存在着一批虚构类作品的创作者,他们会将作品投递到符合题材的提问底下,却在无意中成为了刻板流言的牺牲者,而知乎则意识到与用户群体扩大的风险并存的机会。 于是就有了签约作者平均月入接近万元的盐言故事,这些作品从知乎里走出来,被分发到App以及合作渠道——比如华为阅读、360浏览器、虎扑这些产品里——其中收效出众的,还将得到IP改编的待遇,衍生成短剧、有声书等媒介形式。 此时需要坦诚的是,社区很好,但它作为产品而言不是一个万能的解决方案,可以成为一切内容互动的终点,除了盐言故事之外,知乎还在2023年独立了职业教育品牌知乎知学堂,让社区里那些擅长写故事、擅长卖课的生产者都能得到更加垂直化的服务。 这就是「始于社区,不止于社区」的实操检验。 · · · 刚刚上市的Reddit在招股书里披露,去年有10%的收入——大约6000万美元——来自大模型公司的付款: 交了钱后,才能用Reddit的内容数据训练自家AI。 马斯克在买下推特之后,也将用户推文视为核心资产,不但调高了API的定价,还把针对推特数据的训练权限称作旗下AI产品Gork的独有特权。 甚至是前文提到过的Quora,创始人的自救措施就包括新开发了一款名为Poe的聊天机器人,尽管集成第三方AI产品的模式更像是在和Quora开展竞争。 这些积极拥抱AI的内容平台,有着高度的共同性,那就是它们的体量都相对「适中」,既不算特别大,但也不是毫无名气。 这很容易理解,大的内容平台,比如Facebook或是TikTok,需要维持主营业务的繁荣,贸然增加AI的能力对于它们而言,收益过于模糊,而且容易伤筋动骨,更适合放在母公司去做技术端的开拓。 而小的内容平台,数据存量本就不够,根本就没有坐上牌桌的筹码。 唯独规模居中的内容平台,拥有强烈的动力去追求变化,毫无疑问,知乎也属于这一类,它的中文大模型「知海图AI」已经测试了接近一整年,终于在这次发现大会上被应用到了前端产品里。 但在产品形态上,知乎的AI化,没有走到卖数据这条路上,而创始人周源的想法,则再次让人想起了李开复在投资知乎天使轮时对他的评价:和打法野蛮的市场环境相比,有点担心他们太过文人作风。 不过,可能也只有当过记者的周源,才能理解创作者对于AI爱恨交加的复杂心情,从而设计出一套回馈而非掠夺创作者的AI系统。 · · · 知乎的内容交互,是高度结构化的,一个提问对应多个回答,天然适合大模型训练推理能力。 不过站在用户的需求角度,要找答案,就必须要先找到问题——如果没有现成的,就必须自己来提问,并接受反人性的延迟满足结果——这不是最友好的体验。 所以知乎的AI能力,首先被用在了搜索上,搜索本身是可以用自然语言去提交的,而AI的作用在于,它不必先去找问题了,直接就能从海量的内容库里,追溯到所有的原始回答——哪怕是分散在多个提问底下的——以对话模式返回给用户。 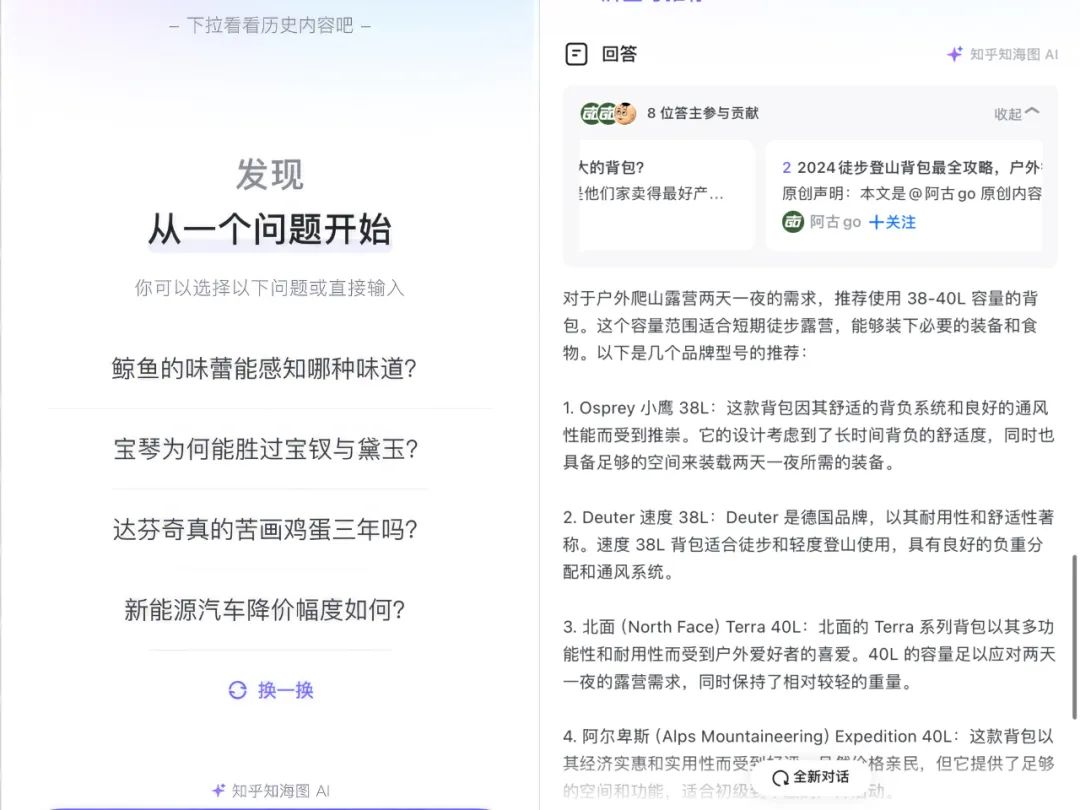 最关键的是,这些内容的出处都会准确指向对应的知乎答主,无论AI如何咀嚼吞吐数据,都不会抹掉来源,反而会引导用户关注答主。 其实创作者并不会排斥新的技术应用,他们要的只是不遭背刺而已,知乎也表现出了对于AI的定性:增益社区,放大价值。 这和行业里的普遍做法不太一样,迄今为止,我都没有看到知乎推出类似总结机器人的功能,而在很多其他的内容平台,为了满足太长不看的用户需要,只要@官方开发的AI账号,就能立刻召唤出现回贴,把正文内容精简一番,哪怕是驴唇不对马嘴。 而知乎唯一上线过的官方AI机器人服务,叫作瓦力,是基于NLP算法实现的治理工具,用于解决社区里辱骂、扣帽子、甚至答非所问的内容,它本身并不会在社区的内容生态里表现出存在感。 我的意思是,从这样的差别里,不难看出知乎驾驭AI的态度和方向,因为尊重创作者,所以绝对不会让AI去抢创作者的饭碗,它的一切目的,都是为了提升内容的流通效率,以及增进来自用户的信任——不是信任当前仍未克服幻觉问题的AI,而是信任社区和人。 · · · 在写「沸腾新十年」时,林军老师讲过周源的一段往事。 2010年,在一手创办的企业搜索营销公司Meta倒闭之后,郁闷的周源去了西藏旅行,一个朋友发来这么一条短信安慰他: 「人并不是仅仅在寻求结果,如果只是为了寻求结果,人是很容易走捷径的。在走捷径的过程中,人会很容易迷失真实,甚至连满腔的热忱也会逐渐丧失。我认为真正重要的是追求真实的意志。只要有了这种向真实前进的意志,即使这次失败了,我们也终于会达到终点。」 知乎当初正是周源从西藏回来之后成立的,十几年时光倏忽而过,知乎从一个饭局点子成了一家上市公司,同时也经历了想不到的坎坷。 只要周源还在追求知乎的所谓真实意志,无论这个真实意志是被看作一个可信赖的平台还是别的什么,知乎都还有翻红的机会。 因为知识,从来都是稀缺的,供应知识的生意,只有长期主义才兜得住。
最关键的是,这些内容的出处都会准确指向对应的知乎答主,无论AI如何咀嚼吞吐数据,都不会抹掉来源,反而会引导用户关注答主。 其实创作者并不会排斥新的技术应用,他们要的只是不遭背刺而已,知乎也表现出了对于AI的定性:增益社区,放大价值。 这和行业里的普遍做法不太一样,迄今为止,我都没有看到知乎推出类似总结机器人的功能,而在很多其他的内容平台,为了满足太长不看的用户需要,只要@官方开发的AI账号,就能立刻召唤出现回贴,把正文内容精简一番,哪怕是驴唇不对马嘴。 而知乎唯一上线过的官方AI机器人服务,叫作瓦力,是基于NLP算法实现的治理工具,用于解决社区里辱骂、扣帽子、甚至答非所问的内容,它本身并不会在社区的内容生态里表现出存在感。 我的意思是,从这样的差别里,不难看出知乎驾驭AI的态度和方向,因为尊重创作者,所以绝对不会让AI去抢创作者的饭碗,它的一切目的,都是为了提升内容的流通效率,以及增进来自用户的信任——不是信任当前仍未克服幻觉问题的AI,而是信任社区和人。 · · · 在写「沸腾新十年」时,林军老师讲过周源的一段往事。 2010年,在一手创办的企业搜索营销公司Meta倒闭之后,郁闷的周源去了西藏旅行,一个朋友发来这么一条短信安慰他: 「人并不是仅仅在寻求结果,如果只是为了寻求结果,人是很容易走捷径的。在走捷径的过程中,人会很容易迷失真实,甚至连满腔的热忱也会逐渐丧失。我认为真正重要的是追求真实的意志。只要有了这种向真实前进的意志,即使这次失败了,我们也终于会达到终点。」 知乎当初正是周源从西藏回来之后成立的,十几年时光倏忽而过,知乎从一个饭局点子成了一家上市公司,同时也经历了想不到的坎坷。 只要周源还在追求知乎的所谓真实意志,无论这个真实意志是被看作一个可信赖的平台还是别的什么,知乎都还有翻红的机会。 因为知识,从来都是稀缺的,供应知识的生意,只有长期主义才兜得住。 
评论