
谷歌、亚马逊的顶级GPU被质疑太贵了!这种CPU算法竟然快15倍

新智元报道
新智元报道
来源:外媒等
编辑:LZY
【新智元导读】赖斯大学的计算机科学家创造了一种替代GPU的方法,该算法使用通用中央处理器(CPU),并指出其训练深度神经网络(DNN) 的速度超过图形处理器平台(GPU)速度的15倍。到底是怎么回事呢,我们一起来看看!
赖斯布朗工程学院的计算机科学助理教授安舒玛利·史里瓦斯塔瓦(Anshumali Shrivastava)认为人工智能的瓶颈取决于如何训练AI的工作负载。
赖斯(Rice)和英特尔(Intel)的合作者们在4月8日的机器学习系统大会MLSys上针对这一瓶颈提出了研究。
深度神经网络是什么?
深度神经网络是什么?
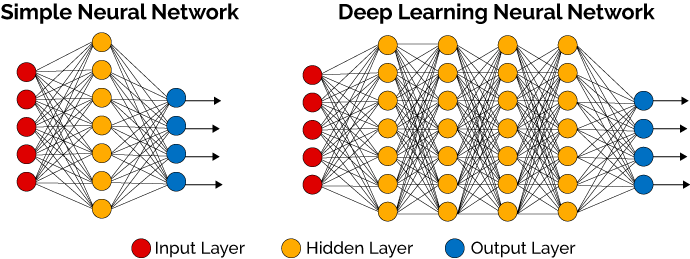
深度神经网络(DNN)是一种强大的人工智能形式,在执行某些任务上甚至可以胜过人类。神经网络是基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。DNN有时也叫做多层感知机(Multi-Layer perceptron, MLP)。
按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层。
如下图右边示例,一般来说第一层红色的是输入层,最后一层蓝色的是输出层,而中间的黄色的层数都是隐藏层。
训练DNN通常是需要一系列矩阵乘法的运算。
GPU的成本是通用中央处理单元(CPU)的三倍左右。
如图所示,左侧为GPU,最初用在个人电脑、工作站、游戏机和一些移动设备上运行绘图运算工作的微处理器。
右侧为CPU,简而言之,就是机器的“大脑”。是完成布局谋略、发号施令、控制行动的「总司令官」。


因为整个行业都专注于寻求一种更快的矩阵乘法,GPU是一种称为「亚线性深度学习引擎」(SLIDE)的算法,该算法使用通用中央处理器(CPU),无需专门的加速硬件就可实现。
现在,为了实现不同种类的深度学习,人们也会挑选专门的硬件和软件。与其花更多的钱用于算法开发,人们更愿意投入整个系统的优化升级,也就是研究一下原来的算法。
Shrivastava的实验室在2019年做到了这一点,借助SLIDE,DNN被训练为可以通过哈希表搜索问题的深度网络形式。
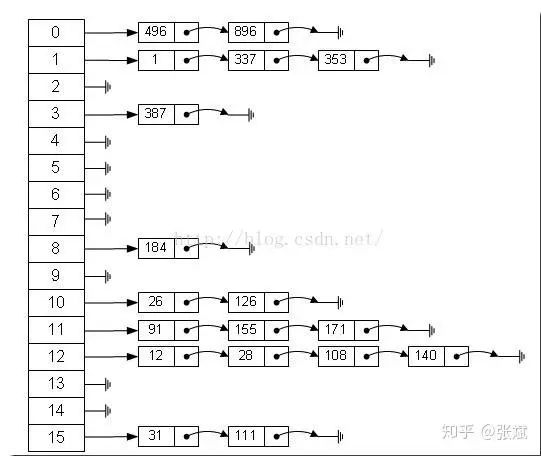
哈希表(Hash table) 又称为散列表,如下图所示. 我们可以根据键(Key)可直接访问内存的数据结构。
(图源见水印)
也就是说,它通过一个关于键值的函数,将所需查询的数据映射到表中一个位置来添加访问记录,这能大大加快查找速度。
与反向传播训练相比,这也从根本上减少了SLIDE的计算开销。
像亚马逊,谷歌和其他公司提供的基于云的深度学习服务的顶级GPU平台相当于八台Tesla V100,价格约为100,000美元,其实这是很大的一笔开销。

CPU大战GPU
英特尔的Shrivastava及其合作者在MLSys 2020上展示其性能时发现CPU算法训练深度神经网络的速度比顶级GPU训练器还要快15倍。
下图是CPU和GPU的对比。

从这个架构图,我们就能明显看出,GPU的构成相对简单,有数量众多的计算单元和超长的流水线,CPU有强大的ALU(算术运算单元),它可以在很少的时间周期内完成算数计算。
在2021 MLSys上合作者又提出探讨:「是否SLIDE的表现可以随着现代CPU内存的优化而越来愈?」
所以未来我们不能拘泥于矩阵乘法,而是可以利用现代CPU的强大功能,用快4至15倍的速度训练其他的AI模型,希望通过这些创新进一步推动SLIDE的发展
研究者莱斯大学本科生尼古拉斯·梅斯堡尔(Nicholas Meisburger)也表示CPU仍然是计算中最流行的硬件。我们要好好利用起来!
参考资料:
https://techxplore.com/news/2021-04-rice-intel-optimize-ai-commodity.html

