
项目实战 01:将唐诗三百首写入 Elasticsearch 会发生什么?
1、实战项目
将唐诗三百首写入Elasticsearch会发生什么?
2、项目说明
此项目是根据实战项目浓缩的一个小项目,几乎涵盖之前讲解的所有知识点。
通过这个项目的实战,能让你串联起之前的知识点应用于实战,并建立起需求分析、整体设计、数据建模、ingest管道使用、检索/聚合选型、kibana可视化分析等的全局认知。
3、 需求
数据来源:https://github.com/xuchunyang/300
注意数据源bug: 第1753行种的"id":178 需要手动改成 "id": 252。
3.1 数据需求
注意:
1)词典选择 2)分词器选型 3)mapping设置 4)支持的目标维度考量 5)设定插入时间(自定义动态添加,非人工)
3.2 写入需求
注意:
1)特殊字符清洗 2)新增插入时间
3.3 分析需求
检索分析DSL实战
1)飞花令环节:包含铭 毅 天下(分别包含)诗句有哪些?各有多少首? 2)李白的诗有几首?按照诗长短排序,由短到长 3)取TOP10最长、最短的诗的作者列表
聚合分析实战及可视化实战
1)三百首谁的作品最多?取TOP10排行 2)五言绝句和七言律诗占比,以及对应作者占比统计 3)同名诗排行统计 4)三百首诗分词形成什么样的词云
4、 需求解读与设计
4.1 需求解读
本着:编码之前,设计先行的原则。
开发人员的通病——新的项目拿到需求以后,不论其简单还是复杂,都要先梳理需求,整理出其逻辑架构,优先设计,以便建立全局认知,而不是上来就动手敲代码。
本项目的核心知识点涵盖如下几块内容
Elasticsearch 数据建模 Elasticsearch bulk批量写入 Elasticsearch 预处理 Elasticsearch检索 Elasticsearch聚合 kibana Visualize 使用 kibana Dashboard 使用
4.2 逻辑架构梳理
有图有真相。

根据需求梳理出如下的逻辑架构,实际开发中要谨记如下的数据流向。
4.3 建模梳理
之前也有讲述,这里再强调一下数据建模的重要性。
数据模型支撑了系统和数据,系统和数据支撑了业务系统。
一个好的数据模型:
能让系统更好的集成、能简化接口。 能简化数据冗余、减少磁盘空间、提升传输效率。 兼容更多的数据,不会因为数据类型的新增而导致实现逻辑更改。 能帮助更多的业务机会,提高业务效率。 能减少业务风险、降低业务成本。
对于Elasticsearch的数据建模的核心是Mapping的构建。
对于原始json数据:
"id": 251,"contents": "打起黄莺儿,莫教枝上啼。啼时惊妾梦,不得到辽西。","type": "五言绝句","author": "金昌绪","title": "春怨"
我们的建模逻辑如下:
| 字段名称 | 字段类型 | 备注说明 |
|---|---|---|
| _id | 对应自增id | |
| contents | text & keyword | 涉及分词,注意开启:fielddata:true |
| type | text & keyword | |
| author | text & keyword | |
| title | text & keyword | |
| timestamp | date | 代表插入时间 |
| cont_length | long | contents长度, 排序用 |
由于涉及中文分词,选型分词器很重要。
这里依然推荐:选择ik分词。
ik词典的选择建议:自带词典不完备,网上搜索互联网的一些常用语词典、行业词典如(诗词相关词典)作为补充完善。
4.4 概要设计
原始文档json的批量读取和写入通过 elasticsearch python低版本 api 和 高版本 api elasticsearch-dsl 结合实现。 数据的预处理环节通过 ingest pipeline实现。设计数据预处理地方:每一篇诗的json写入时候,插入timestamp时间戳字段。 template和mapping的构建通过kibana实现。 分词选型:ik_max_word 细粒度分词,以查看更细粒度的词云。
5、项目实战
5.1 数据预处理ingest
创建:indexed_at 的管道,目的:
新增document时候指定插入时间戳字段。 新增长度字段,以便于后续排序。
PUT _ingest/pipeline/indexed_at{"description": "Adds timestamp to documents","processors": [{"set": {"field": "_source.timestamp","value": "{{_ingest.timestamp}}"}},{"script": {"source": "ctx.cont_length = ctx.contents.length();"}}]}
5.2 Mapping和template构建
如下DSL,分别构建了模板:my_template。
指定了settings、别名、mapping的基础设置。
模板的好处和便捷性,在之前的章节中有过详细讲解。
PUT _template/my_template{"index_patterns": ["some_index*"],"aliases": {"some_index": {}},"settings": {"index.default_pipeline": "indexed_at","number_of_replicas": 1,"refresh_interval": "30s"},"mappings": {"properties": {"cont_length":{"type":"long"},"author": {"type": "text","fields": {"field": {"type": "keyword"}},"analyzer": "ik_max_word"},"contents": {"type": "text","fields": {"field": {"type": "keyword"}},"analyzer": "ik_max_word","fielddata": true},"timestamp": {"type": "date"},"title": {"type": "text","fields": {"field": {"type": "keyword"}},"analyzer": "ik_max_word"},"type": {"type": "text","fields": {"field": {"type": "keyword"}},"analyzer": "ik_max_word"}}}}PUT some_index_01
5.3 数据读取与写入
通过如下的python代码实现。注意:
bulk批量写入比单条写入性能要高很多。 尤其对于大文件的写入优先考虑bulk批量处理实现。
def read_and_write_index():# define an empty list for the Elasticsearch docsdoc_list = []# use Python's enumerate() function to iterate over list of doc stringsinput_file = open('300.json', encoding="utf8", errors='ignore')json_array = json.load(input_file)for item in json_array:try:# convert the string to a dict object# add a new field to the Elasticsearch docdict_doc = {}# add a dict key called "_id" if you'd like to specify an ID for the docdict_doc["_id"] = item['id']dict_doc["contents"] = item['contents']dict_doc["type"] = item['type']dict_doc["author"] = item['author']dict_doc["title"] = item['title']# append the dict object to the list []doc_list += [dict_doc]except json.decoder.JSONDecodeError as err:# print the errorsprint("ERROR for num:", item['id'], "-- JSONDecodeError:", err, "for doc:", dict_doc)print("Dict docs length:", len(doc_list))try:print ("\nAttempting to index the list of docs using helpers.bulk()")# use the helpers library's Bulk API to index list of Elasticsearch docsresp = helpers.bulk(client,doc_list,index = "some_index",doc_type = "_doc")# print the response returned by Elasticsearchprint ("helpers.bulk() RESPONSE:", resp)print ("helpers.bulk() RESPONSE:", json.dumps(resp, indent=4))except Exception as err:# print any errors returned w## Prerequisiteshile making the helpers.bulk() API callprint("Elasticsearch helpers.bulk() ERROR:", err)quit()
5.4 数据分析
5.5 检索分析
5.5.1 飞花令环节:包含铭 毅 天下(分别包含)诗句有哪些?各有多少首?
GET some_index/_search{"query": {"match": {"contents": "铭"}}}GET some_index/_search{"query": {"match": {"contents": "毅"}}}GET some_index/_search{"query": {"match": {"contents": "天下"}}}
实践表明:
铭:0首 毅:1首 天下:114 首
不禁感叹:唐诗先贤们也是心怀天下,忧国忧民啊!
5.5.2 李白的诗有几首?按照诗长短排序,由短到长
POST some_index/_search{"query": {"match_phrase": {"author": "李白"}},"sort": [{"cont_length": {"order": "desc"}}]}POST some_index/_search{"aggs": {"genres": {"terms": {"field": "author.keyword"}}}}
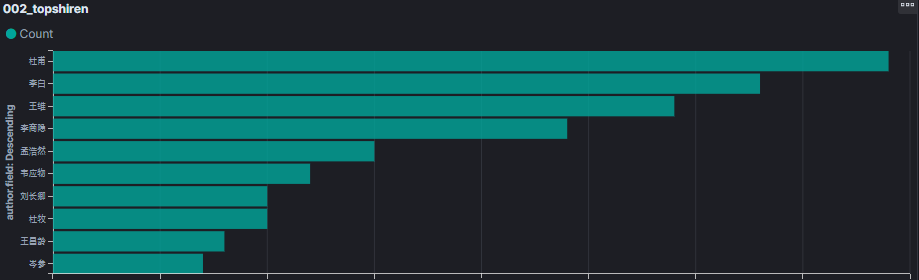
唐诗三百首中,李白共33首诗(仅次于杜甫39首),最长的是“蜀道难”,共:353 个字符。
李白、杜甫不愧为:诗仙和诗圣啊!也都是高产诗人!
5.5.3 取TOP10最长、最短的诗的作者列表
POST some_index/_search{"sort": [{"cont_length": {"order": "desc"}}]}POST some_index/_search{"sort": [{"cont_length": {"order": "asc"}}]}
最长的诗:白居易-长恨歌-960个字符。
最短的诗:王维-鹿柴- 24个字符(并列的非常多)。
5.6 聚合分析
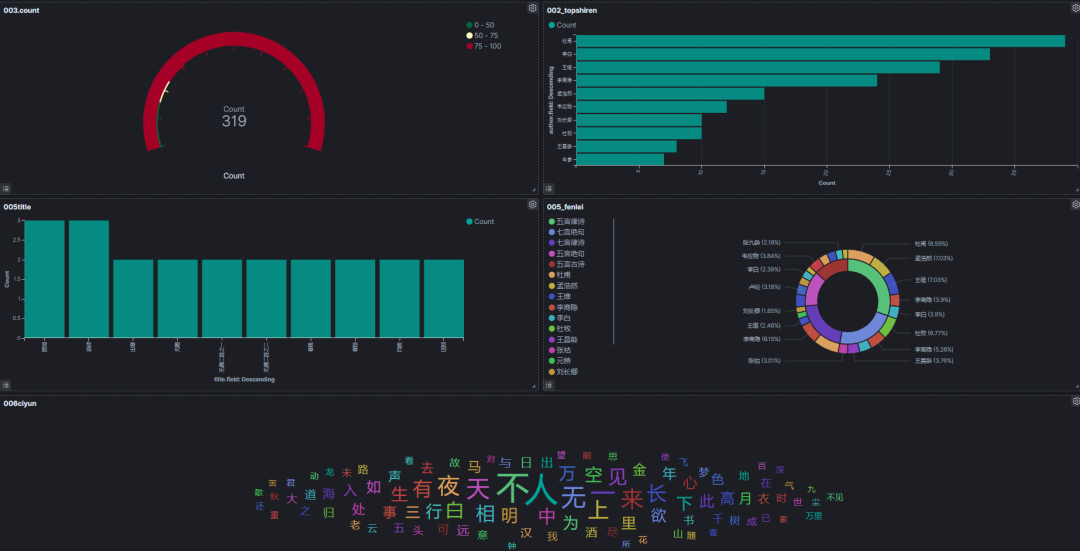
以下的截图通过kibana实现。细节在之前的kibana可视化中都有过讲解。
5.6.1 三百首谁的作品最多?取TOP10排行
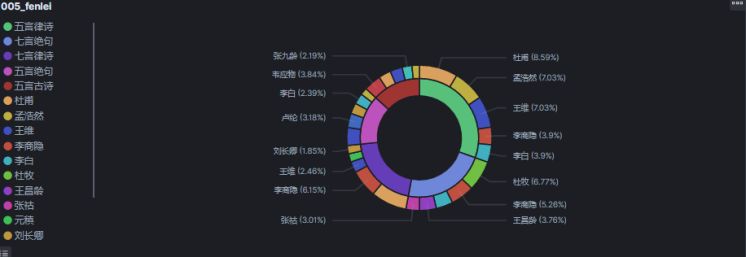
5.6.2 五言绝句和七言律诗占比,以及对应作者占比统计
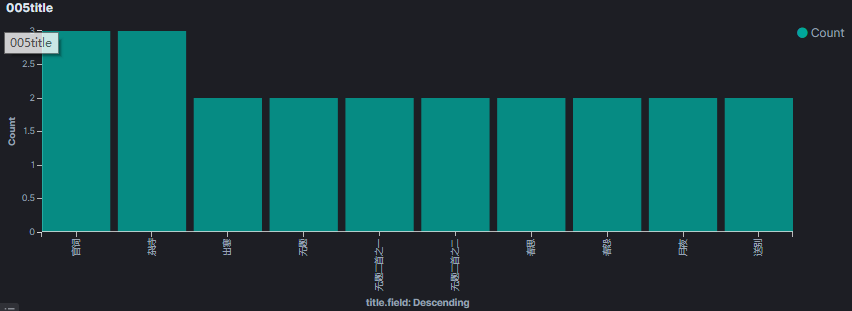
5.6.3 同名诗排行统计
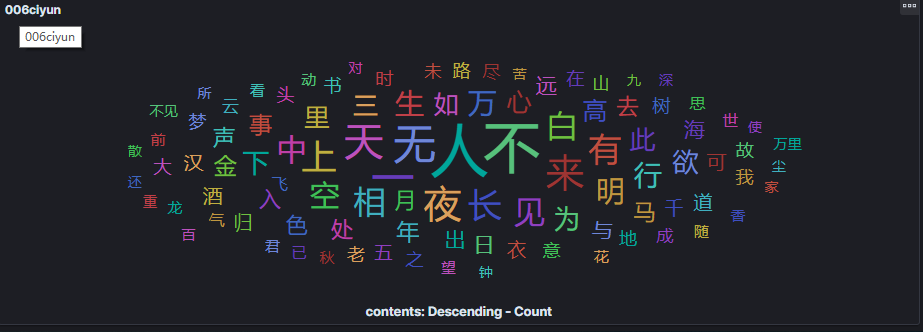
5.6.4 三百首诗分词形成什么样的词云
5.6.5 全局视图
6、小结
结合唐诗300首的业务场景,结合本小项目的需求、设计、实现三个阶段,建立起对Elasticsearch、kibana核心知识点的全局认识。
更短时间更快习得更多干货!
中国40%+Elastic认证工程师出自于此!