计算存储分离在消息队列上的应用



JCQ全名JD Cloud Message Queue,是京东智联云自研,具有CloudNative特性的分布式消息中间件。 JCQ设计初衷即为适应云特性的消息中间件,具有高可用、数据可靠性、副本物理隔离、服务自治、健康状态汇报、少运维或无运维、容器部署、弹性伸缩、租户隔离、按量付费、云账户体系、授权等特性。

JCQ早在2017年中开始开发1.0版本,2018年11月正式GA上线对外售卖。但1.0版本中Topic受限于单台服务器限制,满足不了用户超大规格Topic需求。
因此,我们在2.0 版本中着重解决扩缩容问题。2019年4月 JCQ 2.0 正式上线,主要新增特性就是Topic 扩缩容能力、热点Topic在Broker间的负载均衡、热点Broker的流量转移。
2019年7月,JCQ又做了一次大的架构演进——计算存储分离,大版本号为JCQ 3.0, 于2019年底上线。计算存储分离对架构带来了比较明显的好处,解决了日常遇到的许多痛点问题。
下文将详细介绍此次演进带来的优势以及解决了哪些痛点问题:

在JCQ2.0中计算模块与存储模块处于同一个进程,升级计算模块势必将存储模块一起升级。而存储模块重启是比较重的动作,需要做的工作有:加载大量数据、进行消息数据与消息索引数据比对、脏数据截断等操作。往往修复计算模块一个小的Bug,就需要做上述非常重的存储模块重启。而在现实工作中,大部分升级工作都是由于计算模块功能更新或Bugfix引起的。
为了解决这个问题, JCQ3.0将计算模块、存储模块独立部署,之间通过RPC调用。各自升级互不影响。如下图所示:
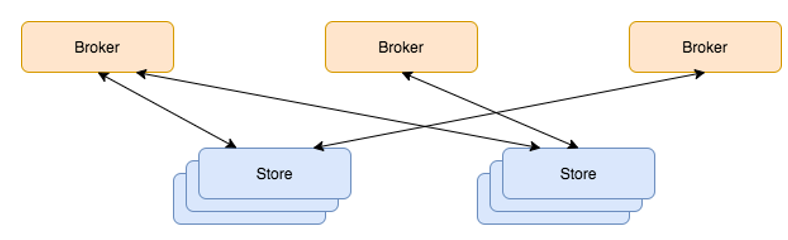
计算节点Broker只负责生产消息、推送消息、鉴权、认证、限流、拥塞控制、客户端负载均衡等业务逻辑,属于无状态服务。比较轻量,升级速度快。
存储节点Store只负责数据写入、副本同步、数据读取。因为业务逻辑简单,功能稳定后,除优化外基本无需改动,也就无需升级。

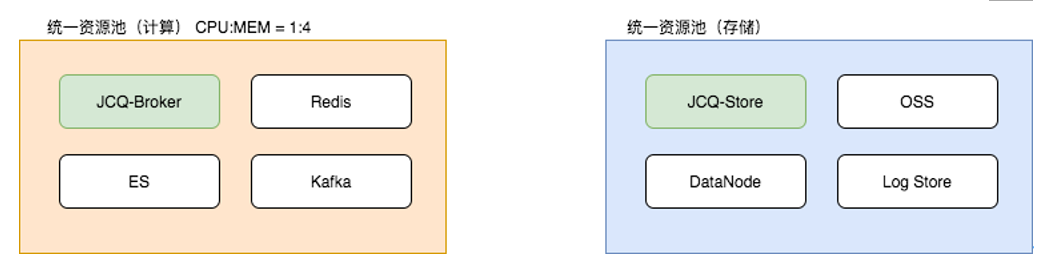
JCQ是共享消息中间件,用户申请的是不同规格TPS的Topic,并不感知CPU、Memory、Disk等硬件指标。所以,JCQ服务方需要考虑如何合理使用这些硬件指标。
JCQ通过容器部署,有多种类型的组件,这些组件对硬件的需求也是多样化的,其中对资源消耗最多的是计算模块和存储模块。在JCQ2.0版本中,计算模块和存储模块部署在一起,选择机型时要兼顾CPU、Memory、Disk等指标,机型要求单一,很难与其他产品线混合部署。即使是同一资源池,也存在因为调度顺序,造成调度失败的情况。如一台机器剩余资源恰好能调度一个需要大规格磁盘的A容器,但是因为B容器先被调度到这台机器上,剩余资源就不够创建一个A容器,那这台机器上的磁盘就浪费了。
JCQ3.0后,计算节点Broker与存储节点Store独立部署,这两个组件可以各自选择适合自己业务的机型,部署在相应资源池中。这样JCQ可以做到与其他产品混合部署,共用资源池水位,而不用独自承担资源水位线。

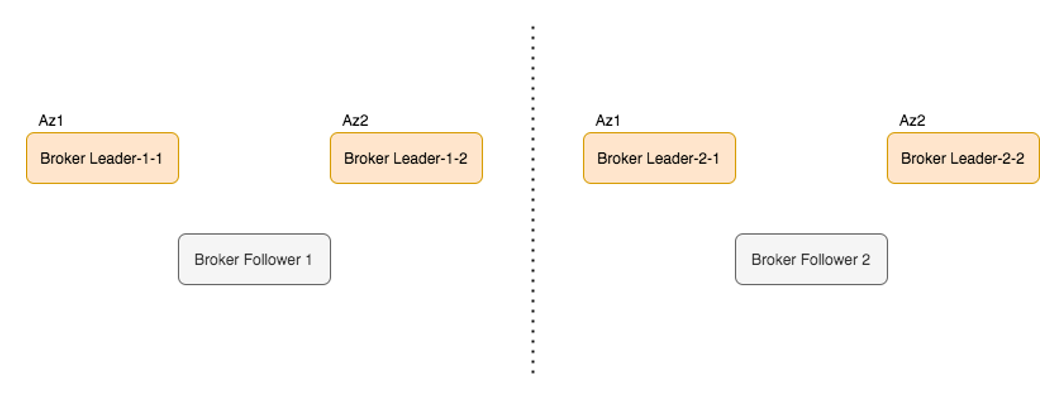
JCQ3.0中计算节点Broker是无状态服务,主从切换比较轻量,能在秒级完成故障转移;且部署时考虑了物理设备反亲和,如跨Rack、跨AZ部署。所以,可以在可用性、资源成本之间做一定的权衡。如可以使用M:1方式做高可用冷备,而不必1:1的比例高可用冷备,进而达到节省硬件资源的目的。

JCQ 1.0 设计之初就采用Raft算法,来解决服务高可用、数据一致性的问题。Message Log与Raft Log 有很多共同的特性,如顺序写、随机读、末端热数据。所以,直接用Raft Log当成Message Log是非常合适的。
在JCQ演进中我们也发现了Raft本身的一些性能问题,如顺序复制、顺序commit、有的流程只能用单线程处理等限制。针对这些问题,最直接有效的办法就是扩展Raft的数目、扩展单线程流程数目,在一定数量级内,并发能力随着Raft Group数目的增长,呈线性增长关系,称之MultiRaft,如下图所示:
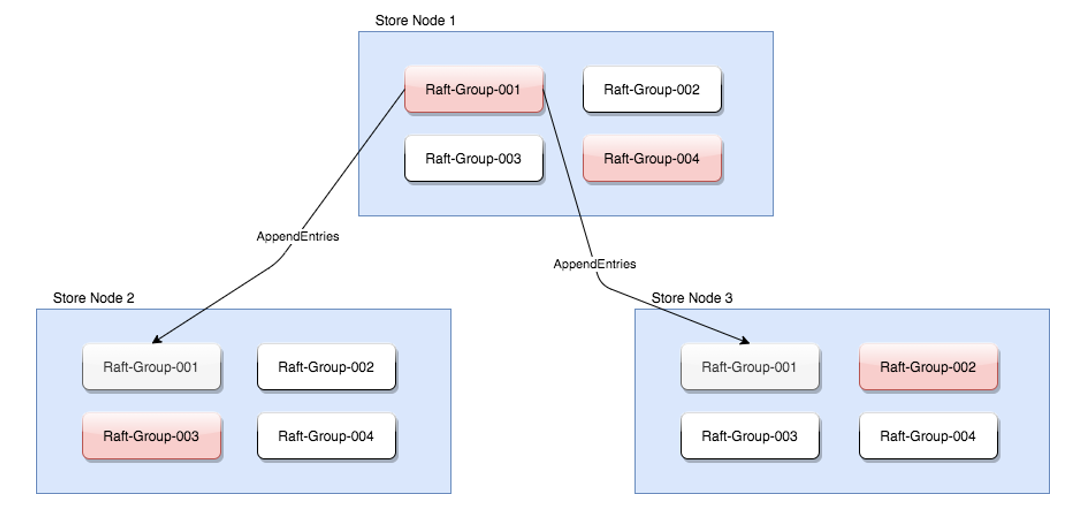
上图中,每个StoreNode节点是一个独立进程,内部有四组逻辑RaftGroup(橙色的节点为RaftGroup的Leader),各组RaftGroup之间是并行关系,可以做到Group间并行复制、并行commit。
由于大量使用了NIO,这些RaftGroup之间可以共享通信线程池,扩充RaftGroup数目并不会带来线程资源线性增长的问题。

在JCQ3.0中,Broker为轻量的无状态服务,在主从切换、故障恢复方面相对2.0更为轻量,本身能更快地恢复对外服务能力。
同时,Broker将Producer、Consumer的连接请求,抽象为PubTask和SubTask,后文统称为Task。Task的概念非常轻量,仅描述Client与Broker的对应关系,由元数据管理器Manager统一调度、管理。转移Task只需要修改Task的内容,客户端重新连接新Broker即可。
一般来说,Broker的主要瓶颈在于网络带宽。Broker定期统计网络入口流量与出口流量,并上报给管理节点Manager。Manager根据入口流量、出口流量与带宽阈值进行裁决,发现超过阈值后,通过一定策略将相应的Task转移到较小负载的Broker上,并通知相应的Producer与Consumer;Producer与Consumer收到通知后,重新获取Task的路由信息,自动重连到新的Broker继续进行生产、消费。
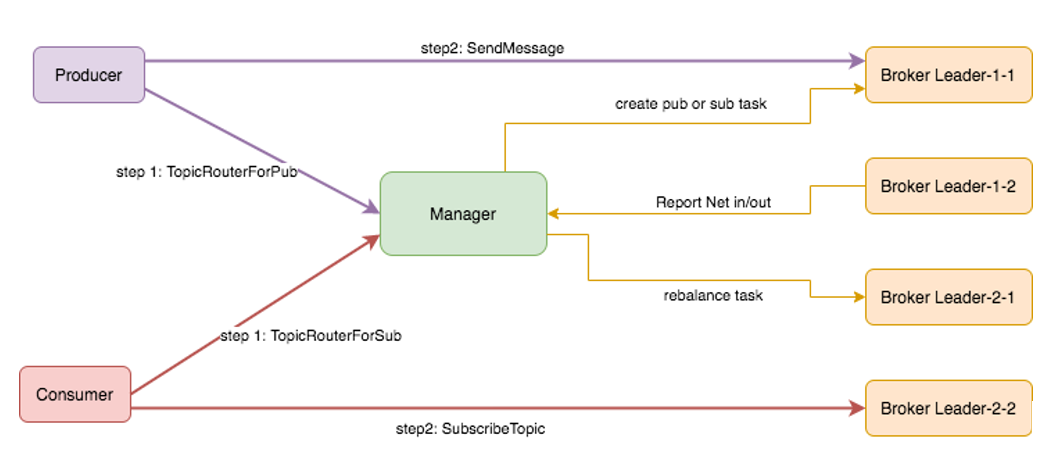

设想一个场景,有一个大规格的Topic,创建了n个消费组。消费总TPS是生产总TPS的n倍。增加消费组,会导致消费总TPS线性增长。到达一定消费组规模后,单Broker由于网卡带宽的原因,无法满足这种高扇出的场景。单服务器是无法解决这个问题。
在JCQ 3.0 可以将这些不同的消费组对应的SubTask分散到若干个Broker上,每个Broker负责一部分SubTask,单Broker从Store预读消息,将数据推送给Consumer。这样多个Broker共同完成所有消费组的消息流量,协作一起提供高扇出的能力。

消息中间件很大的特点是:大部分场景下,热数据都在末端,而回溯几天之前的消息这个功能是不常用的。所以,就有冷热数据之分。
JCQ 计算节点设计了一层存储抽象层Store Bridge 可以接入不同的存储引擎,可以接入Remote Raft Cluster,或者分布式文件系统WOS、或者S3。甚者可以将冷数据定期从昂贵的本地盘卸载到廉价的存储引擎上。
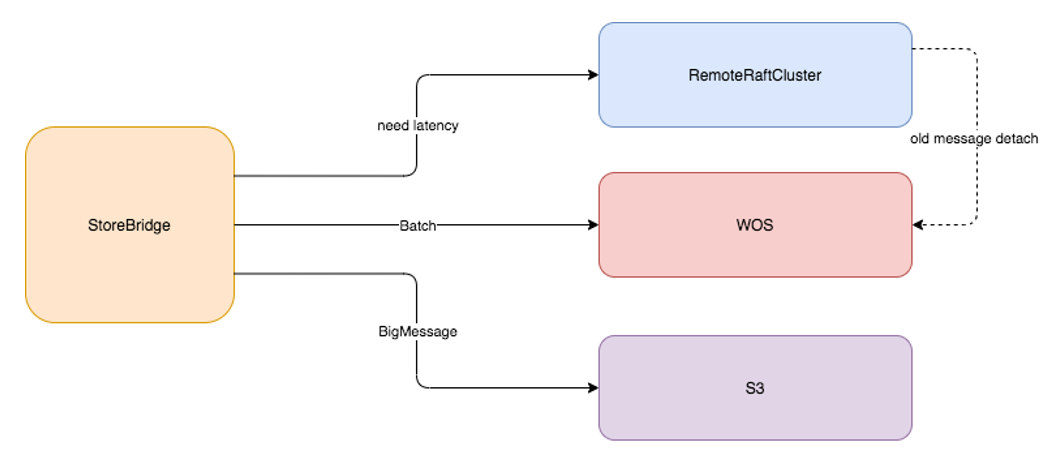

相对于JCQ2.0,计算节点与存储节点之间的通信方式,由接口调用变为RPC调用,在延迟方面会有一定损失。经过测试,绝大部分延迟都在1ms左右,在大多数场景下牺牲1ms左右的延迟并不会给业务带来太大的影响。

JCQ未来会主要在多协议兼容,按需自动扩缩容、云原生等方面演进:

目前JCQ协议为私有协议,在引导用户迁移方面有比较大的障碍。后续会抽离JCQ Kernel,外部提供不同的协议接入层。方便用户从其他MQ接入JCQ。

JCQ是共享消息中间件,但缺少Serverless自动扩缩容的特性。每逢大促,如618,11.11,服贸会等重要活动。业务方很难预估自己的业务量峰值,或者估计不足,会造成topic限流等问题。如在保证JCQ服务本身能力情况下,能做到Topic灵活地自动扩缩容,将对用户有极大的帮助,起到真正的削峰填谷作用。

未来会支持在Kubernetes环境部署与交付,会提供原生的Operator,能快速的部署在K8s环境中,更好的交付私有云、混合云项目。