
充气WaWa什么感觉?Python 告诉你!
点击“开发者技术前线”,选择“星标?”
在看|星标|留言, 真爱

授权来自公众号:裸睡的猪
一、需求背景
在实际开发过程中,在我们动手开发之前,都是由产品经理为我们(测试、前端、后端、项目经理等)先讲解一下需求,我们了解了需求之后,才开始一起来讨论技术方案。
我们自己实现一些小功能时同样需要讨论需求,也就是告诉别人我们为什么要做这个东西?或者我们想利用这款产品解决什么问题。
我们常常看到一些有关充气娃娃的表情包和图片或新闻,但是这种东西很少会像一些小视频一些相互交流,大家可能都是偷摸玩耍。所以猪哥相信其实大部分同学并没有亲身体验过充气娃娃到底是什么感觉(包括猪哥),所以猪哥很好奇究竟是什么一种体验?真的如传言中那样爽吗?
二、功能描述
基于很多人没有体验过充气娃娃是什么感觉,但是又很好奇,所以希望通过爬虫+数据分析的方式直观而真实的告诉大家(下图为成品图)。
三、技术方案
为了实现上面的需求以及功能,我们来讨论下具体的技术实现方案:
分析某东评论数据请求
使用requests库抓取某东的充气娃娃评论
使用词云做数据展示
四、技术实现
上篇文章中就给大家说过,今天我们以某东商品编号为:1263013576的商品为对象,进行数据分析,我们来看看详细的技术实现步骤吧!
本教程只为学习交流,不得用于商用获利,后果自负!
如有侵权或者对任何公司或个人造成不利影响,请告知删除
1.分析并获取评论接口的URL
第一步:打开某东的商品页,搜索你想研究的商品。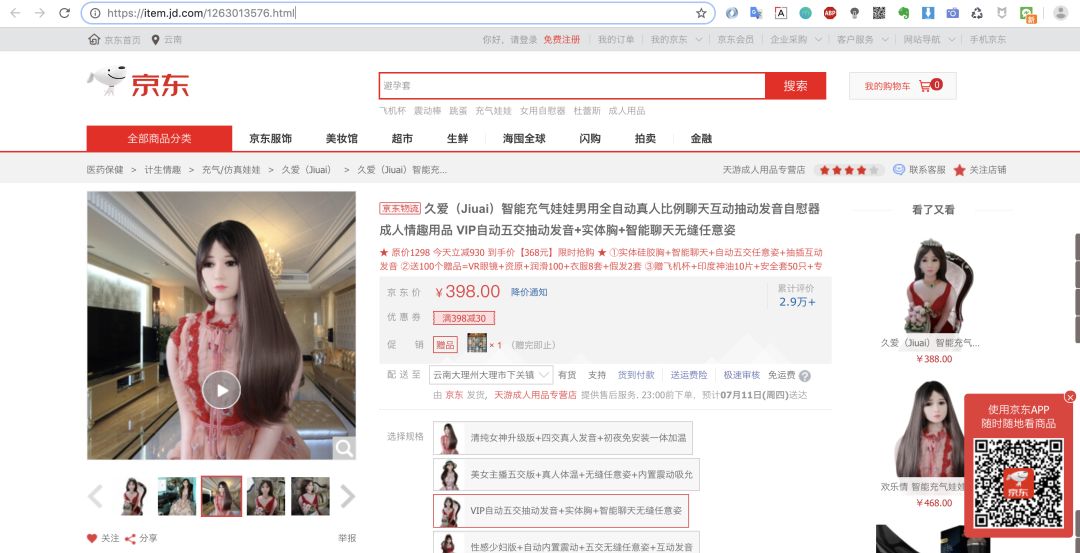
第二步:我们在页面中鼠标右键选择检查(或F12)调出浏览器的调试窗口。
第三步:调出浏览器后点击评论按钮使其加载数据,然后我们点击network查看数据。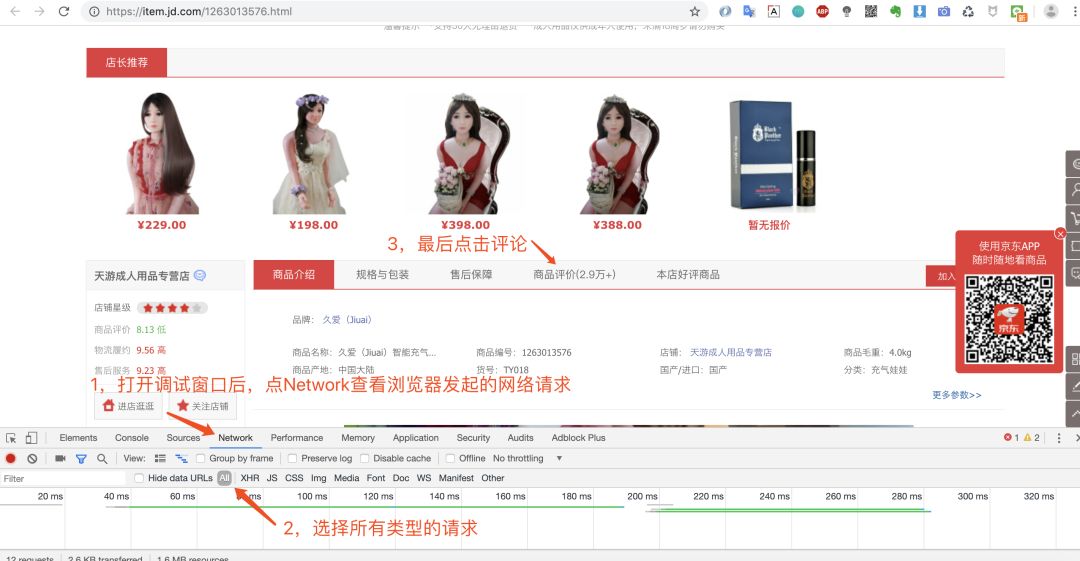
第四步:查找加载评论数据的请求url,我们可以使用某条评论中的一段话,然后在调试窗口中搜索。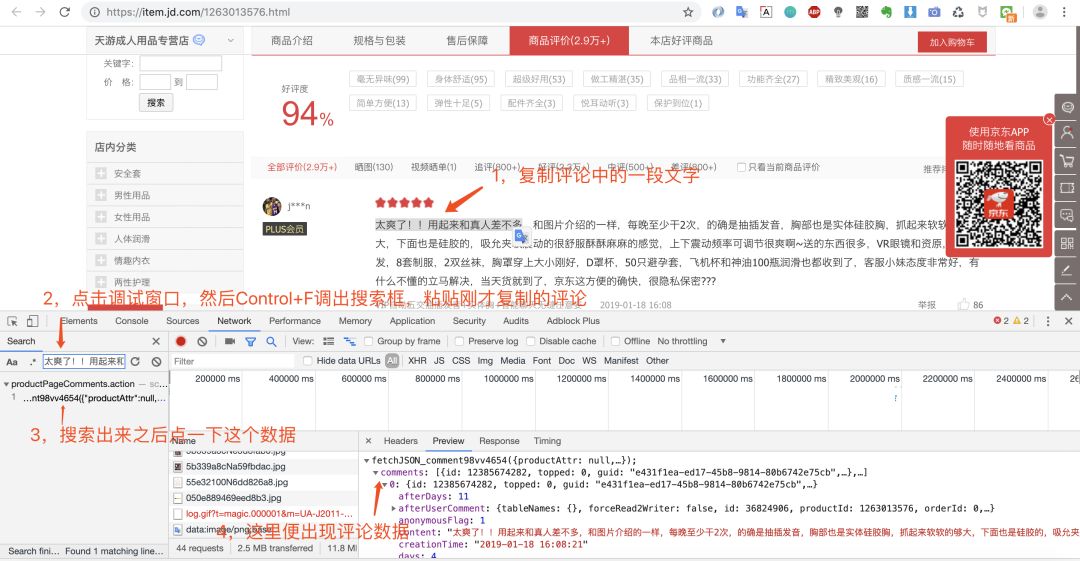
经过上面4步分析,我们就拿到了京东评论数据的接口:https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4654&productId=1263013576&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
productPageComments:看这个名字就知道是产品页评论
2.爬取评论数据
拿到评论数据接口url之后,我们就可以开始写代码抓取数据了。一般我们会先尝试抓取一条数据,成功之后,我们再去分析如何实现大量抓取。
上一篇我们已经讲解了如何使用requests库发起http/s请求,我们来看看代码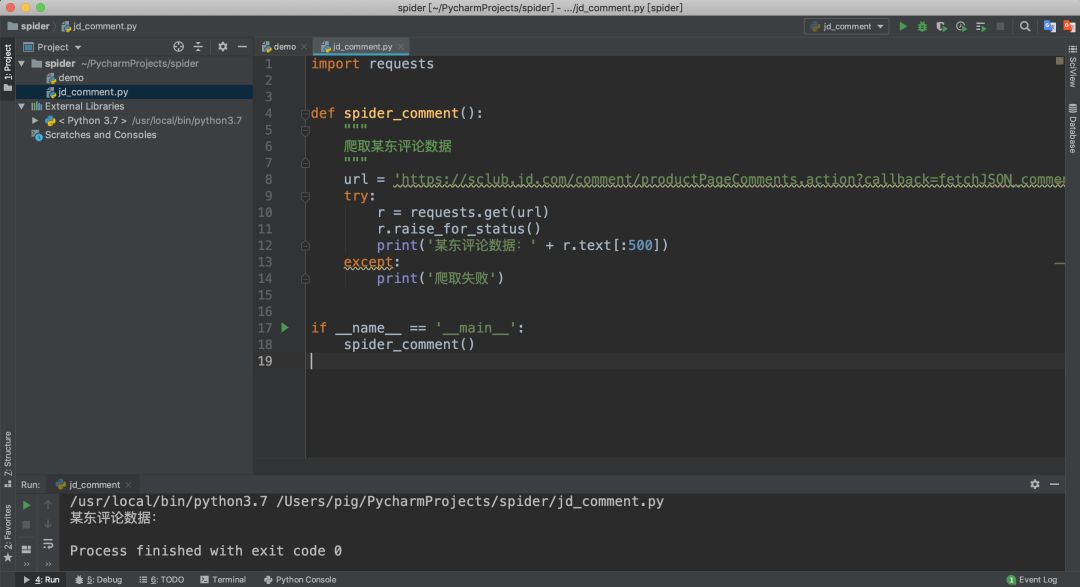
但是在打印的结果中数据却是空?为何浏览器请求成功,而我们的代码却请求不到数据呢?难道我们遇到了反爬?这种情况下如何解决?
大家在遇到这种情况时,回到浏览器的调试窗口,查看下浏览器发起的请求头,因为可能浏览器请求时携带了什么请求头参数而我们代码中没有。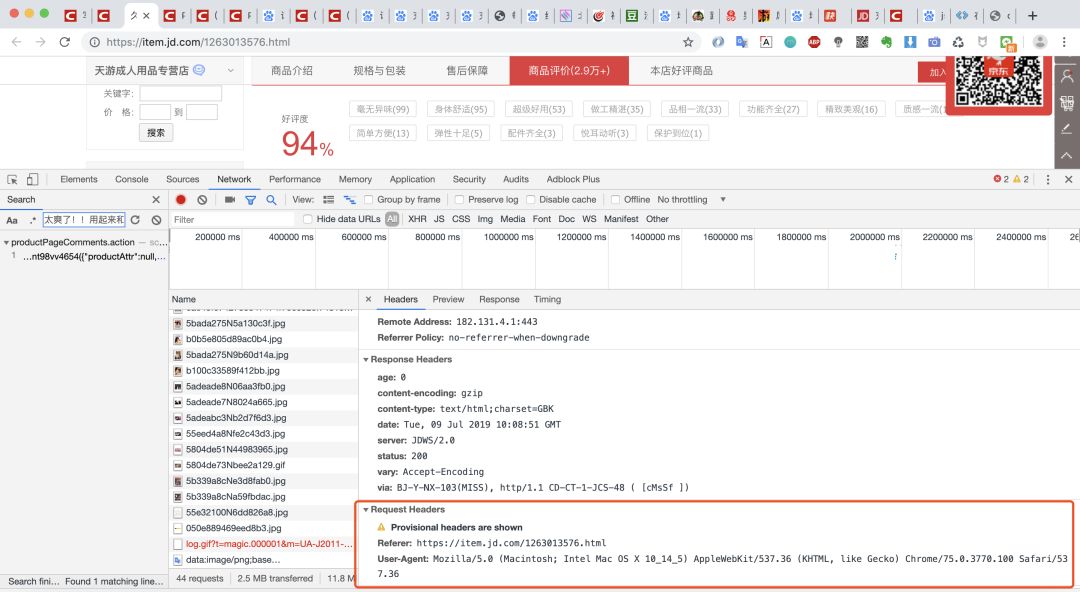
果然,我们在浏览器头中看到了有两个请求头Referer和User-Agent,那我们先把他们加到代码的请求头中,再试试!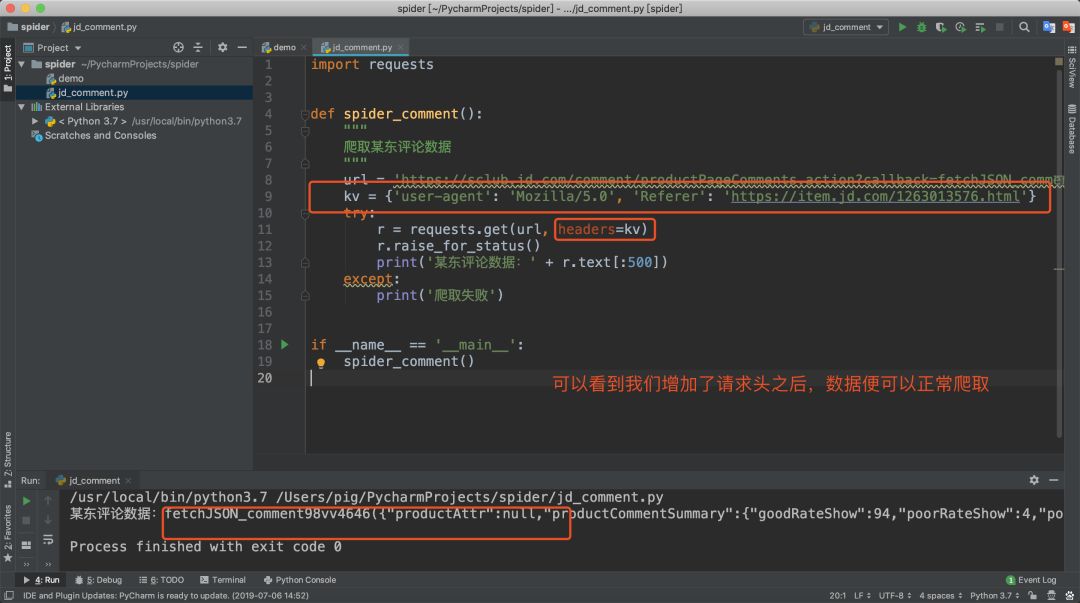
3.数据提取
我们对爬取的数据分析发现,此数据为jsonp跨域请求返回的json结果,所以我们只要把前面的fetchJSON_comment98vv4646(和最后的)去掉就拿到json数据了。
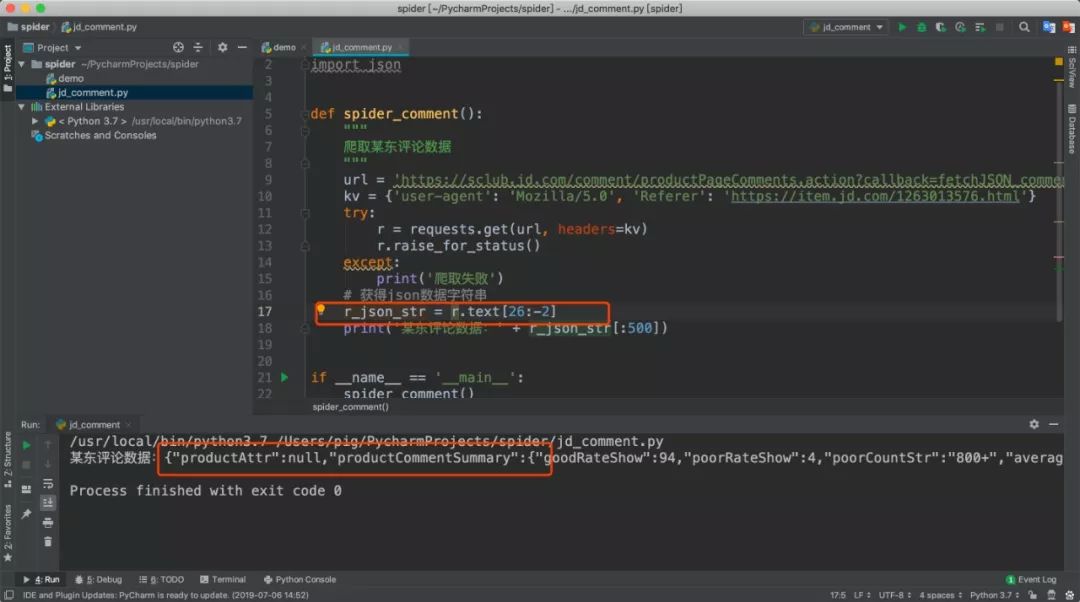
将json数据复制到json格式化工具中或者在Chrome浏览器调试窗口点击Preview也可以看到,json数据中有一个key为comments的值便是我们想要的评论数据。
我们再对comments值进行分析发现是一个有多条数据的列表,而列表里的每一项就是每个评论对象,包含了评论的内容,时间,id,评价来源等等信息,而其中的content字段便是我们在页面看到的用户评价内容。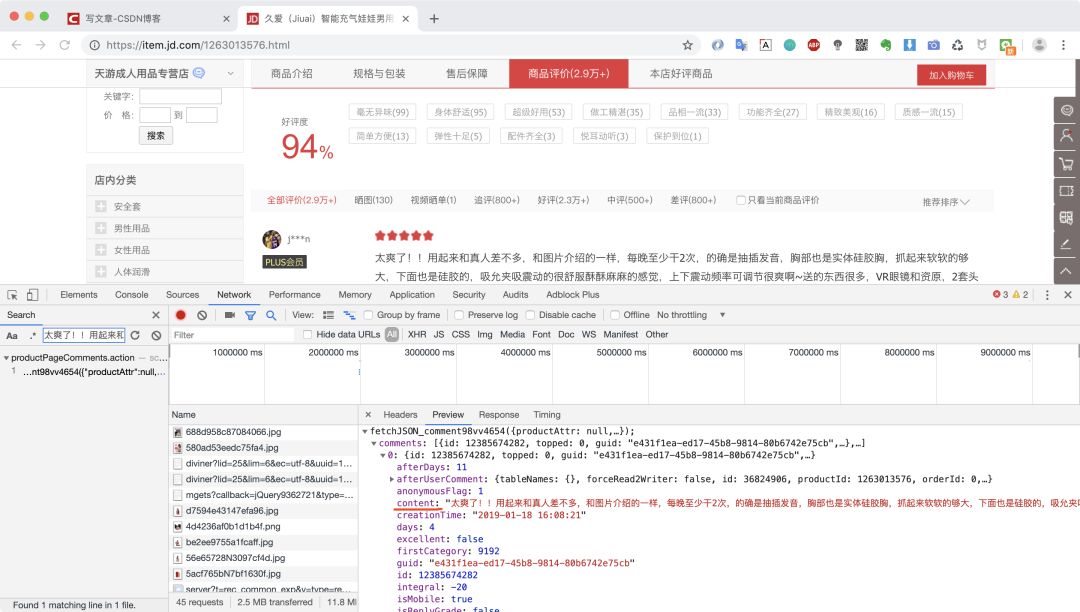
那我们来用代码将每个评价对象的content字段提取并打印出来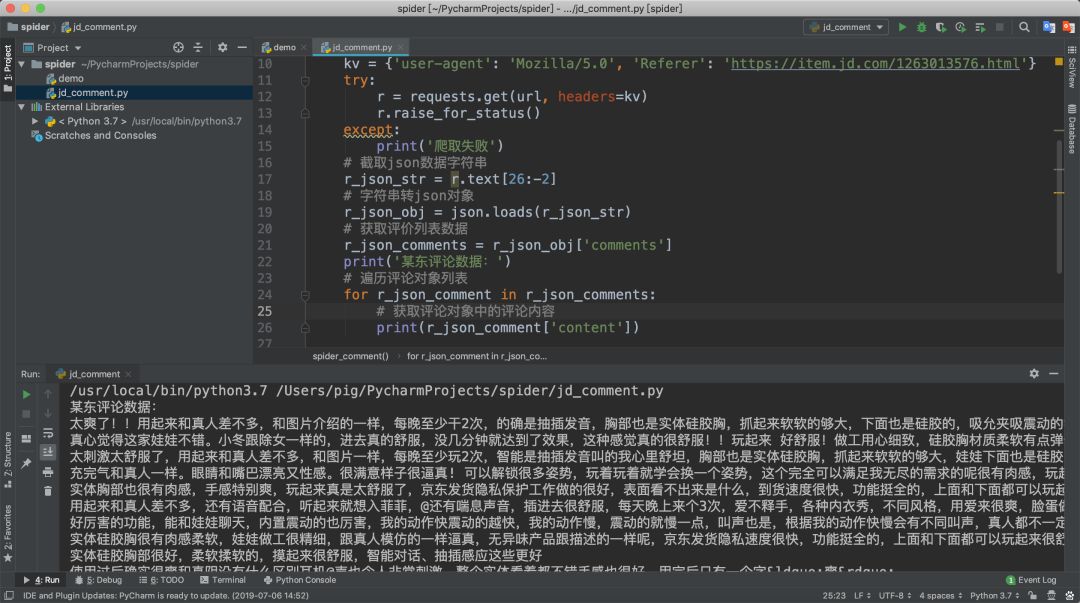
4.数据保存
数据提取后我们需要将他们保存起来,一般保存数据的格式主要有:文件、数据库、内存这三大类。今天我们就将数据保存为txt文件格式,因为操作文件相对简单同时也能满足我们的后续数据分析的需求。
然后我们查看一下生成的文件内容是否正确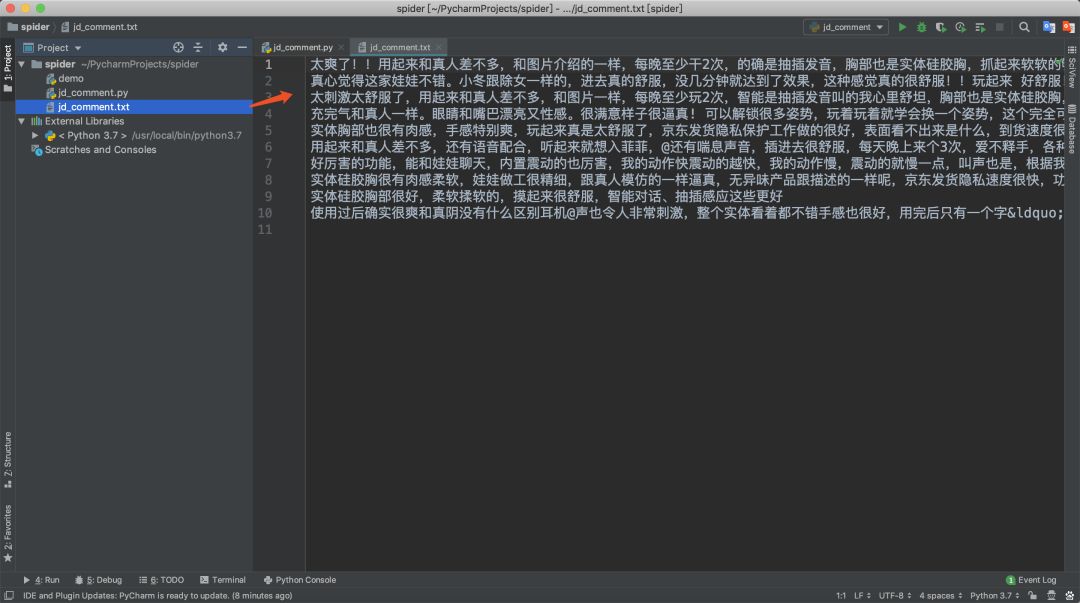
5.批量爬取
再完成一页数据爬取、提取、保存之后,我们来研究一下如何批量抓取?
做过web的同学可能知道,有一项功能是我们必须要做的,那便是分页。何为分页?为何要做分页?
我们在浏览很多网页的时候常常看到“下一页”这样的字眼,其实这就是使用了分页技术,因为向用户展示数据时不可能把所有的数据一次性展示,所以采用分页技术,一页一页的展示出来。
让我们再回到最开始的加载评论数据的url:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4654&productId=1263013576&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
我们可以看到链接里面有两个参数page=0&pageSize=10,page表示当前的页数,pageSize表示每页多少条,那这两个数据直接去数据库limit数据。
老司机一眼便可以看出这就是分页的参数,但是有同学会说:如果我是老司机还干嘛看你的文章?所以我教大家如何来找到这个分页参数。
回到某东的商品页,我们将评价页面拉到最底下,发现有分页的按钮,然后我们在调试窗口清空之前的请求记录。
清空之前的请求记录之后,我们点击上图红框分页按钮的数字2,代表这第二页,然后复制第一条评价去调试窗口搜索,最后找到请求链接。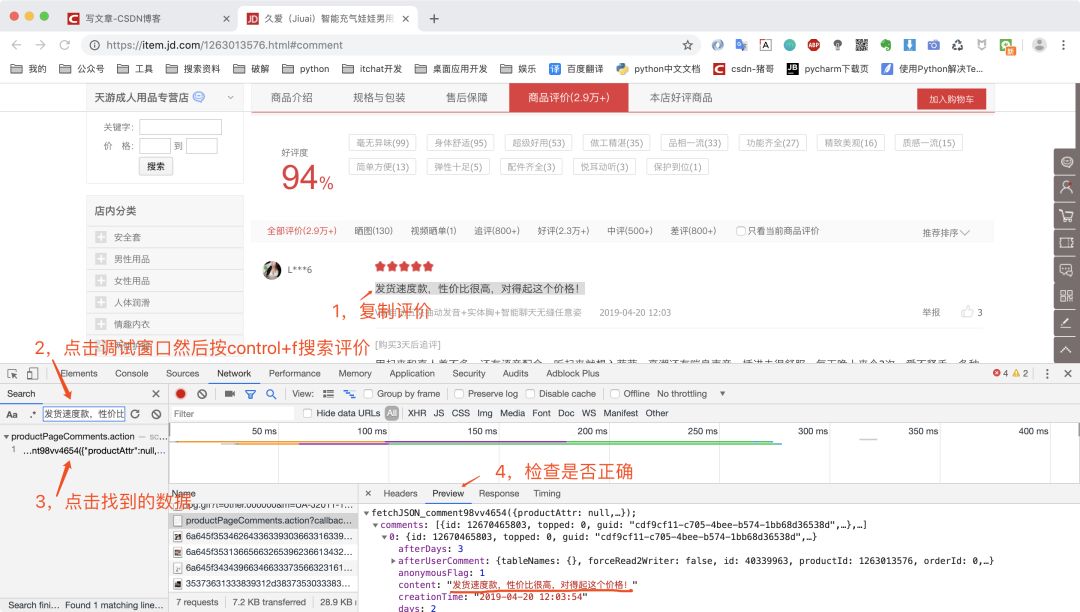
然后我们点击Headers查看第二页请求数据的url
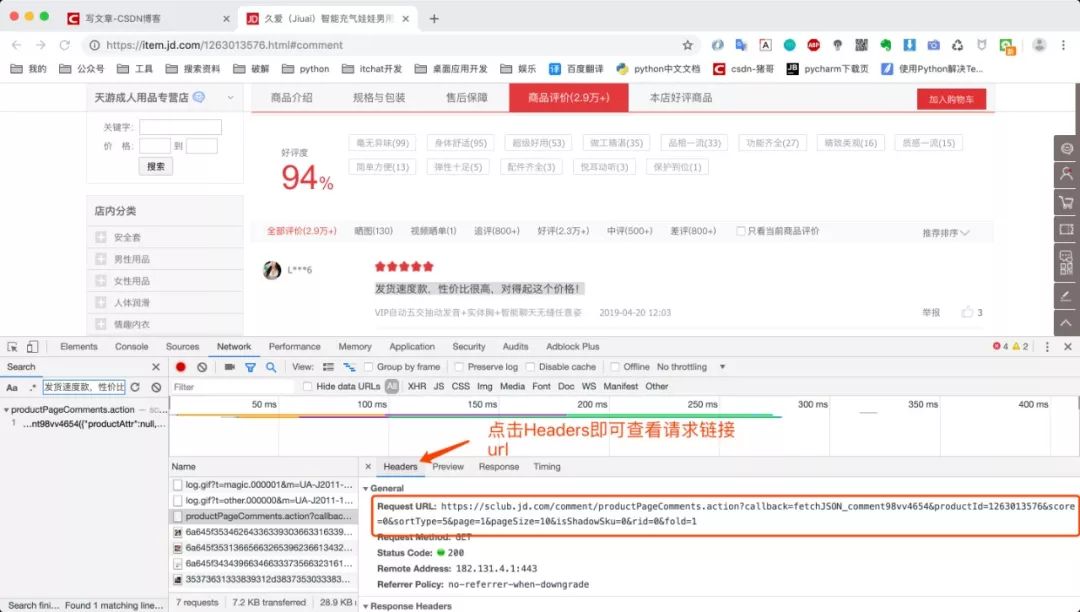
然后我们比较第一页评价与第二页评价的url有何区别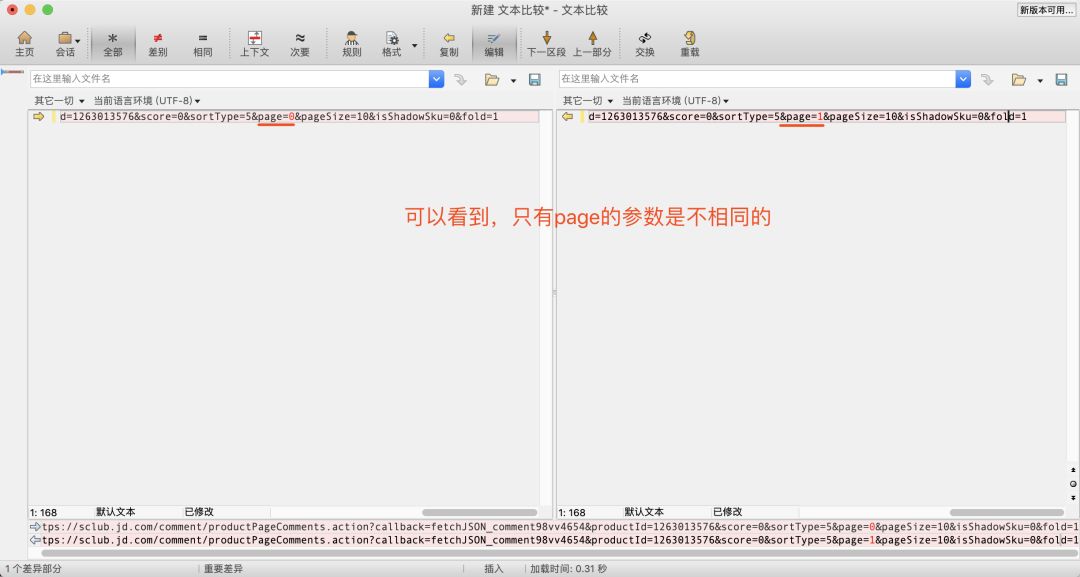
这里也就验证了猪哥的猜想:page表示当前的页数,pageSize表示每页多少条。而且我们还能得出另一个结论:第一个page=0,第二页page=1 然后依次往后。有同学会问:为什么第一页不是1,而是0,因为在数据库中一般的都是从0开始计数,编程行业很多数组列表都是从0开始计数。
好了,知道分页规律之后,我们只要在每次请求时将page参数递增不就可以批量抓取了吗?我们来写代码吧!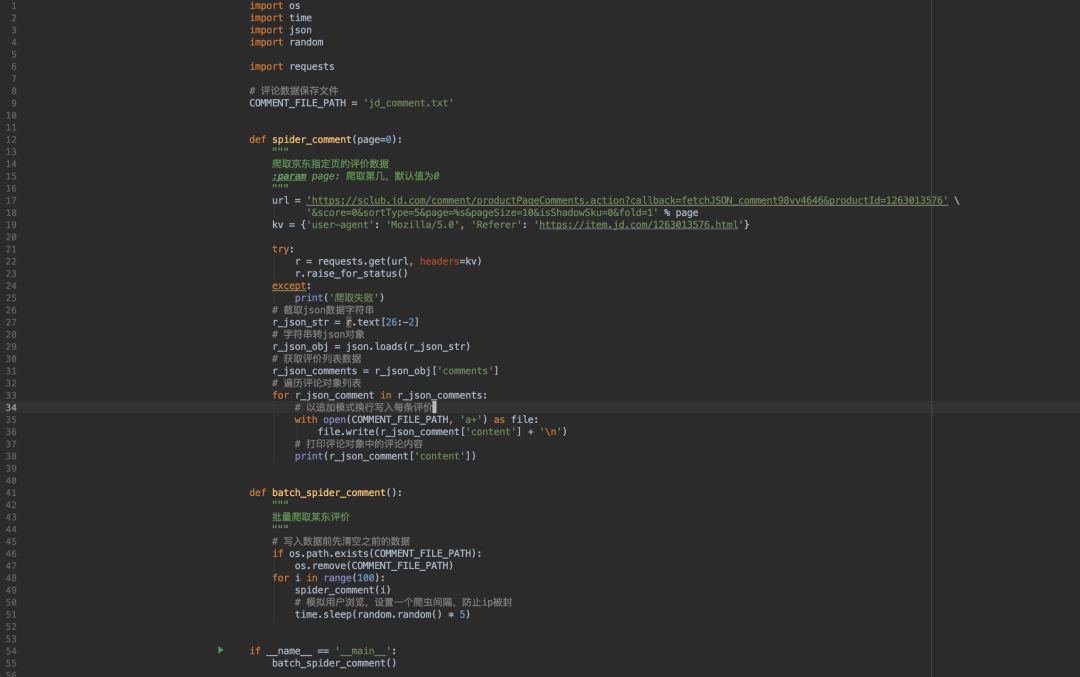
简单讲解一下做的改动:
对spider_comment方法增加入参page:
页数,然后在url中增加占位符,这样就可以动态修改url,爬取指定的页数。
增加一个batch_spider_comment方法,循环调用spider_comment方法,暂定爬取100页。
在batch_spider_comment方法的for循环中设置了一个随机的休眠时间,意在模拟用户浏览,防止因为爬取太频繁被封ip。
爬取完成之后检查成果
6.数据清洗
数据成功保存之后我们需要对数据进行分词清洗,对于分词我们使用著名的分词库jieba。
首先是安装jieba库:
pip3 install jieba
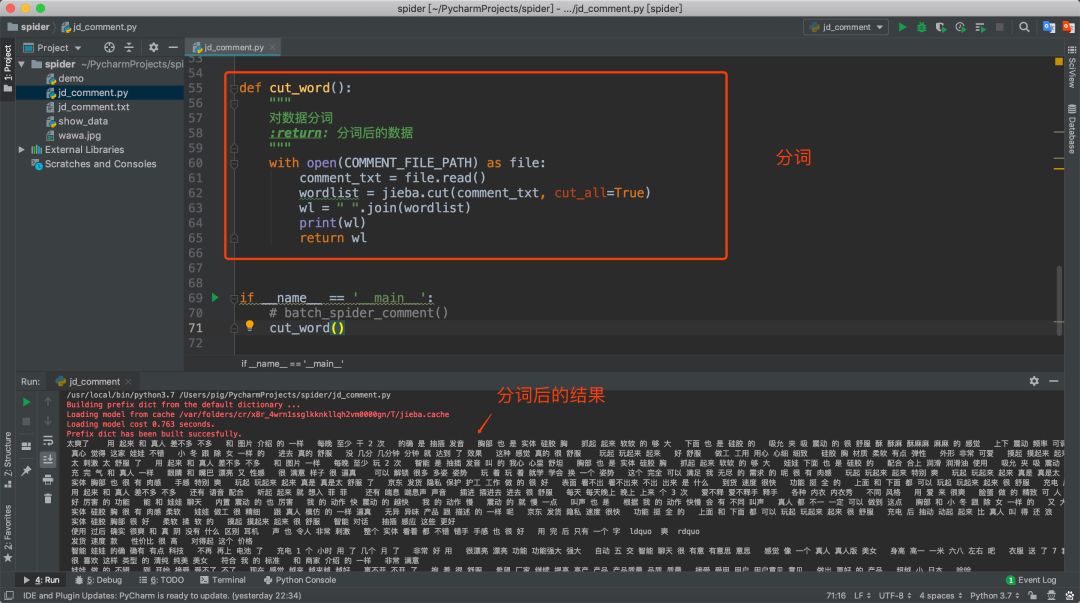
当然这里你还可以对一些介词等无效词进行剔除,这样可以避免无效数据。
7.生成词云
生成词云我们需要用到numpy、matplotlib、wordcloud、Pillow这几个库,大家先自行下载。matplotlib库用于图像处理,wordcloud库用于生成词云。
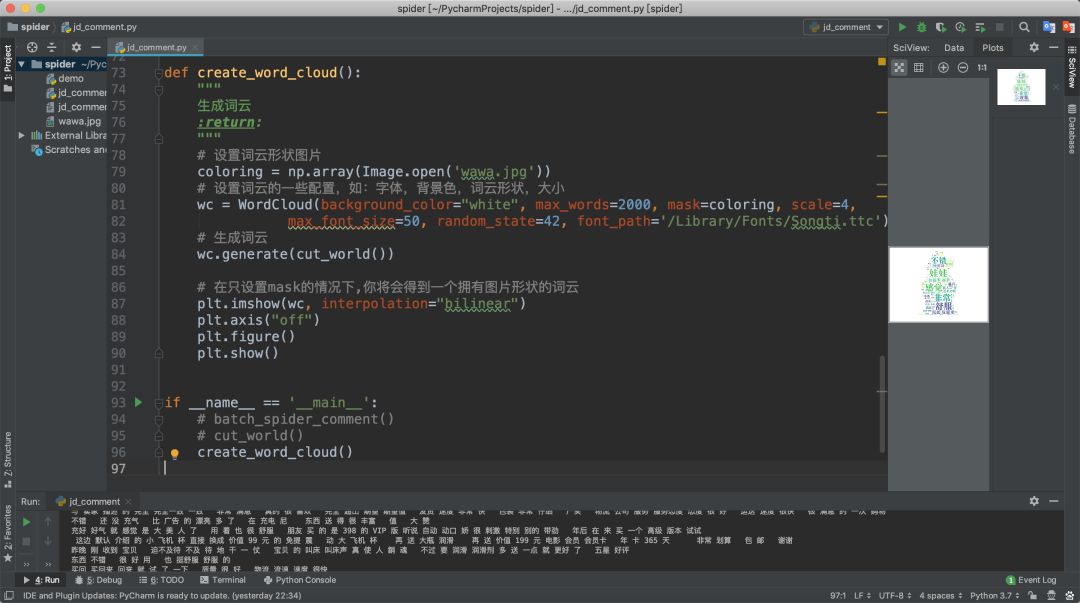
注意:font_path是选择字体的路径,如果不设置默认字体可能不支持中文,猪哥选择的是Mac系统自带的宋体字!
最终结果:
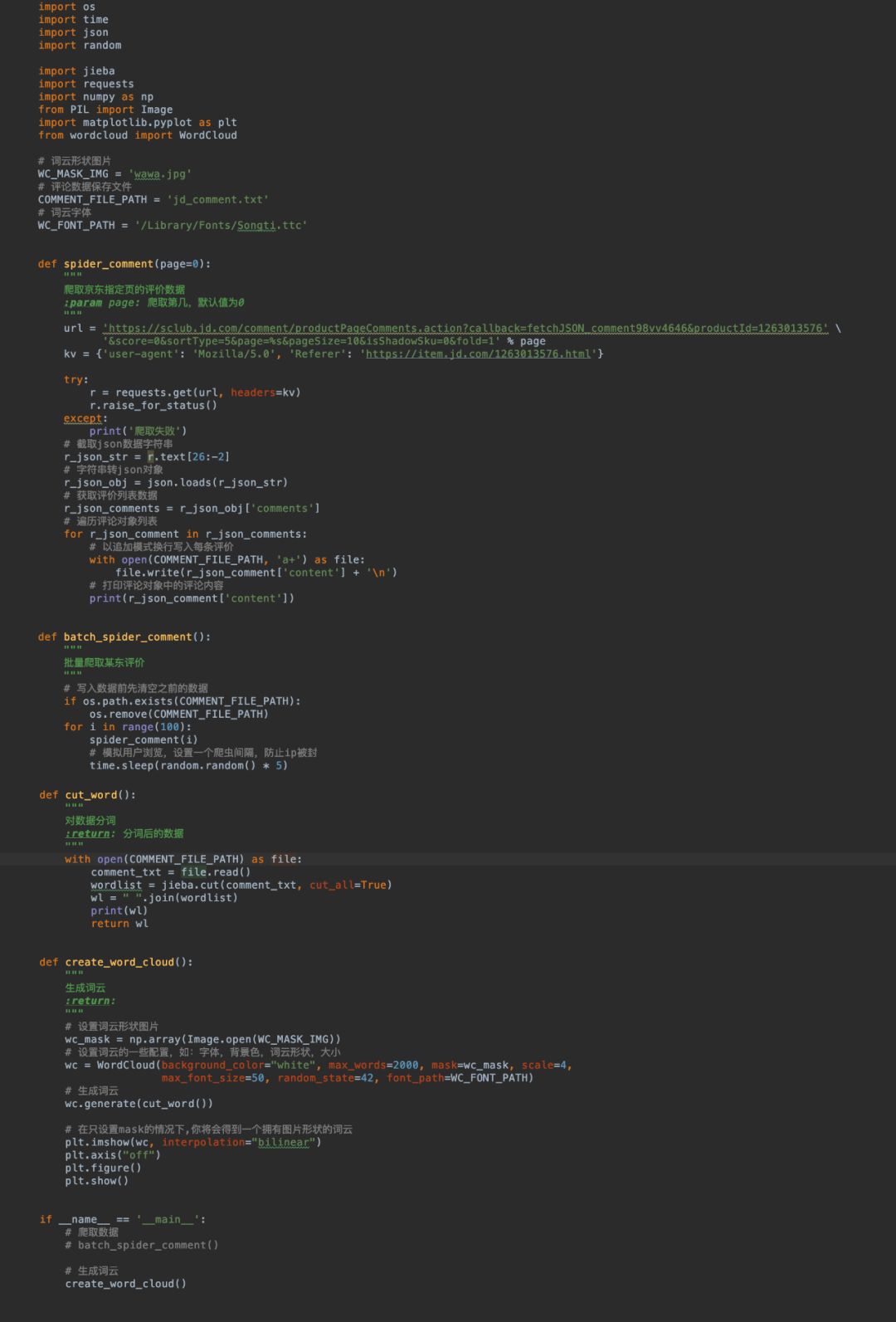
我们来看看全代码
五、总结
因考虑新手的友好性,文章篇幅较长,详细的介绍了从需求到技术分析、爬取数据、清洗数据、最后的分析数据。我们来总结一下本篇文章学到的东西吧:
如何分析并找出加载数据的url
如何使用requests库的headers解决Referer和User-Agent反扒技术
如何找出分页参数实现批量爬取
设置一个爬虫间隔时间防止被封ip
数据的提取与保存到文件
使用jieba库对数据分词清洗
使用wordcloud生成指定形状的词云
这是一套完整的数据分析案例,希望大家能自己动手尝试,去探索更多有趣的案例,做个有趣的人~
免费的学习资料
北京大学公开课《数据结构与算法Python版》,面向具有Python语言程序设计基础的大学生和社会公众,介绍常见的基本数据结构以及相关经典算法,强调问题-数据-算法的抽象过程,关注数据结构与算法的时间空间效率,培养学生编写出高效程序,从而解决实际问题的综合能力。
这门课程在中国大学MOOC正在进行第二次开课,已进行至第五周,心急的同学也可以直接看第一次开课的完整版,变化不大。
慕课:http://www.icourse163.org/course/0809PKU068-1206307812
B站:https://www.bilibili.com/video/BV1h7411m7BK/
配套课件及参考教材小编已经整理好了,需要的同学可以扫描下方的二维码,后台回复算法。
?长按上方二维码 回复「算法」即可获取资料

