
算法模型调优指南
在算法项目落地过程中,如果只考虑机器学习相关部分,个人感觉最花时间的两个部分是数据质量问题处理和模型实验与迭代调优。在之前Fullstack Deep Learning介绍的基础上,我们在这篇文章中主要针对第二个问题做一些详细的展开。
阅读建议
一不小心,本文又写的有点长……所以这里大概给一个阅读建议:
对于初级算法工程师,希望了解基础的算法建模流程的,可以主要阅读1~5部分。 从第6部分开始是更深入的通过数据分析来进行模型调优的一些介绍,以及后续的测试,工程化,上线的简介,比较适合有经验的算法工程师阅读。
对于文中有任何描述不明确的地方,欢迎提出宝贵建议,先提前感谢大家啦!
1 原则
先列举一些模型优化过程中遵循的一些原则:
清晰的优化指标 高质量Pipeline 明确的实验设计 深入的结果分析
接下来我们逐步来分析与介绍。
2 指标定义
2.1 什么是一个好的指标
从广义的指标定义来看,有几个考量方面:
Actionable,可以指导具体行为。 Accessible,简单,容易理解。 Auditable,可以进行验证。
2.2 机器学习项目中的指标
在机器学习项目中,我们在遵循上述原则下,往往会定义不同类型的指标:
组织目标,例如增加整个公司的收入,降低成本,或者对社会的整体贡献等。一般会比较宏观,与具体技术的距离相对较远。另外这些指标收到的影响因素也有很多,内外部因素都有。在技术项目实现周期,到能影响到组织目标的变化过程会非常缓慢。因此一般很难直接优化这个指标。 业务指标,相对组织目标来说会更加具体和可衡量。注意在这个层面我们经常碰到一些情况是模型输出预测是否符合用户预期,这种较为模糊的指标定义往往难以衡量与改进。因此必须与用户沟通,制定出明确可量化的指标来进行衡量。这个维度的指标也经常会比较复杂,从技术层面来看可能难以直接优化。 模型指标,为了能快速迭代实验,我们往往需要深入理解前面的组织目标,业务指标,再转化为模型可以直接优化的指标,例如mae损失函数等。但这里也需要非常小心,模型指标可能并未反映用户的真实感受,或者与最终的业务目标有一些差距。
对于这几类的指标,一个通常的做法是可以以不同的频率在不同层级对这些指标进行评估验证。例如在具体的实验中,可以以非常高的每次试验的频率来评估模型指标是否有提升。在天或者周的级别去验证模型效果的提升能够带来业务指标的提升。最后在月甚至更长的维度上去评估业务指标对组织整体目标的实现是否有正向促进作用。
实际项目中,往往会出现业务方面的指标不止一个的情况。例如我们既需要预测在细粒度上的squared error较低,又需要预测总量上的偏差较小。为了能较好的评估模型,我们一般会设定一个主要的优化指标(可以是多个误差项的综合),将其它指标转化为限制条件。例如在模型预测时间不超过1秒的情况下,取得尽量高的AUC。
3 实验流程
很多机器学习课程上介绍的做法和很多行业新人在进行实验时会采取随机尝试的策略。例如,我先使用某种方法,得到了一个结果,然后脑子里又蹦出一个新的想法,继续尝试新方法,看结果是否有提升,依此不断循环。
But,这样做的效率太低了,很多时候就算效果有提升,也并不知道为什么,是否稳定,是否对最终的业务效果是正向的促进作用。因此我们更提倡采用数据分析驱动的方式来做各类建模实验。在分析基础上,实验设计的出发点一般需要有明确的假设,然后通过实验结果来验证假设是否成立。一般的步骤如下:
分析:模型问题是什么? 提出假设:可能的根源问题是什么? 设计实验:改进方案是什么? 执行与验证:改进方案是否有效? 循环迭代
另外在实验涉及的尝试方向上,数据相关的处理往往占据了主要的位置,包括数据修正,转换,更新,增强,采样等,可能占比在80%以上。剩下20%是与模型相关的尝试。这也是业界的一个相对普遍的情况,需要在考虑实验内容方向时多加判断,避免做了一系列高大上的前沿模型尝试,总体产出却非常有限。
3.1 问题分类
对于模型中可能出现的问题,我们作如下分类:
代码实现中的bug。对于机器学习pipeline来说,很多情况下即使有隐藏的bug,程序也完全能跑通。这对问题排查造成了更大的困扰。 超参数设置不合理。很多模型对各类超参数的设置比较敏感,需要针对不同的问题和表现进行超参数的调整。 数据相关问题。数据量不足,分布不均衡,出现错误的标签,缺少特定信息,有概念漂移问题等。 模型选择问题。针对特定的问题及数据情况,我们需要选择合适的模型。
3.2 整体流程
为了避免这些问题,构建出高效,准确率高的算法模型,我们可以遵循如下的通用步骤:
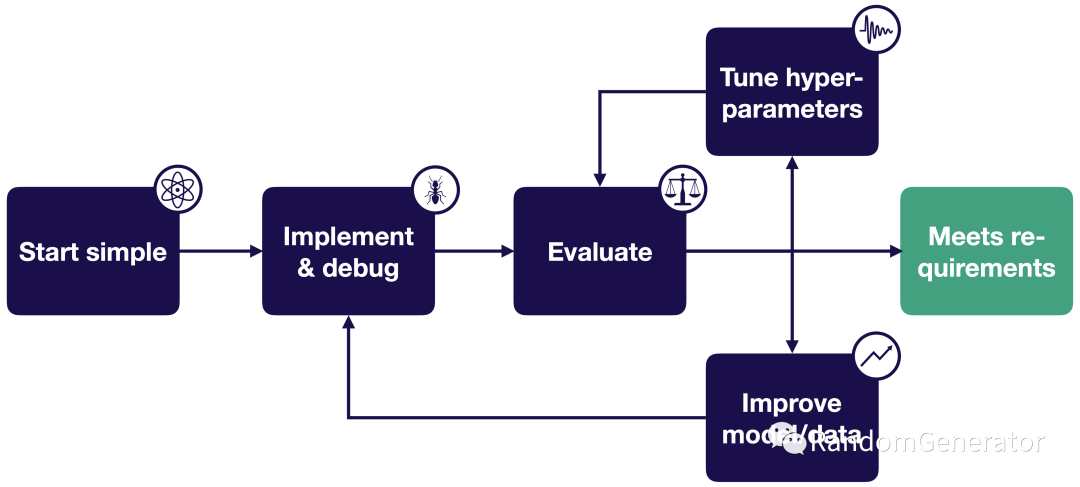
从简单的pipeline开始,例如选择最简单的规则,或者基础模型。以深度学习模型为例,我们可以选择最基础的MLP模型,adam优化方法,不加任何regularization,使用标准归一化方法,选取一个子集数据进行尝试。 实现并跑通pipeline。确保模型能够运行,并在小数据集上overfit,或复现一些已知结果。 评估并分析结果。后续会详细介绍分析手段方法。 参数调优。对模型的各种参数,模型结构进行各种调整。 数据与模型调优。修复数据中的问题,做数据增强,引入不同类型的数据,收集更多数据,或者特征工程预处理方面的操作。模型方面可以使用更加高级/复杂的模型结构,引入ensemble等。
这方面比较好的资料可以参考Andrew Ng的《Machine Learning Yearning》,后续我们也会做一些具体阐述。
4 实验执行与管理
4.1 Pipeline
模型上线之后,需要有高质量的pipeline来进行系统化的运行,debug,及版本管理。这里不做详细展开。从实验与模型优化角度看,对于经常需要尝试迭代更新的部分,应该做好模块分割,便于灵活进行针对性的实验。
实验pipeline对运行效率会有更高要求,通常是针对整个流程中的一小部分,来反复修改尝试,快速获取到实验结果。举例来说,如果我们想做一个新特征的尝试,应该基于历史的特征数据集来进行增量的尝试,而不是修改原有的特征工程代码,触发全量的特征构建流程。一个简单的评估标准是,每次实验运行的总时间中,有多少百分比的时间实际上是在做重复的操作。理想情况下,这部分重复运行的占比要低于10%。
对于实验pipeline的代码质量方面,一个简单的原则就是越需要重复高频使用的实验,越需要做更好的抽象和代码质量保证。建议在notebook中写完草稿后,拷贝到PyCharm等专业IDE中进行代码重构与质量检查。
另外有一些业界研究,例如HELIX就是为了提升实验效率,希望能够自动存储中间结果,来减少重复计算,达到使用同一个pipeline,但重复执行的效率会变得很高的效果。
4.2 版本管理
在pipeline基础上,我们需要对实验使用到的各类依赖进行版本管理,主要包括:
数据版本,如果使用的产品带数据版本,直接使用即可。否则可以考虑用sha1等文件校验码来记录数据的版本信息。 代码版本,对于库函数这类有git管理部分的代码,可以直接使用git的版本号。对于临时的notebook文件,可以每天做一个notebook版本的备份。对于重要结果,例如当前最好效果,也可以随时做版本备份。 参数配置,大多数情况下,参数配置可以在代码或者数据的版本中cover。但需要额外注意使用了外部配置文件的情况,对于这些配置文件,也需要与实验的其它运行组成来一起管理(例如放在同一个文件夹下)。 模型版本,对于模型训练非常耗时的场景,训练出来的模型也需要进行版本管理,以便于后续的分析与重用。
实验版本管理对于项目过程中review进度,确定下一步计划,复现结果并部署上线等方面都非常重要。
5 初级建模调优
5.1 数据流验证
首先检验data flow没有问题。例如使用简单的规则,替代模型模块,查看整个pipeline的流程是否有问题。对pipeline中大块环节的输出做检查。

5.2 跑通模型训练
接下来将规则替换成真实的简单模型,进行训练与预测,看是否能跑通。过程中会出现各种抛错,列举一些最常见的bug:
Tensor shape错误 预处理错误 Loss function错误 数据中有NaN/Inf等值 没有正确的设置训练模式,或其它框架相关常见错误 参数或数据处理问题导致的OOM 库版本不匹配导致的奇怪exception
应对策略:
使用标准化的流程pipeline,比如框架内置方法,或者自己整理的针对某类问题的标准receipe。 搜索StackOverflow,Github上相关问题,寻求解决方案。 使用debugger和profiler进行深入调试。 借助一些专用工具来辅助排查,例如tensor-sensor。
5.3 在小数据集上过拟合
模型可以训练了,我们会使用小批量数据来看是否能让模型在这部分数据上过拟合。这里会碰到的一些常见问题例如:
误差不降反升 误差爆炸 误差震荡 误差停留在一个高位无法下降
应对策略:
误差上升的可能原因,学习率太高,loss function定义错误 误差爆炸的可能原因,学习率太高,各种数值操作的问题,如exp,log,除法等 误差震荡的可能原因,学习率太高,原始数据问题如数据错位,预处理bug等,可以进一步通过结果分析定位 误差停留在一个高位,可能由于学习率太低,优化器相关设置,正则项过大,模型过于简单,loss function欠佳,部分数据有错误,没有做数据归一化,缺乏有效特征等
5.4 模型参数搜索
在模型可以在小数据量上正常优化后,接下来通常的建议可能是增加数据量并做一定的模型参数搜索。不过根据我们的经验,这部分的整体计算开销较大,但回报率相对比较一般(可以参考AutoML文中的一些research结论)。所以如果模型训练开销不大的情况下,我们可以考虑在每天空闲时间(例如晚上下班后),挂一些自动参数搜索的任务进行调优尝试。而在工作时间段,还是应该集中精力做误差分析和问题定位。
5.5 深入优化
在初始的pipeline跑通,模型可以产出有意义的预测之后,再接下来就逐渐开始进入深水区了。一方面我们要不断降低模型训练误差,另一方面也要开始关注模型的泛化能力,根据场景的不同会出现各种复杂的表现,并需要我们在各类问题中进行权衡与选择。从这里开始,我们的实验过程中会有很大一部分精力放在结果误差分析,以及数据模型层面各类问题的处理上,具体可以参考下面的数据分析环节。
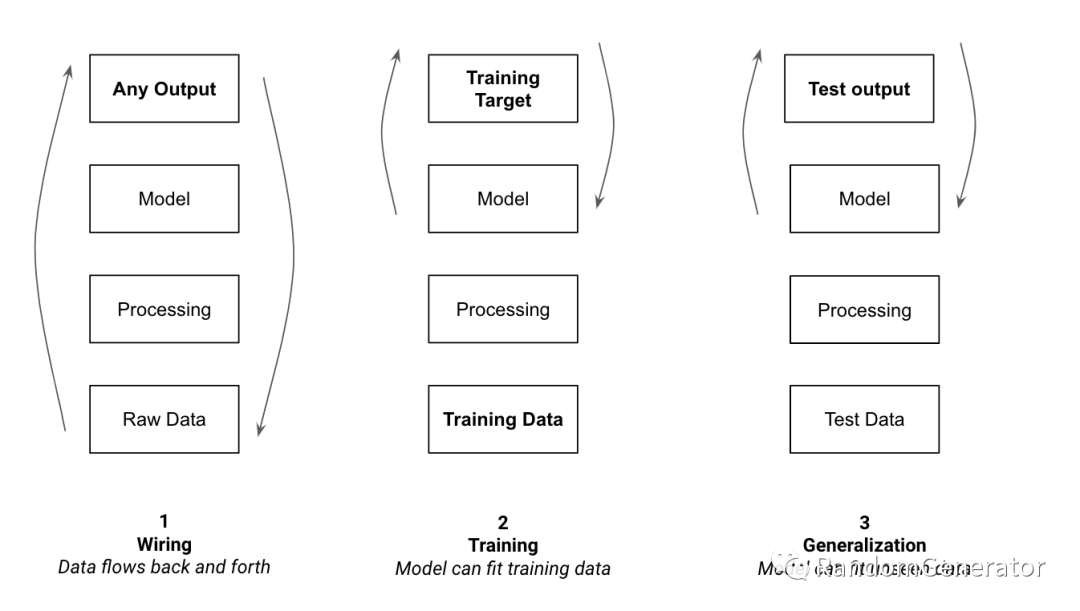
例如模型泛化能力差问题,可能由于train/test数据分布变化,模型/超参复杂度过高,data leak,数据量不足,有干扰特征,缺乏数据归一化操作等。具体原因可以根据详细的误差分析来挖掘。
对于深度学习模型的优化,还有一些非常不错的资料可以参考,例如Karpathy的这篇blog post。
6 深入调优分析
构建有效模型的关键是能够迅速且准确的定位到当前模型失败的原因具体是什么。这也是结果分析的主要目标。
理想情况下,我们需要能明确定义:
模型当前问题,例如在节假日期间,办公型门店的预测销量不准。 各个问题导致的误差占比,例如上述问题在总体误差中占了12%。 问题对应的典型数据集,例如我们可以收集一系列节假日,办公型门店的历史数据,用于后续调优改进的检验集。
当然,如果以整体思维来考虑,我们在分析过程中还需要考虑:
模型的错误类型有哪些,是否能在目前的优化指标中反映出来。 用户真实体验如何。 模型错误可能导致的最严重后果是什么。
关于产品与用户体验方面,可以参考Google这篇非常好的文章中的阐述。
6.1 数据分析
人工检查样本,获取一个对数据的整体感受。比如可以注意观察数据是否分布均匀,是否有重复数据,label是否正确,是否能直观发现比较重要的特征。在任何时候,亲眼看一看数据细节都会是很有帮助的。
尝试让自己作为算法来进行预测,例如选取几条数据,看是否能根据自己的理解作出正确的预测。以此来更好的理解预测目标,数据状态,以制定模型/规则策略。
统计分析,借助一些工具如pandas_profiling等做统计和可视化分析。例如绘制相关度矩阵,观察特征与预测目标之间的关联度,或者特征分布的箱线图,观察是否有异常值离群值等。
统计分析中还有很重要的一点是Drift分析,观察输入和预测目标随着时间变化是否出现了分布偏移。这对我们后续模型设计,以及构建验证集的分割方式选取上也会有参考意义。
人工检查模型输出。指标一般是一个统计型结果,而往往容易覆盖一些比较严重的问题。以LinkedIn推荐系统的为例,他们设计了一个向用户推荐感兴趣的群组功能。一个比较简单的方法是推荐包含公司名的热门群组,结果给Oracle的员工推荐里有一个排名挺高的群组名叫"Oracle Sucks!"。如果只关心指标,可能只是非常微小的一个precision/recall变化变化。但对于用户感受来说,差别是巨大的。
6.2 模型指标分析
选取少量数据(例如1000条),确保模型可以训练并过拟合。后续逐步增加训练数据观察数据量增加对模型效果的影响。这么做一方面可以在少量数据上验证整体训练的pipeline,优化器模型结构等都可以正常工作。另一方面获取到数据量增加情况下模型效果的变化,也有助于后续判断在模型调优时是否还需要收集更多的数据或进行数据增强操作以提升效果。
与已知结果相比来判断当前model的效果处于一个什么水平。如果没有对比,我们只能与真实值比较与分析模型表现,但并不知道模型指标的上下限大致情况如何。对于模型效果下限,可以使用简单的baseline model来对比,例如直接输出占比最大的类别作为最简单的分类模型。对于模型的上限/调优目标,我们可以选择几个可能的来源,例如公开发表的类似问题的模型效果,利用已知SoTA模型跑出来的对比效果(例如ResNet,BERT等),或者与人工专家预测的结果进行对比。这些上下限模型给出的结果,可以作为更多的信息来源,帮助我们分析目前模型的问题在哪。例如发现人工预测在某些subgroup中明显超过了我们的模型效果,则可以深入分析其中是否包含了未知的业务信息需要捕捉。
Learning curve检查,观察模型在训练集和验证集的表现,也就是经典的bias/variance trade-off,判断模型状态是否为欠拟合/过拟合,从而引导到控制模型复杂度的实验尝试。另外train,valid的效果相差较大,也有可能是在特征数据处理上出现了data leak,数据分布偏移,数据离群点等相关问题,可以通过数据分析可视化或模型解释手段来进行排查。后续涉及到特征工程修复,异常数据剔除,train/valid分割方式改进或目标函数的修改等操作。
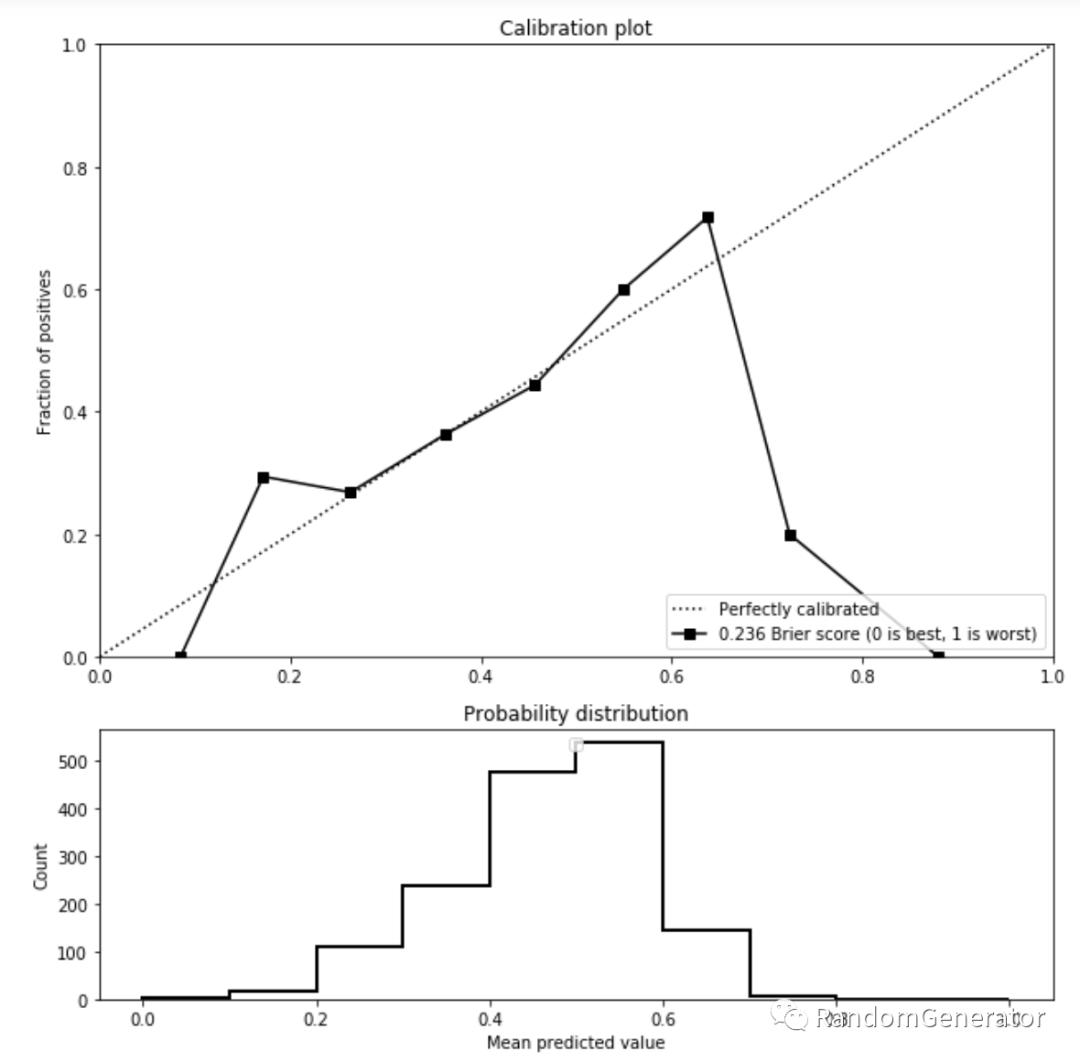
也可以绘制一些更复杂的模型指标可视化,例如混淆矩阵,ROC曲线,Calibration曲线等,帮助评估模型问题。例如Calibration曲线走势相反,可能是train/test数据分布不一致导致。如果出现走势平稳,可能是由于特征缺乏区分度引起。
另一大块是模型解释方法的使用。例如查看模型的特征权重,feature importance,或者借助一些黑盒解释手段如LIME,SHAP等。借助这些工具,可以辅助我们判断模型为何给出了不符合预期的预测。例如当我们发现某一组样本的预测整体偏高,就可以通过模型解释工具找到对这些样本的预测有正向影响最大的那些特征是哪些。另外一个例子是在特征选择优化中,我们可以在训练数据中加入随机值形成的一列特征,然后观察模型训练后这个随机特征的重要度排名。一般在这个随机特征重要度之下的那些特征,很可能并不具有预测能力,可以考虑移除。
还有类似tensorboard之类的模型配套开发工具,可以更进一步提供模型训练过程中更加详细的可视化信息,包括每一层的gradient变化情况,有助于我们针对性分析神经网络中出现的优化问题或数值问题。我们也可以针对不同的模型对应开发类似的“SDK”,提高我们排查模型问题的效率。
对于分类问题,可以在决策边界上找出模型不确定性较大的例子,再进行分析看是否是缺少数据,还是相关label有错误。Active learning也是类似的想法。
6.3 Generalize模型问题
在分析模型问题时,一个关键的目标是能够找到具有普遍意义的问题(而不是特例),并能准确描述这个问题的共通特点。
前面提到的各类模型指标分析与可视化,都可以进一步分割数据集,做多个维度上的指标分析。分割的维度的选择可以从数据中已经存在的业务维度开始,例如产品品类等,后续可以根据分析结果,构造一些特定的分组。对于不同维度下发现的问题,例如预测整体偏差较大或误差较大,数据量偏少等,引导到具体的validation集分割策略,新数据收集,重采样,预测结果后处理,或者分别构建模型等实验手段。
Top-k方法,观察预测最准的,最差的,和最不确定的top-k个样本。如果样本过多,则可考虑聚合到上一个层级来分析。通过寻找预测最准的部分,可以分析出模型中较为有效的特征,并确认这些是符合逻辑的。例如有个经典的例子,在图片分类问题中,模型学习到判别北极熊的特征其实是来自于雪地,而并不是动物本身。对于预测最差的部分,可能可以排查到是否是标签错误,或者特征数据中有异常。也可能是缺少了某些重要的信息输入,需要引入额外数据或构建新的特征。最不确定的样本方面,例如对一个二分类模型,我们可以考察模型预测输出在0.5左右的sample。这里往往可能存在有冲突的label训练样本,或训练数据不足的问题。
除了按照维度分割数据来评估指标,我们还可以使用聚类,降维等手段来辅助。例如使用k-means/k-prototypes,DBSCAN等聚类方法,将top误差项进行聚类,查看各个类的代表性例子,以及判别一些离群点。同理,在特征维度较高的情况下,使用PCA,UMAP,TriMAP等降维方法,再进行聚类,也是一种常见方法。甚至我们可以对误差大小本身来构建一个预测模型,然后根据模型学习到的结构和权重来辅助我们发现误差问题中的隐藏pattern。
6.4 模型报告
对于上述的各类分析发现,我们还可以设定相应的模型报告模板,例如可以参考Model Cards的形式,总结问题,并向业务相关人员提供更直观易理解的展现形式,而不再是一个黑盒模型。
6.5 误差分析深入
6.5.1 误差分类
在A Characterization of Prediction Errors中,作者建议我们可以把预测误差分为四类:
Mislabeling errors,标签错误。即原始的训练数据里就有问题,例如数据漏传,数据处理错误等。 Learner errors,优化错误或目标函数引入的误差,例如正则项。通过修改正则项,检查是否可以在目标函数error与泛化error之前取得平衡。 Representation errors,特征不足,或模型表达能力不足。技术上无法与mislabeling error区分,可以使用consistent learner(无正则项的lr,1-nn),找到invalidation set人工确认。 Boundary errors,数据不足。泛化错误。检测方式:将数据加入训练集后,看错误是否仍然存在。Uncertainty sampling for active learning也是基于这个思想。
根据这个误差分类,可以设计一些迭代调优方式:
使用无正则项的学习器(1-NN, LR),修复label error(correct label)和representation error(add feature),反复迭代。 验证boundary error,通过加入正则项来平衡泛化误差与learner error。
6.5.2 Identifying Unknown Unknowns
在这篇文章中,作者提出了处理模型unknown unknowns错误的方法,可以作为前面误差聚类方法的补充。其中第一步是做Descriptive Space Partitioning:
首先获取需要调查的数据集X,例如回归问题,选择误差top 10000条,或者分类问题,选择confidence很高但预测错误的条目。 候选特征pattern集合Q,通过频繁项挖掘,获取到调查数据集X中特征组合的频繁项。 开始迭代搜寻分割条件,其中pattern q来自于集合Q,计算X中符合q的条目数/g(q),取argmax时的q值。 将第三步中找到的q加入到partition条件集合P中,同时将其从候选集合Q中移除,另外也将q覆盖的条目从X中移除,继续第3步,直到X中所有条目都被覆盖。 最终的集合P就是partition方案,如果一个条目属于多个q,则取距离中心最近的那个q。
这里g(q)的定义是组内特征距离和 - 组间特征距离和 + 组内信心指数和 - 组间信心指数和 + size(q),如果是回归问题,信心指数(confidence score)即为预测值。这个DSP方法总体上相比kmeans,entropy更小,不过在有些数据集上的优势并不明显。
接下来需要人工分析这些错误聚类中的sample,作者提出了Bandit for Unknown Unknowns方法来提高检查分析的回报效率。背后的思想还是多臂老虎机算法,具体操作如下:
在前k步(k等于partition数量),从每一个partition中采样来query oracle,看是否是unknown unknowns(or 具有代表性的模型问题?)。后续使用UCB方法来采样来选择partition。评估收益的utility function,是否是unknown unknowns减去oracle验证的cost。
6.5.3 Error Analysis Visualization
Errudite,主要使用于NLP任务,跟ACL 2020上CheckList的想法有点类似,但是从误差分析角度出发,并提供了工具层面的支持,便于更高效率的误差分析。核心的三个步骤:
分析error sample,构建起误差背后共通特性的DSL描述。 将上述的DSL描述作为filter,apply到全量数据上,评判误差占比。 使用conterfactual方法来分析产生误差的具体原因。
Google的这篇教程中也提出了非常类似的框架。
CrossCheck,除了指标的更细维度的对比展示,还提供了notes记录等协作功能,有点意思。
AnchorViz,这个工作的主要动机是希望能更好的结合人类的知识能力,来提升active learning的效率。作者通过Anchor的概念,来让用户定义数据实例的“概念”,再通过RadViz的方法来展示各个Anchor影响下的实例的分布的可视化。从演示视频看还可以利用Anchor做很多有意思的操作,高效率的分析模型问题,快速定位到feature blindness error(类似于前面误差分类中的representation/label error),并迭代改进。
Dark Sight。结合了模型压缩和降维来对样本进行可视化,相比t-SNE这类降维方法,Dark Sight可以比较好的还原出模型的决策行为。例如在MNIST问题中,3和5两个类别的边界上,可以看到很多长得像3的5和长得像5的3,而t-SNE这类降维方法则没有这种性质,无法体现出模型在预测confidence上的平滑变化。应用这类技术,我们可以更好的理解模型决策,并针对误差数据点做更深入的分析。美中不足的是这个方法主要用于分类问题,如何应用于回归问题还需要进一步的探索。
7 相关测试
排查与调优中,我们会发现许多数据,处理流程,模型输出等方面的问题。除了对这些问题进行修复,我们也需要注意积累这些问题对应的系统性测试case,并添加到pipeline的测试流程中去。这对后续模型的各类回归验证测试,上线与运维都会有非常大的好处。由于本文并不是以MLOps为主题,这里只简单列举一下可以开发部署的测试类型。
数据输入测试,可以考虑使用各类数据质量检查库,比如著名的: https://github.com/great-expectations/great_expectations
数据转换测试。可以在数据进入到模型训练之前,加一层对训练集验证集的测试。例如对于feature encoding,空值处理,字段类型,以及train/valid的数据分布情况等做一些检查。
输出测试,例如一些固定的重要/hard case,输出合理的值。这些测试case还有助于在部署后进行快速验证,尤其是在训练与serving框架有所不同的情况下,就显得更为关键。
系统层面集成测试,验证整体pipeline,上下游数据流和多个模型的协同。另外从最终用户层面出发,需要考虑各类安全性测试,防止adversarial attack或各类abuse操作。
8 工程化与上线
关于模型上线这块,涉及到大量的MLOps相关的知识内容,并不是本文的重点。这里只简单列举一下我们在上线时会考虑的一些因素,更详细的内容后续有机会在展开讨论。
在选择具体上线的模型时,需要参考多个模型之间的离线评估比较,稳定性,性能,准确率,可解释性,在线更新能力等多方面综合考虑。
模型具体的上线和运维是另一个比较大的话题,可以采用Interleaving,A/B test,影子模型等手段,实现模型的持续部署与集成。
还有一个很现实的问题是当线上模型出现问题时,我们如何处理,是否有plan B流程可以给出一个用户可以接受的预测值。
各类监控体系,运维平台等也非常重要。前面提到的很多线下的分析排查工具,也可以为线上问题排查定位服务。持续的监控,在效果下降时触发模型自动更新训练,实现模型效果的持续稳定。
另外有一些公司分享了他们内部的实验管理框架,例如:
Airbnb在这篇文章中介绍了他们的实验管理平台,不过主要侧重在海量的实验结果查看与分析上。
Uber在这篇文章中介绍了他们的大规模回测平台,更接近于我们之前提到的离线的模型开发与验证环节中使用的工具。而这篇文章中介绍的实验平台,则主要服务于在线上进行各类复杂测试,并为他们迭代演进产品与服务设计提供数据指导。
最后,对于线上实验,还有一些开源项目可以参考,例如:Wasabi,PlanOut等。
9 Some Future Work
与AutoML结合:Why we need hybrid approach:人工建模往往效率更高,在比较少的尝试下达到较好的模型效果。主要操作是更换模型或者预处理方法。AutoML往往最终达到的效果更高,但需要的尝试次数往往远远大于人工。会有大量的操作花费在超参搜索调优上。
Human-in-the-Loop & AutoML:

也是一个非常有意思的工作,用数据库系统的分层思想来考虑human-in-the-loop人机结合AutoML系统的设计。例如像SQL般易于使用的DSL来便于用户输入问题定义与描述,然后在下层有优化器去形成经过优化的物理执行计划(在这里变成了ML workflow),并最终返回结果。
这个从成熟软件系统中汲取营养的想法还是很有想象空间的。延展一下联想到我们做算法的debugging,非常缺少类似Linux, JDK下各类tracing工具。所以软件工程的排查调优,一般来说都是能用工具确定性的抓到整个系统到底是如何在运行的,从应用层一直drill down到系统资源层都能得到相应的信息。而模型和数据的问题排查,很多时候只能在应用层改一些参数,观察这个黑盒的产出,成了所谓的“玄学”。如何能在数据,模型上开发出一套类似的tracing工具,把模型效果的排查成为相对确定性的追踪,是一个值得深入思考的方向。
从上一点延展到数据流方面,软件工程中也有很多值得借鉴的思想。例如编译器可以帮助程序员进行代码逻辑,类型等方面的自动化检查,提前发现问题。但是到了数据流这块(例如ETL),往往都只能到运行起来了才能发现问题。是否能够开发一些工具,做到数据转换逻辑和schema(可能还需要一些统计信息)结合的静态检查,来保障数据流的质量?
同理DevOps方面也有很多机器学习系统设计可以借鉴的地方,包括把数据因素结合进来,形成一套新的测试运维体系,达到持续集成,持续交付,持续调优的系统形态等(联想的有点远了……)。
Machine Teaching:

跟上面的思路类似,考虑人与模型的交互式开发与应用,从软件工程/人机交互角度去设计整体系统越来越成为一种趋势。下面这个对比表格也是非常典型的体现:
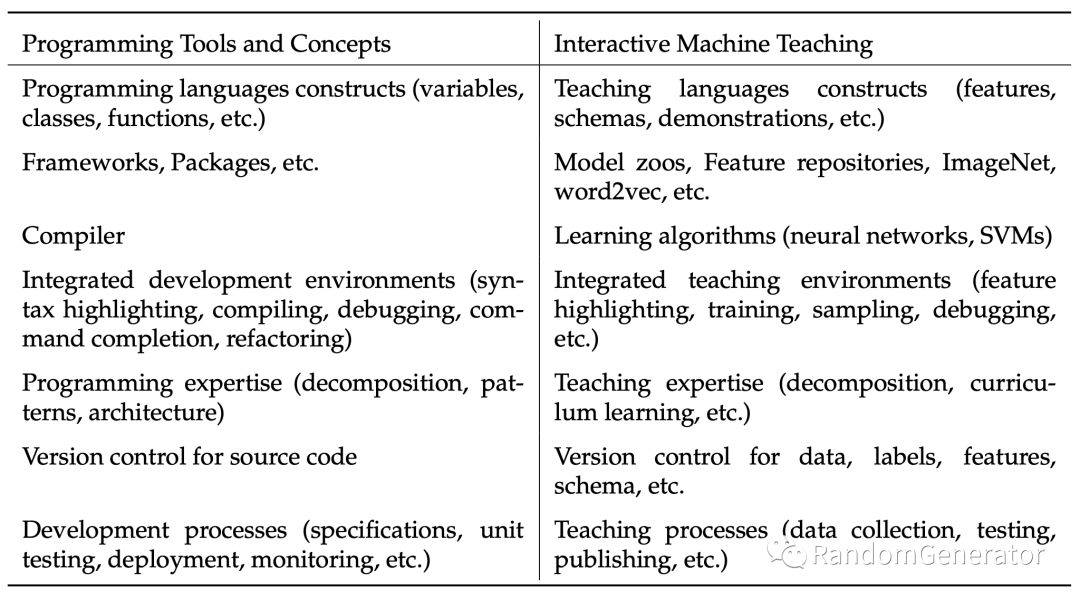
在这个方向上,Snorkel给出了不少实践的路径方案,比如他们提出的labeling function和slicing function的概念,可以很好的把人类专家经验跟机器学习结合起来,形成更加明确的迭代方向。