
CPVT:一个卷积就可以隐式编码位置信息

极市导读
当使用ViT模型时,当图像输入大小变化时会造成性能损失而本文介绍了一个新方案-CPVT。CPVT通过引入一个带有zero-padding的卷积来隐式地拜纳姆位置信息,从而省去了显式的positional embedding。>>加入极市CV技术交流群,走在计算机视觉的最前沿
对于transformer来说,由于self-attention操作是permutation-invariant的,所以需要一个positional encodings(PE)来显示地编码sequence中tokens的位置信息。ViT模型是采用学习的固定大小的positional embedding,但是当图像输入大小变化时,就需要对positional embedding来插值来适应输入tokens数量带来的变化,这一过程会造成性能损失。这里介绍的CPVT,就主要来解决这个问题,CPVT的解决方案是引入一个带有zero-padding的卷积来隐式地编码位置信息(PEG),从而省去了显式的positional embedding,最重要的是CPVT模型在输入图像大小变化时性能是稳定的。CPVT这种特性是很多图像任务所需要的,比如分割和检测往往需要大小变化的输入图像。
位置编码的影响
由于self-attention的permutation-invariant使得transformer需要一个特殊的positional encodings来显式地引入sequence中tokens的位置信息,因为无论是文本还是图像sequence,位置信息都是非常重要的。论文中以DeiT-tiny为实验模型,分别采用no positional encodings,learnable absolute positional encodings,fixed sin-cos positional encodings以及relative postional encodings等,不同的策略在ImageNet下的效果如下表所示:
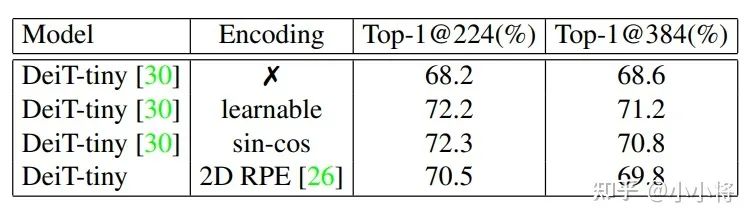
主要结论如下:
positional encodings对模型性能比较关键,不采用任何PE效果最差; relative postional encodings相比absolute positional encodings效果稍差,绝对位置编码比较重要; 采用显式的PE,当图像分辨率提升时直接对PE插值处理,性能会下降;
对于显式的PE,当图像分辨率与训练时不一致,往往需要finetune来弥补PE插值带来的性能损失。另外,论文中还提到了采用显式的PE会破坏图像tokens的“平移等价性”(translation equivariance,论文中说的是translation invariance:“平移不变性”,但是我理解应该前者更合适):当一个物体在图像中进行平移时,只是物体对应的tokens发生了变化,但是token embeddings并不会变(卷积也具有平移等价性:物体平移,“特征”也是同样平移)。但是不同位置的PE是不同的,虽然token embeddings是一样的,但是会加上不同的PE,那么平移等价性就被破坏了。
PEG:Conditional Positional Encodings
基于上面的实验分析,论文中认为一个理想的positional encoding应该满足一下条件:
处理sequence时,操作具有permutation-variant但translation-equivariance特性:对位置敏感但同时具有平移等价性; 能够自然地处理变长的sequence; 能够一定程度上编码绝对位置信息(absolute position)。
基于这三点,论文中给出的方案是采用一个带有zero padding的2D卷积( kernel size k ≥ 3)来充当positional encodings。卷积是一种局部运算,所以当tokens顺序被打乱,特征就发生了变化,卷积天生具有平移等价性,所以卷积满足第一点,对于第二点更是毫无疑问。现在关键的是第三点,因为从直觉来看,卷积具有平移等价性,那么是无法编码绝对信息,这两个特性其实是相互矛盾的。但是其实CNN已经被证明了可以编码图像的绝对位置信息,这主要是因为图像的boundary effects以及卷积的zero-padding操作造成的。感兴趣的可以看看参考文献中的论文[2-4]。
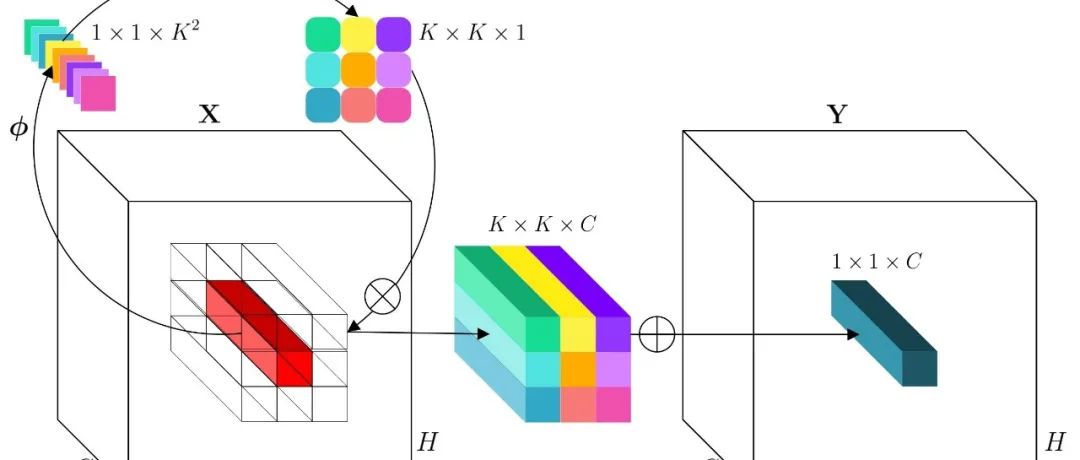
具体的,论文中设计了基于卷积的Positional Encoding Generator (PEG)来进行positional encodings,其结构图如下所示:
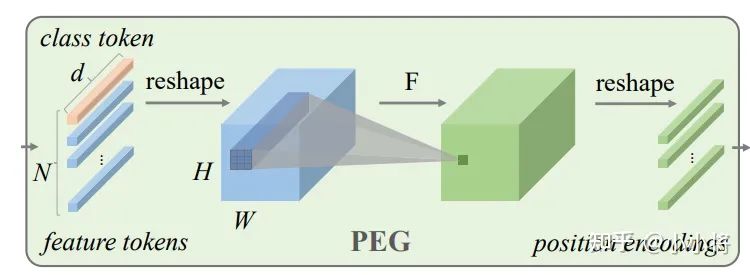
首先对input sequence 进行reshape到2-D图像空间得到,然后通过一个kernel size为k(k ≥ 3),(k−1)/2 zero paddings的2-D卷积操作,最后再reshape成token sequence。这里的zero-padding比较关键,这样才能编码绝对位置信息,为了减少计算量,论文中采用depth-wise convolution。论文中称这种编码方式为Conditional Positional Encodings,因为 positional encodings是基于限定tokens的局部关系来产生的。PEG的具体实现比较简单,PyTorch实现代码如下:
class PEG(nn.Module):def __init__(self, dim=256, k=3):self.proj = nn.Conv2d(dim, dim, k, 1, k//2, groups=dim)# Only for demo use, more complicated functions are effective too.def forward(self, x, H, W):B, N, C = x.shapecls_token, feat_token = x[:, 0], x[:, 1:] # cls token不参与PEGcnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)x = self.proj(cnn_feat) + cnn_feat # 产生PE加上自身x = x.flatten(2).transpose(1, 2)x = torch.cat((cls_token.unsqueeze(1), x), dim=1)return x
CPVT
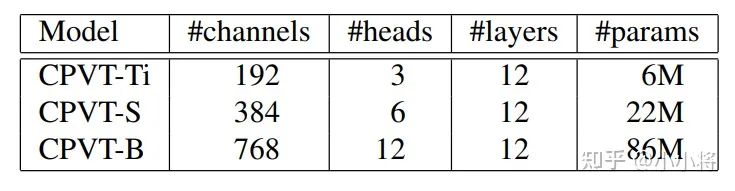
和ViT和DeiT类似,论文也基于PEG设计了三种不同的CVPT结构,如下表所示,最大的模型CPVT-B和ViT-B,DeiTB设置一样,而CPVT-S和CPVT-Ti分别和DeiT-small及DeiT-tiny采用同样的配置。
ViT和Deit模型都在transformer encoder开始之前,直接将token embeddings加上positional embeddings。而CPVT是将PEG插在第一个encoder之后效果最好,这是因为经过encoder之后的特征具有全局信息,再施加PEG可以产生更好的位置信息,这和PEG采用较大的卷积核类似,实验上也证明了这一点(另外论文中还实验证明后面的encoder也添加PEG可以实现更好的效果)。CPVT的简单实现如下所示:
import torchimport torch.nn as nnclass VisionTransformer:def __init__(layers=12, dim=192, nhead=3, img_size=224, patch_size=16):self.pos_block = PEG(dim)self.blocks = nn.ModuleList([TransformerEncoderLayer(dim, nhead, dim*4) for _ in range(layers)])self.patch_embed = PatchEmbed(img_size, patch_size, dim*4)def forward_features(self, x):B, C, H, W = x.shapex, patch_size = self.patch_embed(x)_H, _W = H // patch_size, W // patch_sizex = torch.cat((self.cls_tokens, x), dim=1)for i, blk in enumerate(self.blocks):x = blk(x)if i == 0: # 第一个encoder之后施加PEGx = self.pos_block(x, _H, _W)return x[:, 0]
CPVT相比DeiT,当输入大小增大时(从224增加到384)表现更好的效果,具体对比如下所示,可以看到CPVT的acc相比DeiT来说不降反升。论文中还有更多细致的分析,这里就不展开了。
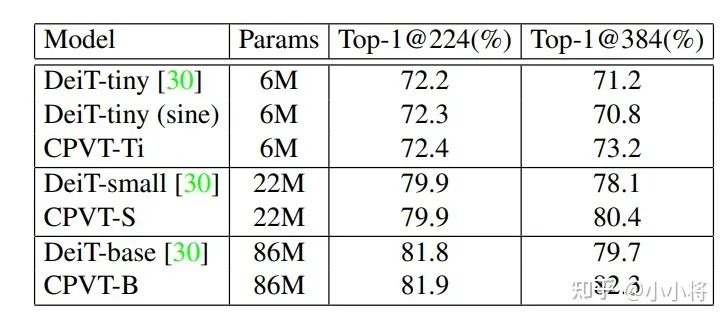
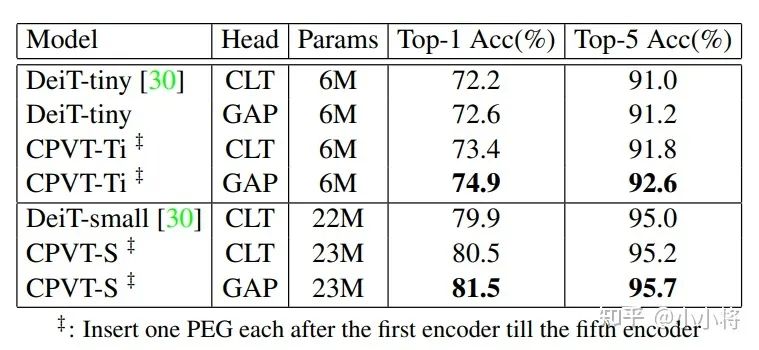
另外,论文中还提出用GAP( Global Average Pooling)来替换class token来实现分类,因为GAP是translation-invariant的(这里是平移不变性),配合PEG的平移等价性,模型就是translation-invariant的,这样效果更好。比如CPVT-Ti采用GAP相比CLT提升了1点以上。
除了CPVT,近期一篇论文CvT也发现添加卷积之后,模型完全可以去除PE,而且CvT实现了更好的效果(在ImageNet-22k预训练后, 在ImageNet-1k上top-1 accuracy达到87.7% )。
参考
Conditional Positional Encodings for Vision Transformers How Much Position Information Do Convolutional Neural Networks Encode? Position, Padding and Predictions: A Deeper Look at Position Information in CNNs On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location CvT: Introducing Convolutions to Vision Transformers
推荐阅读
2021-03-23
2021-02-23

2020-12-10

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
