
MCU HardFault问题查找和破解方法
一、HardFault产生原因和常规分析方法
二、HardFault解决方法分析
三、HardFault回溯的原理
四、操作分析流程:
五、总结
一、HardFault产生原因和常规分析方法
在嵌入式开发中,偶尔会遇到Hard Fault死机的异常,常见产生Hard Fault的原因大致有以下几类:
数组越界和内存溢出,譬如访问数组时,动态访问的数组标号超过数组长度或者动态分配内存太小等; 堆栈溢出,例如在使用中,局部变量分配过大,超过栈大小,也会导致程序跑飞; 在外设时钟开启前,访问对应外设寄存器,例如Kinetis中未打开外设时钟去配置外设的寄存器; 不当的用法操作,例如非对齐的数据访问、除0操作(默认情况下M3/M4/M7,除0默认都不会触发Fault,因为ARM内核CCR寄存器DIV_0_TRP位复位值为0,而对M0来说DIV_0_TRP位是reserved的,也不会产生Fault错误)、强行访问受保护的内存区域等;
出现Hardfault错误时,问题比较难定位的原因在于此时代码无法像正常运行时一样,在debug IDE的stack callback窗口能直接找到出错时上一级的调用函数,所以显得无从下手。
通常情况下我们都是通过在某个区间打断点,然后通过单步执行去逐步缩小“包围圈”去找到产生Hard Fault的代码位置,接着再去推敲、猜测问题的原因。对于不是很复杂的程序,这种方法是有效的,但是当用户代码量进一步增大,再用这种单步+断点去逐步缩小包围圈的方式就很难查到问题点,效率也很低。
尤其是在有操作系统的应用中,很多代码的跳转是由操作系统调度的,不是严格的顺序执行,所以很难依靠缩小包围圈的方式去有效找到问题产生的点,进一步增加了定位到Hard Fault触发原因的难度。
尽管本测试是针对NXP KW36芯片的,但该步骤和方法也适用于其他的Arm Cortex-M内核MCU;
二、HardFault解决方法分析
笔者在实际支持客户过程中也遇到这种困惑,网上的介绍资料比较零散,理论很多,很少详细描述实战操作的步骤,借助同事的点拨,摸索出两种定位Hard Fault问题的方法,在实际使用中操作性也很强,此处分别做一介绍。
第一种:心里明白徒手分析法,就是在了解Hard Fault出错原理以及程序调用压栈出栈原理的基础上(当然按照本文的练就心法,心里不明白也可以),在Debug仿真模式下徒手去回溯分析CPU通用寄存器(LR/MSP/PSP/PC),然后结合调试IDE去定位到产生Hard Fault的代码位置;
第二种:CmBacktrace 天龙大法,该方法是朱天龙大神针对 ARM Cortex-M系列MCU开发的一套错误代码自动追踪、定位、错误原因自动分析的开源库,已开源在Github上,该方法支持在非Debug模式下,自动分析定位到出错的行号,无需了解复杂的压栈出栈过程。
两者的区别在于:
前者不需要额外添加代码,缺点是只能在仿真状态下调试,需要用户对程序调用压栈/出栈原理有清晰的理解,后者的唯一的缺点是需要适当添加代码,并稍微配置工程和打印输出,优点就太多了。首先,产品真机调试时可以断开仿真器,并将错误信息输出到控制台上,甚至可以将错误信息使用 Easy Flash 的 Log 功能保存至 Flash 中,待设备死机后重启依然能够读取上次的错误信息。
这个功能真的是very very重要了,尤其在有些Hard Fault问题偶发的情况下,很多时候一天可能也复现不了一次问题,但借助CmBacktrace 天龙大法便可以轻松脱离仿真器get每一次错误,最后再配合 addr2line 工具进行精确定位出错代码的行号,方便用户进行后续的精确分析。
三、HardFault回溯的原理
为了找到Hard Fault 的原因和触发的代码段,就需要深刻理解当系统产生异常时 MCU 的处理过程: 当处理器接收一个异常后,芯片硬件会自动将8个通用寄存器组中压入当前栈空间里(依次为 xPSR、PC、LR、R12以及 R3~R0),如果异常发生时,当前的代码正在使用PSP,则上面8个寄存器压入PSP,否则就压入MSP。那问题来了,如何找到这个栈空间的地址呢?答案是SP, 但是前面提到压栈时会有MSP和PSP,如何判断触发异常时使用的MSP还是PSP呢?答案是LR。到此确定完SP后,用户便可以通过堆栈找到触发异常的PC 值,并与反汇编的代码对比就能得到哪条指令产生了异常。
总结下来,总体思路就是:首先通过LR判断出异常产生时当前使用的SP是MSP还是PSP,接着通过SP去得到产生异常时保存的PC值,最后与反汇编的代码对比就能得到哪条指令产生了异常。
回到前面的第二个问题,如何通过LR判断当前使用的MSP还是PSP呢?参见如下图,当异常产生时,LR 会被更新为异常返回时需要使用的特殊值(EXC_RETURN),其定义如下,其高 28 位置 1,第 0 位到第3位则提供了异常返回机制所需的信息,可见其中第 2 位标示着进入异常前使用的栈是 MSP还是PSP。

四、操作分析流程
理解了以上的Hard Fault回溯的原理,下面按以上提到的两种思路来实操一下。
1. 心里明白徒手分析法
前面提到,为了清晰的展现这个过程以及每个参数之间的关系,尽量把整个流程按照顺序整理到一张图中,如下图1。示例中使用的是KW36 temp_sensor_freeRTOS例子(什么例子不重要,该方法也适用于其他的MCU系列),在main函数中通过非对齐地址访问故意制造Hard Fault错误,代码如图中序号1,当程序试图访问读取非对齐地址0xCCCC CCCC位置时程序就会跳入到Hard Fault Handler中,那具体是如何通过堆栈分析定位到出错代码是在n=*p这一行呢?具体步骤如下:
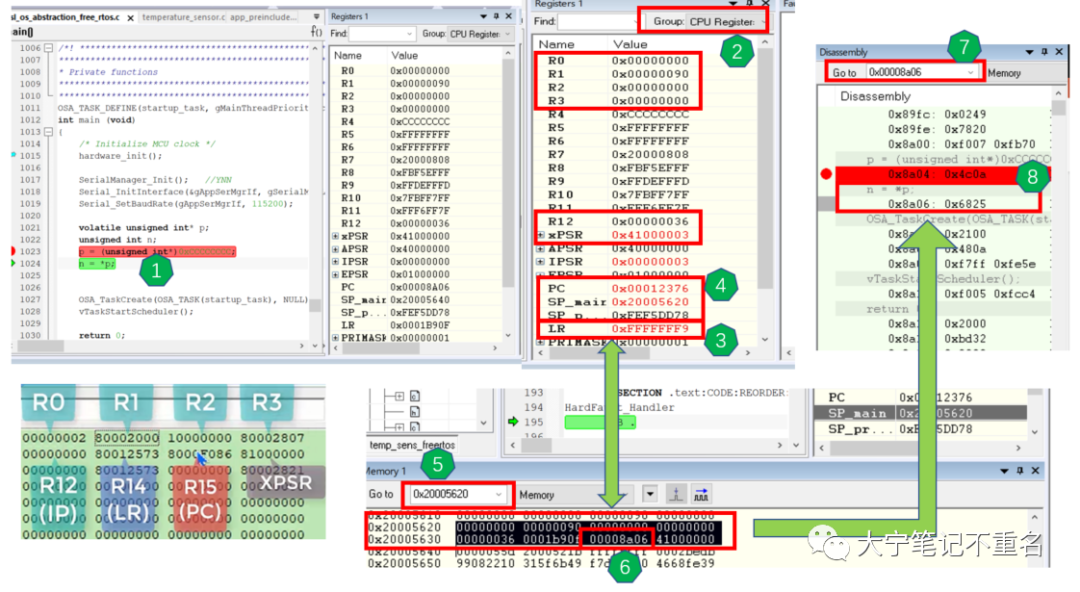
Step1:判断SP是MSP还是PSP,找出SP地址。在产生Hard Fault异常后,首先在序号2中选择“ CPU register”,不要使用默认的 “CPU register ”,否则默认只会显示MSP,不会显示PSP。然后查看序号3中LR寄存器的值表示判断当前程序使用堆栈为MSP主进程或PSP子进程堆栈,显然LR=0xFFFFFFF9 的bit2=0,表示使用的是主栈,于是得到SP=序号4中的SP_main=0x20005620;
Step2:找出PC地址。如序号5演示,打开memory串口,输入SP的地址可以找到异常产生前压栈的8个寄存器,依次为 xPSR、PC、LR、R12以及 R3~R0,序号6中便可以找到出错前PC的地址位0x00008a06;
Step3:找出代码行数。如序号7演示,打开汇编窗口,在“go to”串口输入PC地址,便可以找到具体出错时代码的位置,如序号8演示,可以发现,轻松愉快的找到了导致Hard Fault的非对齐访问的代码行;
2. CmBacktrace 天龙大法
Step1:从天龙大神的Github下载CmBacktrace的源代码包,拷贝cm_backtrace目录下的4个文件以及cmb_fault.s文件到KW36 IAR工程中,如下图序号2标识,并添加相应的搜索路径;
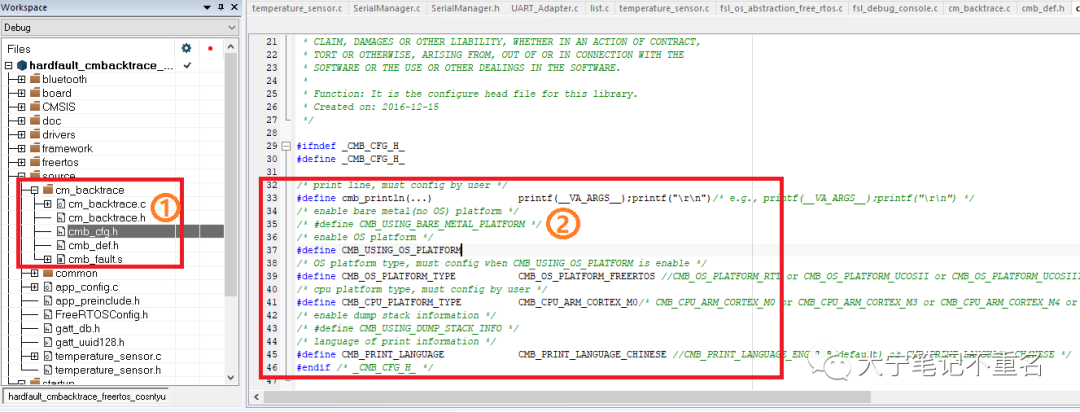
Step2:根据应用修改cmb_cfg.h的配置,需要配置的选项包括print打印信息的重定义,是否需要支持OS,OS的类型(RTT、uCOS以及FreeRTOS),ARM内核的类型,打印输出语言类型等;本实例中使用了错误信息中文打印以及FreeRTOS,所以配置如下图序号2标识。
Step3:修改FreeRTOS的task.c文件增加以下3个函数,否则在编译时会报错提示这3个函数无定义。最简单的做法就是直接使用CmBacktrace源代码包的task.c替代KW36 SDK中的task.c文件。

Step4:在启动FreeRTOS启动任务调度前初始化CmBacktrace库以及配置信息,并在startup子任务中编写故意制造错误的代码,代码如下。

Step5:配置打印信息的输出位置,建议的做法是输出到物理串口,可以方便的离线分析记录log, 但实验中为了简化以及通用(有些时候硬件设计上可能没有留硬件串口),直接把打印信息输出到IAR的Terminal IO进行显示(Kinetis SDK如何修改代码,使能打印信息输出到IAR的Terminal IO的做法详见另外一篇文档)。
Step6:运行代码,观察打印结果,可以看到打印信息中包含出错的任务名称、出错前的任务压栈的8个通用寄存器名称和内容,从图中可以一目了然的找出出错的PC指针,如果进一步去结合汇编代码可以清晰的看到其能够准确定位到代码出错的位置。
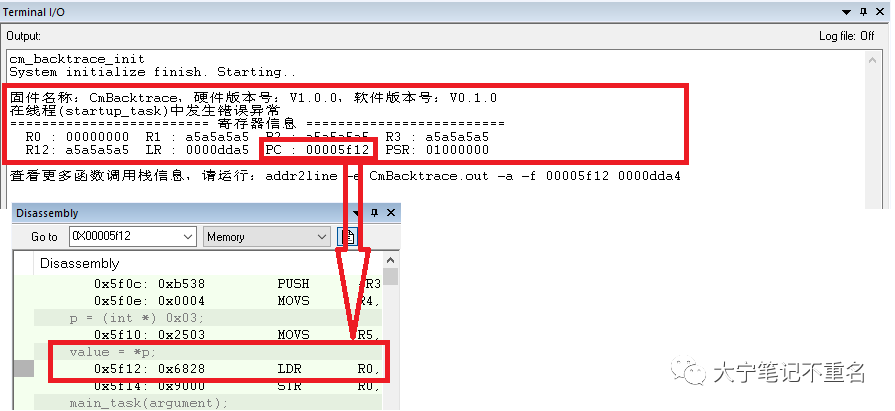
Step7:尽管在Step6中结合汇编找到了出错的代码行,但是前面吹过的一个牛逼还未实现,就是使用CmBacktrace 可以支持不挂仿真器debug状态下找到出错的代码行,那具体如何操作呢?答案其实在Step 5的打印信息中已经揭晓“查看更多函数调用栈信息,请运行:addr2line -e CmBacktrace.out -a -f 00005f12 0000dda4 ”。
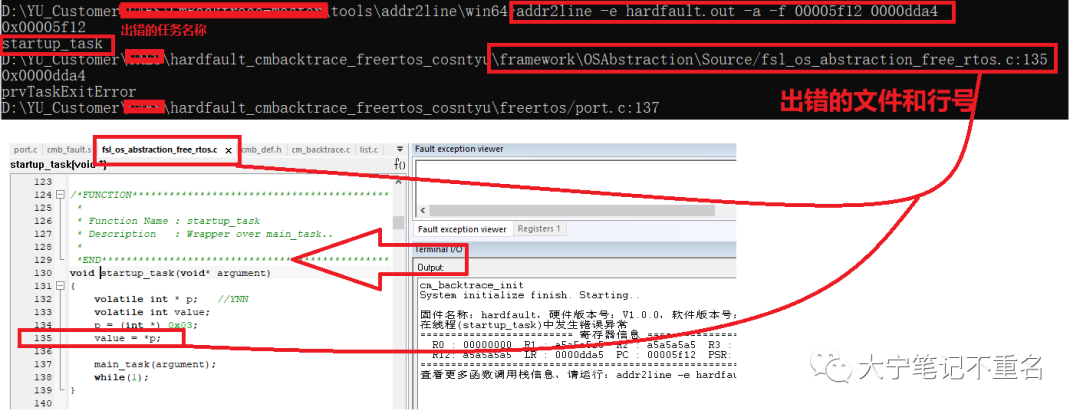
于是拷贝工程的.out文件到\tools\addr2line\win64目录下,在cmd命令行中执行以上命令,结果如下图的上半部分,可以看到出错的任务是startup_task,出错的文件是fsl_os_abstraction_free_rtos.c,出错行号是135。结合截图的下半部分的代码去看,完全验证了这三个点。
到此,使用CmBacktrace大法不轻松但很愉悦的定位到问题点了。
五、总结
对于Hard Fault问题,通过以上两种办方法可以有效的找到问题点,为后续进一步分析定位问题指明方向。徒手分析法比较简单,不需要额外添加代码,缺点是只能在仿真状态下调试,需要用户对程序调用压栈/出栈原理有清晰的理解。
CmBacktrace 天龙大法则支持离线调试分析,但繁琐点在于需要移植代码,并配置工程和打印输出,尤其在Hard Fault问题偶发(很多时候一天可能也复现不了一次问题)以及只有离线状态下才能复现问题的情况下,使用CmBacktrace 的方法去定位问题是非常高效的。至于如何将错误信息使用 Easy Flash 的 Log 功能保存至 Flash 中,待设备死机后重启依然能够读取上次的错误信息部分,时间关系笔者没有深入研究,有兴趣的可以尝试实现。