
隐藏链接反爬虫的原理和破解方法~

来源 | 志斌的python笔记
如下图所示,网站将访问详情页的URL放到网页标签中去,所以我们在爬取时,首先要先定位到这些存在URL的标签,然后将URL提取出来,对其发送请求,才能够访问详情页,并提取其数据。
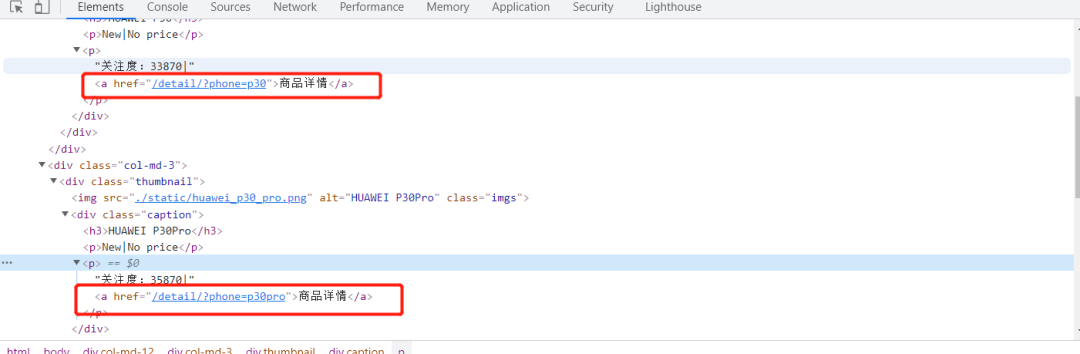
提取这个标签中的URL,相对于我们现在的水平来说,应该是一个十分简单的事情,但是当志斌书写代码来实现时,却显示被反爬了,当时我就人傻了,志斌就赶紧重新观察网页,寻找反爬虫的机制,终于在存储URL的标签中发现了问题。
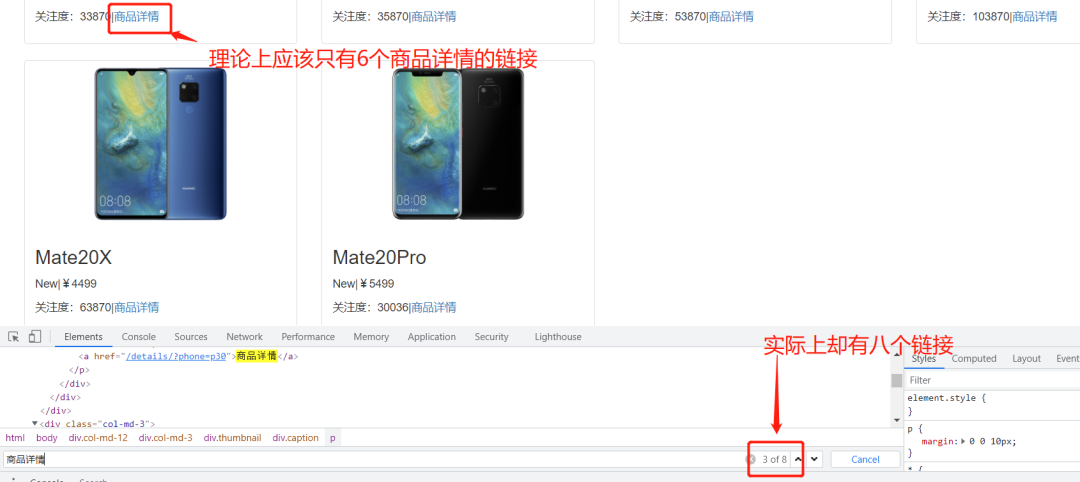
原来,在写爬虫的时候,我们观察并实验了前几个URL后,发现能够正常获取数据,就默认全局都应该这样写,但实际上并不是,这里面存储了隐藏链接用于反爬虫,如下图:
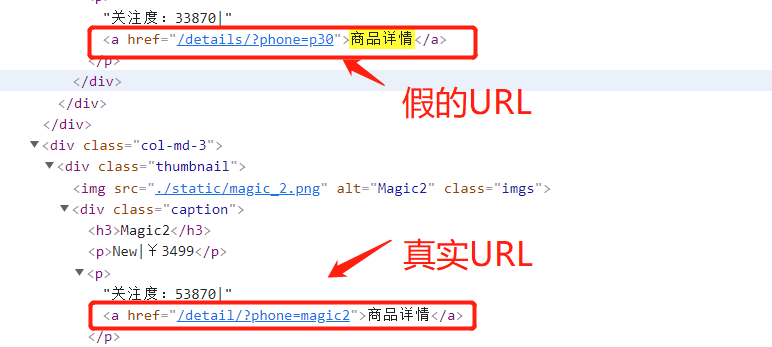
这就是典型的隐藏链接反爬虫,将真假数据混在一起,当访问假数据时,默认为爬虫程序。今天就来给大家分享一下,如何破解特征识别反爬虫之隐藏链接反爬虫。
01
原理
由于反爬虫机制是存在标签样式中的,并不存在页面中,所以用户在正常访问时是不会触碰到它的。
但是爬虫程序就不同了,因为它是从网页标签中获取数据的,一旦爬虫工程师没有注意到隐藏在标签列表中的特殊URL,就会导致爬虫程序触发反爬虫机制,从而被反爬限制。
02
破解
这类反爬虫主要存在于有许多标签列表的网页中。
因为爬虫工程师在分析网页时,通常只会分析一个点,然后由点及面,毕竟即使爬虫就是为了减少工作量,如果全部观察了,那用爬虫也没必要了。
隐藏链接反爬虫主要是通过封禁IP来进行反爬,所以爬虫工程师在爬取时可以加上IP代理池,在这篇文章中我们已经详细介绍了搭建IP代理池的方法,有兴趣的读者可以看看。
当我们在爬取标签列表较多或者数据分页较多的网站时,遇到分析的网页可以正常爬取,但是后面的数据无法正常爬取时,我们就要考虑自己是否是遇到了隐藏链接反爬虫了。
此时我们要加大对数据分析的范围,找到隐藏链接和真正链接之间的区别,然后在程序中进一步甄别这两种链接之后,就破解这类反爬虫了~
03
小结
1. 本文详细介绍了如何破解隐藏链接反爬虫,这类反爬虫要存在于标签列表较多的网站中,或者网页数据较多的网站,其中最典型的例子就是爬取微博评论爬取微博下全部评论数据~。
2. 当我们遇到分析的部分可以正常爬取,但是后面却被反爬,这时候就要考虑是否是否是遇到了隐藏链接反爬虫了。
3. 隐藏链接反爬虫属于一类非常简单的反爬虫,它主要是利用了爬虫工程师的粗心,只要我们足够细心,那么这类反爬虫对我们来说是轻而易举的。
4. 本文仅供学习参考,不做它用。