
收藏 | 推荐系统面试题(11-15)

文 | 七月在线
编 | 小七
Q1
推荐页面与搜索页特性有什么不同?
解析:
搜索带着 query 来的,结果与之相关性越高越好,不用太关心结果的多样性
推荐页用户没有明确的目的,但是有兴趣偏好和对结果的多样性需求,推荐既要准确又要多样化。
Q2
推荐系统常用的评价指标有哪些?
解析:



Q3
请画出点击率预估流程图,分为那两部分 ?
解析:
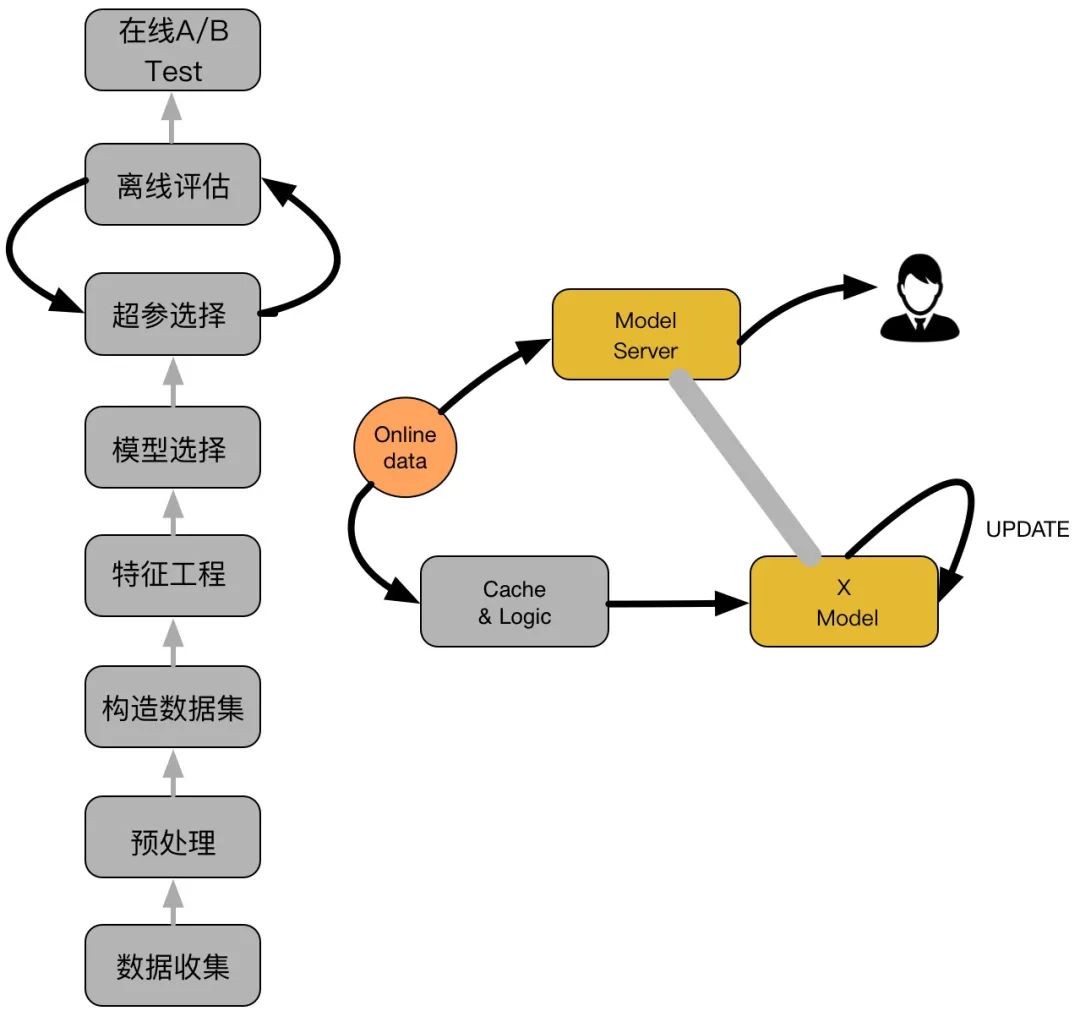
主要包括两大部分:离线部分、在线部分,其中离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,弱出现这种情况,可选择使用Online-Learning来在线更新模型Q4
使用FFM有哪些需要注意的地方?
解析:
1. 样本归一化。即在样本维度上进行归一化(除以样本的模),否则容易造成数据溢出,梯度计算失败;
2. 特征归一化。为了消除不同特征取值范围不同,量纲不同造成的问题,需要对特征进行归一化,即在每个特征维度上进行归一化,使得各特征的取值范围都在0到1之间;
3. Early stopping。一定要设置早停策略,FFM很容易过拟合;
4. 省略零值特征。零值特征对模型没有任何贡献,无论是1次项还是2次项都为0,这也是稀疏样本采用FFM的显著优势。Q5
什么是DSSM?有什么优缺点?
解析:
DSSM(Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
评论