
一份代码帮我赚了10万

文 | 闲欢
来源:Python 技术「ID: pythonall」

因为疫情的原因,现在全世界都在加速印钱,在这种“大水漫灌”的背景下,我们手头的现金加速贬值,如果通过理财跑赢通胀是我们每个人需要思考的问题。国内的投资渠道匮乏,大部分人选择银行定期或者各种宝,但是可以明显感受到的是不管是银行定期还是各种宝,现在的利率都在下降,及时通胀水平不变也是跑不赢的。
于是一部分人把目光投向了基金和证券市场。买基金就是选基金经理,相信他能帮你赚钱,买股票就是选公司,相信自己的眼光。作为新时代的青年,我还是愿意自己去选公司,用我的技术来辅助决策,构建自己的交易体系。本文就介绍一下怎样通过获取各证券公司的分析师研报来辅助我们选股。
我在前段时间用这个研究方法,找到了一只股票,当时就 ALLIN 了,再加上运气好,不到一个月时间盈利超十万,于是我美滋滋地卖出止盈。当然这里面有运气成分,但是这种方法确实可以提高选股效率,给自己辅助决策。
寻找目标页面
我们要通过分析师的研报来辅助我们选股,第一个步骤就是获取这些分析师的研报,我第一个反应就是去东方财富网站(https://www.eastmoney.com/)上寻找,这里得诚挚地感谢一下东方财富网站,证券投资方面的数据资料真的是应有尽有。
我们进入东方财富网的首页,找到“股票”栏目的“数据”子栏目:

点击进去,就到了股票数据的首页了,然后我们找到左侧的菜单,从中找到“研究报告”,选择研究报告的子菜单“个股研报”:
点击进去,就是我们的个股研报页面了,这就是我们获取研报的目标页面:
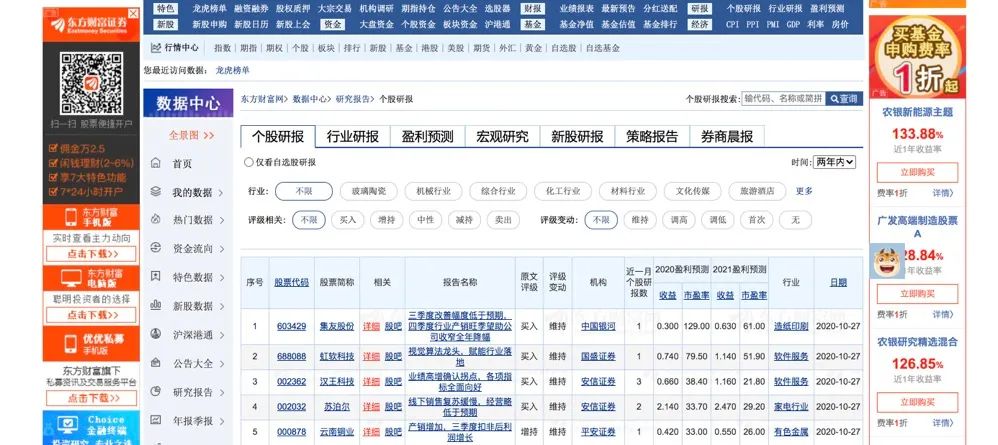
在这个页面我们可以看到最长两年内的所有个股研报,我们可以看到研报、相关个股、股票评级、股票未来盈利预测等信息,这些信息是我们选股的关键,是我们需要获取的信息。
获取数据
观察这个页面,我们可以看到这是个分页的表格,我们可能需要通过分页获取数据。不管怎么样,我们先打开开发者工具,刷新一下页面,看看能不能找到数据请求。由于首页是预加载的,我们没有发现数据请求,所以我们尝试着点击第二页看看:
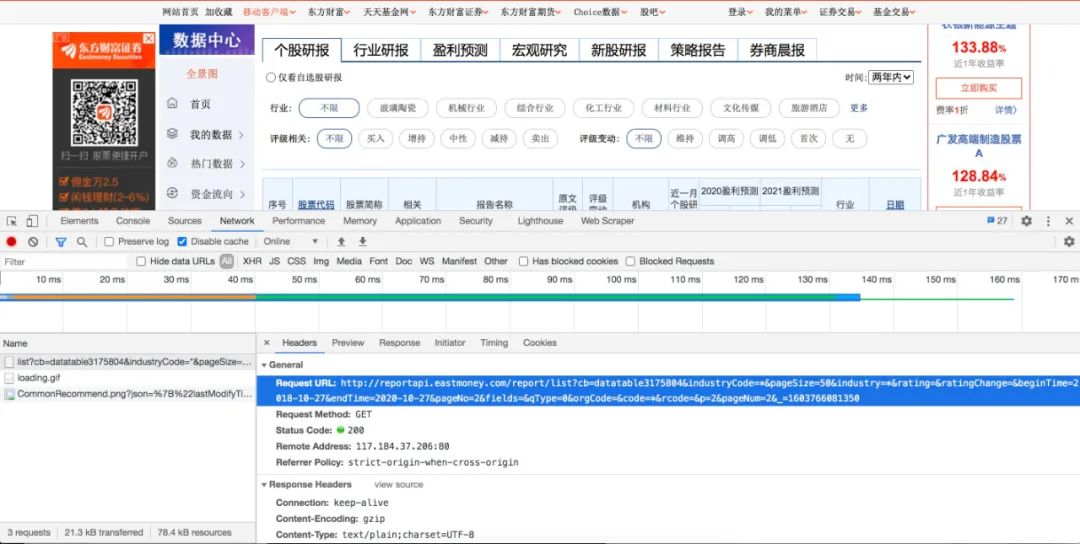
我们可以很容易地找到数据请求,我们看到的请求是这样的:
http://reportapi.eastmoney.com/report/list?cb=datatable3175804&industryCode=&pageSize=50&industry=&rating=&ratingChange=&beginTime=2018-10-27&endTime=2020-10-27&pageNo=2&fields=&qType=0&orgCode=&code=*&rcode=&p=2&pageNum=2&_=1603766081350
我们再看看这个请求返回的数据:
很显然,这就是我们需要的数据,获取到你是如此地简单!接下来我们的任务就是分析请求的 URL 和参数了。
这个 URL 也很好分析,我们可以很清楚地看到几个关键参数:
pageSize:每页记录数 beginTime:开始日期 endTime:结束日期 pageNo:页码 pageNum:页码
这几个参数是我们很容易观察出来的,我们再用不同的页面尝试几次,可以看到 pageNum 是没用的,页面用 pageNo 参数就可以。另外,我们可以看到返回的结果在 json 数据的外层包了一层,以 “datatable3175804” 开头,这个其实就是参数里面的 cb 参数。其他的一些参数是具体的条件筛选,如果你不是要具体筛选某些条件下的研报,就可以直接复制就行。
有了这些信息,我们就可以开始写程序请求数据了:
def __init__(self):
self.header = {"Connection": "keep-alive",
"Cookie": "st_si=30608909553535; cowminicookie=true; st_asi=delete; cowCookie=true; intellpositionL=2048px; qgqp_b_id=c941d206e54fae32beffafbef56cc4c0; st_pvi=19950313383421; st_sp=2020-10-19%2020%3A19%3A47; st_inirUrl=http%3A%2F%2Fdata.eastmoney.com%2Fstock%2Flhb.html; st_sn=15; st_psi=20201026225423471-113300303752-5813912186; intellpositionT=2579px",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36",
"Host": "reportapi.eastmoney.com"
}
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='east_money', charset='utf8')
self.cur = self.conn.cursor()
self.url = 'http://reportapi.eastmoney.com/report/list?cb=datatable1351846&industryCode=*&pageSize={}&industry=*&rating=&ratingChange=&beginTime={}&endTime={}&pageNo={}&fields=&qType=0&orgCode=&code=*&rcode=&p=2&pageNum=2&_=1603724062679'
def getHtml(self, pageSize, beginTime, endTime, pageNo):
print(self.url.format(pageSize, beginTime, endTime, pageNo))
response = requests.get(self.url.format(pageSize, beginTime, endTime, pageNo), headers=self.header)
html = response.content.decode("utf-8")
return html
注意这里的返回数据的编码是 utf-8,需要用 utf-8 去解码。
获取到数据后,下一步我们需要解析数据,从返回的数据中抽取我们觉得需要的重要数据:
def format_content(self, content):
if len(content):
content = content.replace('datatable1351846(', '')[:-1]
return json.loads(content)
else:
return None
def parse_data(self, items):
result_list = []
for i in items['data']:
result = {}
obj = i
result['title'] = obj['title'] #报告名称
result['stockName'] = obj['stockName'] #股票名称
result['stockCode'] = obj['stockCode'] #股票code
result['orgCode'] = obj['stockCode'] #机构code
result['orgName'] = obj['orgName'] #机构名称
result['orgSName'] = obj['orgSName'] #机构简称
result['publishDate'] = obj['publishDate'] #发布日期
result['predictNextTwoYearEps'] = obj['predictNextTwoYearEps'] #后年每股盈利
result['predictNextTwoYearPe'] = obj['predictNextTwoYearPe'] #后年市盈率
result['predictNextYearEps'] = obj['predictNextYearEps'] # 明年每股盈利
result['predictNextYearPe'] = obj['predictNextYearPe'] # 明年市盈率
result['predictThisYearEps'] = obj['predictThisYearEps'] #今年每股盈利
result['predictThisYearPe'] = obj['predictThisYearPe'] #今年市盈率
result['indvInduCode'] = obj['indvInduCode'] # 行业代码
result['indvInduName'] = obj['indvInduName'] # 行业名称
result['lastEmRatingName'] = obj['lastEmRatingName'] # 上次评级名称
result['lastEmRatingValue'] = obj['lastEmRatingValue'] # 上次评级代码
result['emRatingValue'] = obj['emRatingValue'] # 评级代码
result['emRatingName'] = obj['emRatingName'] # 评级名称
result['ratingChange'] = obj['ratingChange'] # 评级变动
result['researcher'] = obj['researcher'] # 研究员
result['encodeUrl'] = obj['encodeUrl'] # 链接
result['count'] = int(obj['count']) # 近一月个股研报数
result_list.append(result)
return result_list
这里我们把返回的数据去掉外层包装,然后解析成 json,存储在列表中。
我们获得了数据之后,接下来就是存储了,考虑到以后会经常用这份数据,并且会不断地获取最新的数据,所以我需要存储在一个方便查询并且性能稳定的介质中,这里我使用 MySQL 进行存储。
def insertdb(self, data_list):
attrs = ['title', 'stockName', 'stockCode', 'orgCode', 'orgName', 'orgSName', 'publishDate', 'predictNextTwoYearEps',
'predictNextTwoYearPe', 'predictNextYearEps', 'predictNextYearPe', 'predictThisYearEps', 'predictThisYearPe',
'indvInduCode', 'indvInduName', 'lastEmRatingName', 'lastEmRatingValue', 'emRatingValue',
'emRatingName', 'ratingChange', 'researcher', 'encodeUrl', 'count']
insert_tuple = []
for obj in data_list:
insert_tuple.append((obj['title'], obj['stockName'], obj['stockCode'], obj['orgCode'], obj['orgName'], obj['orgSName'], obj['publishDate'], obj['predictNextTwoYearEps'], obj['predictNextTwoYearPe'], obj['predictNextYearEps'], obj['predictNextYearPe'], obj['predictThisYearEps'], obj['predictThisYearPe'], obj['indvInduCode'], obj['indvInduName'], obj['lastEmRatingName'], obj['lastEmRatingValue'], obj['emRatingValue'],obj['emRatingName'], obj['ratingChange'], obj['researcher'], obj['encodeUrl'], obj['count']))
values_sql = ['%s' for v in attrs]
attrs_sql = '('+','.join(attrs)+')'
values_sql = ' values('+','.join(values_sql)+')'
sql = 'insert into %s' % 'report'
sql = sql + attrs_sql + values_sql
try:
print(sql)
for i in range(0, len(insert_tuple), 20000):
self.cur.executemany(sql, tuple(insert_tuple[i:i+20000]))
self.conn.commit()
except pymysql.Error as e:
self.conn.rollback()
error = 'insertMany executemany failed! ERROR (%s): %s' % (e.args[0], e.args[1])
print(error)
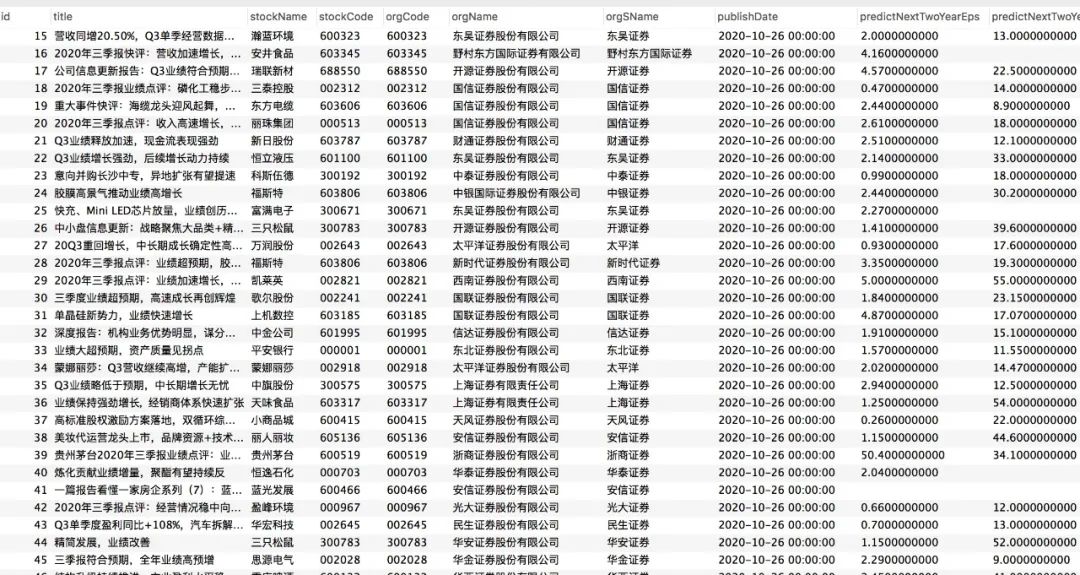
跑完程序,我的数据库里面数据是这样的:
使用数据
限于篇幅,本文先介绍获取数据部分,只要数据在手,其他的就都好说了。不过毕竟是投资股票,任何辅助决策数据都必须结合个股的行情数据,所以股票数据是必须的,这个数据的获取方式我们之前的文章中有介绍。大致说下怎样使用这份数据吧。
可以根据历史推荐之后一段时间(比如一个月、半年等)计算自推荐之日起个股的涨幅,如果某个分析师推荐多个股票都有不错的收益,那么这个分析师可以加入观察列表,后续推荐个股可以重点关注。自己也可以做一个最牛分析师榜单! 股票评级和股票评级变动这两个条件可以好好看看。个人经验来说,如果是首次推荐买入,一般可以重点看看。另外,评级变动如果是向好的方向变化的也可以重点看看,比如上次是“买入”,现在变成“强烈买入”,那么值得重点关注。 每股盈利和市盈率也可以辅助判断。可以根据预测的明年和后年的每股盈利和市盈率计算出个股大致的涨幅预期。如果预期涨幅比较大,那么是可以重点关注的。
这几个方向都是可以根据数据去做分析的,当然这些方向只是帮助我们更快地进行筛选个股,我们还需要认真地看研究报告,分析个股的基本面,才能最终决策。
总结
本文介绍了如何从东方财富网站上获取证券公司分析师的个股研报数据,基于获取到的数据,提示了几个可以分析运用的方向。限于篇幅,没有对具体的分析运用具体展开描述,大家可以自行研究。当然,如果大家对这方面感兴趣,麻烦动动手指,给我点击一个“在看”,如果“在看”人数超过30,我愿意继续写文章介绍后续的分析运用,供大家参考。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】