
哦,原来大厂是这样发布应用的!

源 / 文/
先送大家一份福利:
《美团技术年货.pdf》(2019-2021)
在2022年春节到来之际,美团技术团队精选过去3年公众号50多篇技术文章以及 20多篇国际顶会论文,整理制作成一本厚达1200多页的电子书,作为新年礼物赠送给大家。
这本电子书内容覆盖算法、前端、后端、数据、安全、测试等多个领域。
希望能对同学们的工作和学习有所帮助。
Code A Better Life

(长按扫码识别)
大家好,我是鱼皮,今天我们来讨论一个话题:一个项目上下线的正确姿势,由【码海】老师主讲。可能会出现很多 “新鲜” 的名词,大家慢慢消化~
稍微正规一点的公司都会有自动化上下线流程,因为上下线看起来简单,只有两步,「停掉应用」,「重启应用」,但里面其实还是有挺多门道的,比如:
1. 如何优雅地上下线, 涉及到 dubbo 的优雅停机,服务上线时的 JVM 参数配置等
2. 如何保证应用发布上线发现问题后快速回滚,或者上线后将新功能可能带来的影响降至最小
所以这套流程必须自动化,以下我们就以 SpringBoot 工程部署为例来对优雅的发布流程一探究竟
先来看第一个问题:
如何优雅上下线
这里面涉及到两个方面
如何优雅的下线线上正在运行的服务
如何优雅上线将要发布的服务
先来看第一个问题
如何优雅停机
目前业界在微服务架构上大多使用了 dubbo ,我们的工程也不例外。
我们知道 consumer 是通过 registry 来感知到 provider 存在的,现在要将 provider 下线自然也要通过 registry 来通知 consumer
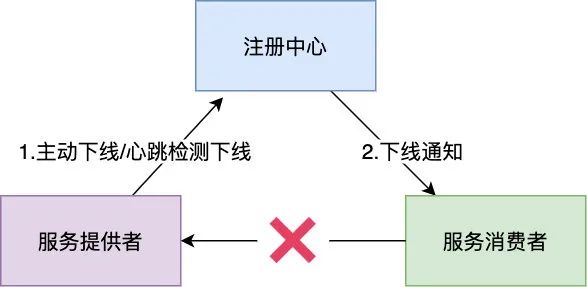
注册中心一般为 ZK 或者 nacos,所以第一步,我们首先要让服务提供者调用 unregister 以删除其在注册中心上的临时节点,这样消费者由于一直监听此临时节点,所以能感知到,于是消费者就不会再向此即将下线的提供者发起调用,但此时就能立刻停掉提供者的进程了吗?不能,因为有可能提供者还在执行消费者发起的请求,如果此时停掉很可能中断正在执行的请求导致报错,所以我们还需要等待 10 s (一般 10s 足以处理完相关的请求)左右让服务提供者把任务处理完成,然后就可以停掉当前服务了
可能有人会说你这不是说的 dubbo 的优雅停机吗,发起 kill 后让 dubbo 优雅停机停机即可,何必多此一举呢?
没错,理论上直接 kill 确实可以依赖 dubbo 的优雅停机做一些收尾的工作,但实际上在我们的下线脚本中,依然是手动执行了 unregister 并指定了 sleep 10s 然后才 kill 服务进程,为什么呢,因为在 dubbo 的 2.5.x 和 2.6.x 版本中优雅停机其实存在一定的瑕疵及需要满足一定的使用条件,在 2.7 版本中才算相对完美地实现了优雅停机方案,而我们很长一段时间使用的都是 2.6.x 的版本,所以我们相当于前置了 dubbo 优雅停机的一些工作以让下线更可靠一些
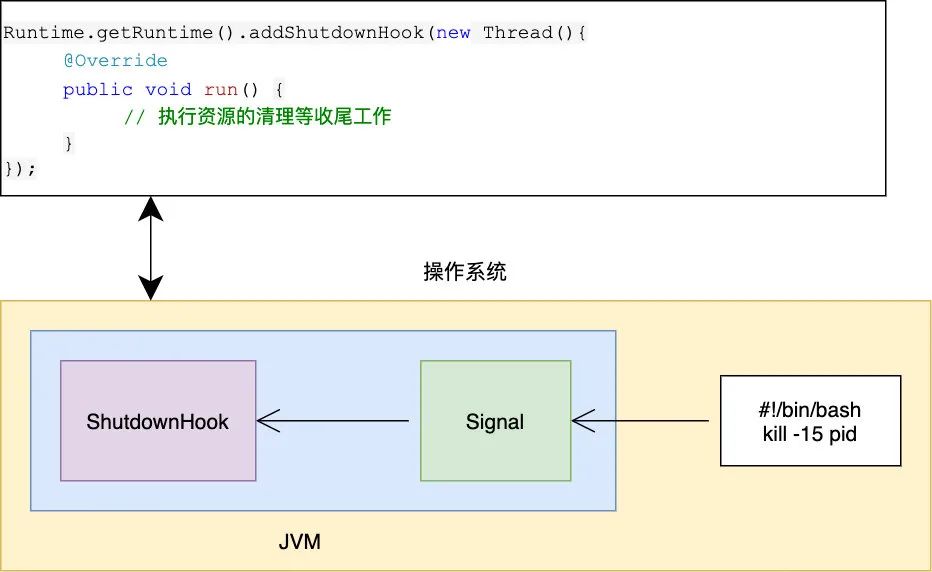
在执行完 unregister 并 sleep 10s 后此时我们就可以「kill 服务进程id」了,注意是 kill(-15) 而不是 kill -9,使用 kill -9 会立刻杀死 JVM 进程,但实际上在关闭 JVM 进程前,需要清理文件,网络套接字等资源,所以使用 kill 会更合适,这样的话 JVM 就能接收到 kill 信号,通过 shutdown hook 就能做些系统资源清理方面的工作(dubbo 的优雅停机也是依赖这个原理)了,如下
当执行 kill 后,我们每隔一秒检查一下 JVM 进程是否还存活,共检测 10 次,一共 10s
画外音:检测 10s 足够了,加上之前的 10s,总共有 20s 的时候让服务提供者来执行任务和清理资源,另外 dubbo 的优雅停机默认超时时间为 10s,超时则会强制关闭,所以 20s 理论上足够了
10s 后如果发现进程还在,那此时就要祭出大招 kill -9 直接杀死进程了,这种情况下直接杀死进程是没有问题的,因为此时服务已经被摘除 20s 了,基本上可以认为不会影响线上运行。
简单总结一下,服务下线流程如下
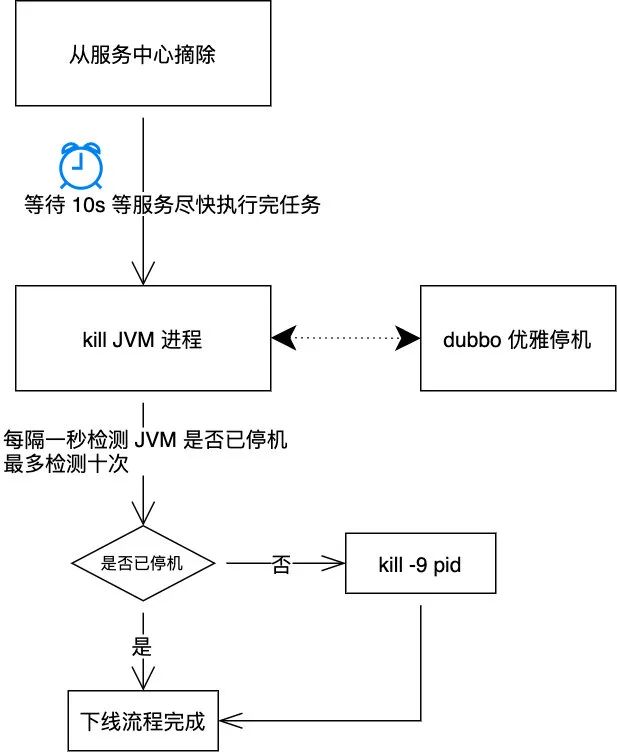
经过以上步骤我们才算做到了优雅停机,接下来我们再看看如何优雅地上线
正确的上线姿势
可能有人会说上线还不简单,通过以下形式来启动 SpringBoot 不就完了
java -jar jar包路径 --spring.config.location=xxx --spring.pid.file=xxx
如果在业务刚起步阶段这样设置确实没有问题,毕竟本身也没啥业务量,但如果你们的业务量上升到一定规模后这样简单的启动是不行的,不然动不动就 YGC/FullGC 或者 OOM 了没有日志咋办,所以你需要根据你的业务量来压测,设置类似如下的 JVM 的参数
-server -Xmx5g -Xms5g -Xmn2g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -Xss256k -XX:SurvivorRatio=8 \
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 \
-XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${APPLICATION_LOG_DIR} -Djava.security.egd=file:/dev/./urandom
注意上面的参数中有个 -Djava.security.egd=file:/dev/./urandom ,这个是干啥用的呢?
在工程中很可能会有使用随机数的场景,SecureRandom 在 java 各种组件中使用广泛,可以可靠的产生随机数,但大量产生随机数据的时候,性能会降低,所以我们上面这个设置将会加快随机数的产生过程。
光设置 JVM 参数还不够,你总要监控你的应用是否健康吧,这需要采集你机器的相关指标以便以可视化的形式展现出来,如下

所以你需要安装探针,我们用的 Skywalking,这样就需要以 Java agent 的形式来启动,如下
-javaagent:$SW_AGENT_JAR -Dskywalking_config=$SW_AGENT_CONFIG
综上,Java 的启动参数配置如下
java -jar jar包路径 --spring.config.location=xxx --spring.pid.file=xxx -server -Xmx5g -Xms5g -Xmn2g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -Xss256k -XX:SurvivorRatio=8 \
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 \
-XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${APPLICATION_LOG_DIR} -Djava.security.egd=file:/dev/./urandom -javaagent:$SW_AGENT_JAR -Dskywalking_config=$SW_AGENT_CONFIG
配置好之后终于可以启动了,项目大了后启动一般比较慢,所以我们可以等个 20s 然后再检测是否启动成功,如果不成功通过告警的形式提醒开发人员,但如果成功了的话你就可以放心上线了?非也,你还需要做健康检查,检测 db 连接,redis 等是否真正可用,一般情况下, 项目都会有如下健康检查逻辑
@Service(protocol = {"rest"})
public class HealthCheckServiceImpl implements HealthCheckService {
@Resource
private TestDAO TestDAO;
@Override
public String getHealthStatus() {
List testDOS =
TestDAO.getResult(123);
Assert.isTrue(testDOS != null, "dao 有问题 null");
// redis 检测
// 此处省略其它检测
return "health";
}
}
这样 JVM 启动后脚本通过调用 curl http://ip:port/service/health/deepCheck 来判断服务是否真正上线了,结果返回 「health」 才说明服务真正可用了
滚动发布与蓝绿发布
接下来我们来看看业务普遍采用的两种发布模式:滚动发布和蓝绿发布
什么是滚动发布
滚动发布:一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本,一图胜千言
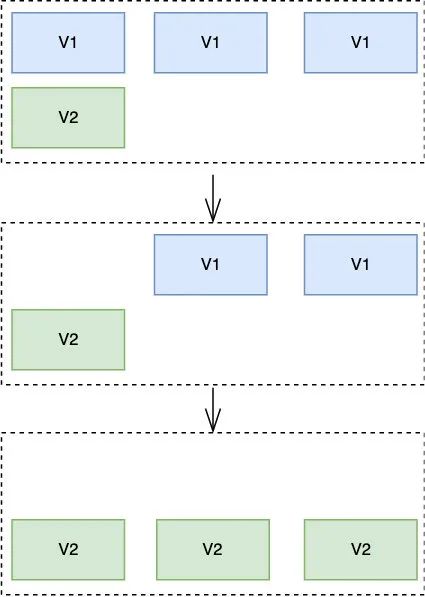
滚动发布应该是业界普遍采用的方案了,这种方案简单,但是如果一旦发现问题要回滚就麻烦了,得把服务一台台停掉并启用老的包,影响时间会比较长,于是人们又提出了蓝绿部署
什么是蓝绿部署
为了解决滚动发布回滚慢的问题,人们提出了蓝绿发布,首先把新包部署到新集群上,待新集群部署成功后,在网关基于 dubbo 路由来将流量打到新集群
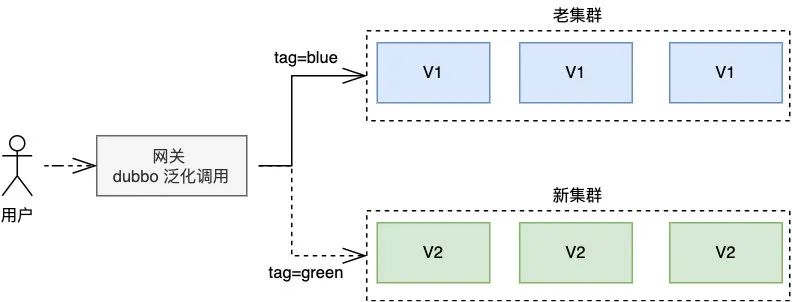
这样的话如果一旦发现新功能有问题,网关可以根据 tag 马上将流量切回到老集群,相当于实时回滚,用起来确实给力,唯一的缺点也是很明显的,费钱!因为要准备和原集群一样多的机器,所以适合土豪玩家,我们集团曾经搞过,后来现金流紧张,把这玩意给停了
以上就是发布服务上下线需要注意的一些点,虽然本文发布是以 Java 项目为例,但其实其他项目发布注意的点也是大同小异的,无非就是两点
1 是注意下线时的优雅停机,预留足够多的时候来让服务做些资源清理的工作
2 是发布上线时需要根据你的业务量提前做压测,做好监控相关的工作以便提升服务的可用性
END


顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」