
Spark共享变量
Spark 提供了两类共享变量:广播变量(Broadcast variables)/累加器(Accumulators)
广播变量
创建广播变量的方式:
从普通变量创建广播变量 : 由 Driver 分发各 Executors- 从分布式数据集创建广播变量 : Driver 拉取各 Executors 分区数并合并, 再分发各Executors
普通变量广播
普通变量分发 :
普通变量在 Driver 端创建 (非分布式数据集),要把普通变量分发给每个 Task- 以 Task 粒度分发,当有 n 个 Task,变量就要分发 n 次- 在同个 Executor 内部,多个不同的 Task 多次重复缓存同样的内容 , 对内存资源浪费
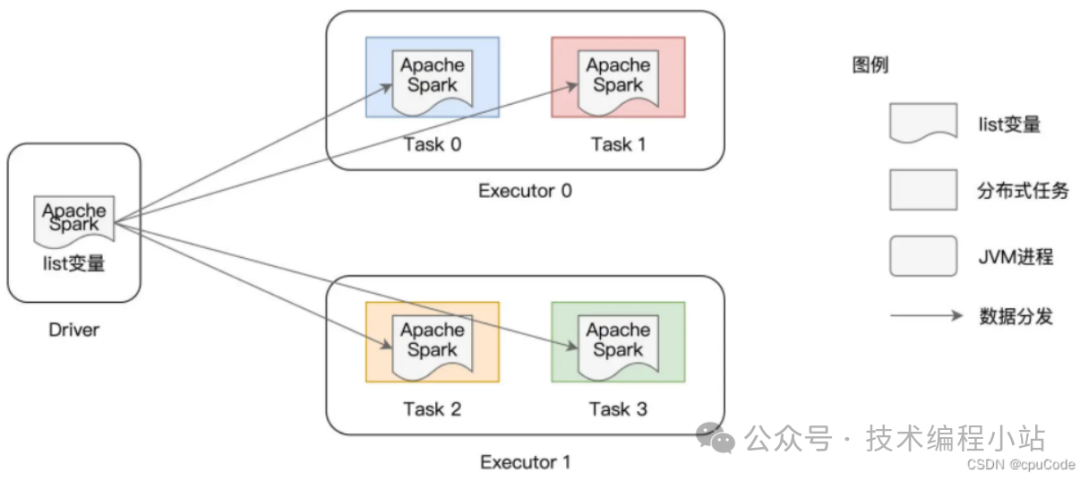
广播变量分发:
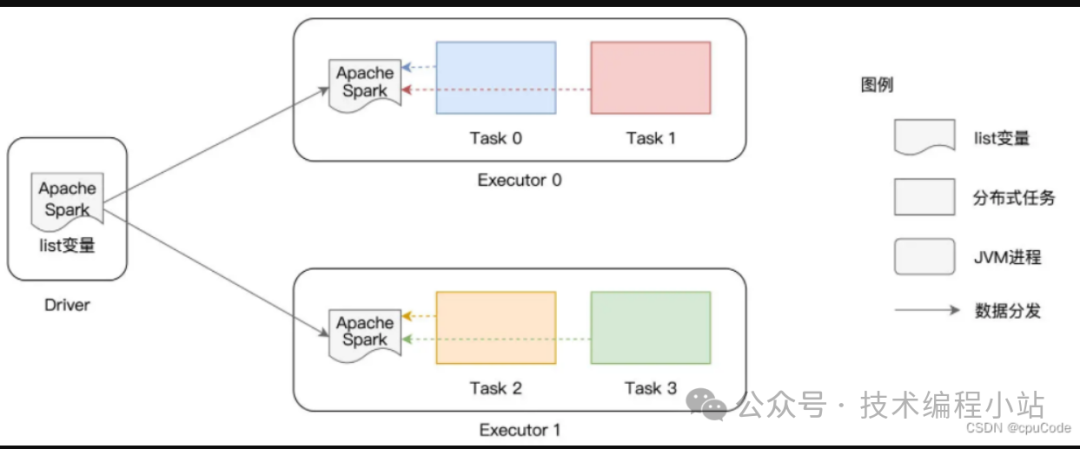
以 Executors 粒度分发,同个 Executor 的 各 Tasks 互相拷贝。即:变量分发数 = Executors 数 普通变量广播:
val list: List[String] = List("Apache", "Spark")
val bc = sc.broadcast(list)
分布式数据集广播
创建分布式数据集广播:
val userFile: String = "hdfs://ip:port/rootDir/userData"
val df: DataFrame = spark.read.parquet(userFile)
val bc_df: Broadcast[DataFrame] = spark.sparkContext.broadcast(df)
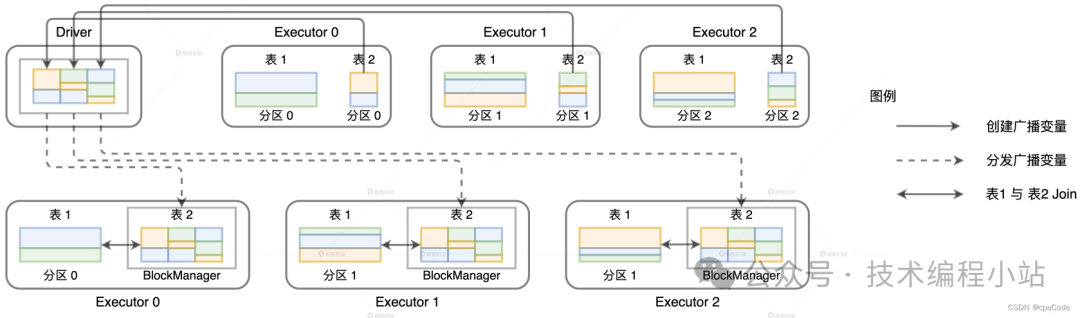
分布式数据集广播过程 :
Driver 从所有的 Executors 拉取这些数据分区,再在本地构建全量数据- Driver 把合并的全量数据分发给各个 Executors- Executors 收到数据后,缓存到存储系统的 BlockManager
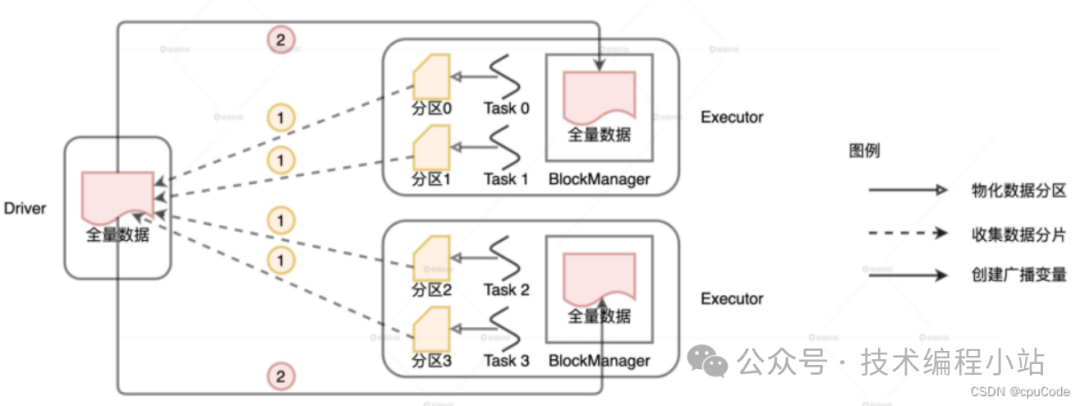
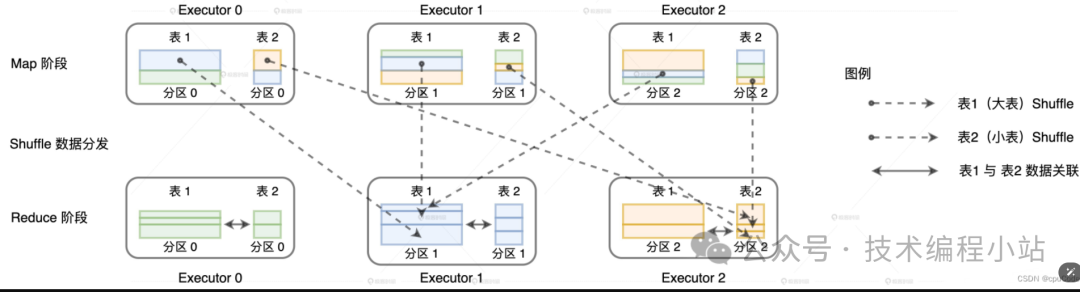
克制 Shuffle
无优化时,默认用 Shuffle Join
val transactionsDF: DataFrame = _
val userDF: DataFrame = _
transactionsDF.join(userDF, Seq("userID"), "inner")
Shuffle Join 的过程 :
对关联俩表分别进行 Shuffle1. Shuffle 的分区规则:先对 Join keys 计算哈希值,再对哈希值进行分区数取模1. Shuffle 后,同 key 的数据会在同个 Executors1. Reduce Task 对 同 key 的数据进行关联
优化代码:
import org.apache.spark.sql.functions.broadcast
val transactionsDF: DataFrame = _
val userDF: DataFrame = _
val bcUserDF = broadcast(userDF)
transactionsDF.join(bcUserDF, Seq("userID"), "inner")
广播过程:
Driver 从所有 Executors 收集 userDF 的所有数据分片,再在本地汇总数据1. 给每个 Executors 都发送一份全量数据,各自在本地关联1. 利用广播变量 ,就能避免 Shuffle
强制广播
广播注意点:
创建广播变量越大,网络开销和 Driver 内存也就越大。当广播变量大小 > 8GB,就会直接报错- Broadcast Joins 不支持全连接(Full Outer Joins)- 左连接(Left Outer Join)时,只能广播右表- 右连接(Right Outer Join)时,只能广播左表
配置项
两张 Join 表,只要其中一张表的尺寸 < 10MB,就会采用 Broadcast Joins 做数据关联
# 采用 Broadcast Join 实现的最低阈值
spark.sql.autoBroadcastJoinThreshold 10m
数据在存储/内存大小差异的原因:
为了存储/访问效率,数据采用 Parquet/ORC 格式进行落盘- JVM 一般需要比数据原始更大的内存空间来存储对象 准确预估表在内存的大小:
把表缓存到内存,如: DataFrame/Dataset.cache1. 读取执行计划的统计数据
val df: DataFrame = _
df.cache.count
val plan = df.queryExecution.logical
val estimated: BigInt = spark
.sessionState
.executePlan(plan)
.optimizedPlan
.stats
.sizeInBytes
Join Hints
Join Hints :在开发中用特殊的语法,告知 Spark SQL 运行时采用这种 Join
val table1: DataFrame = spark.read.parquet(path1)
val table2: DataFrame = spark.read.parquet(path2)
table1.createOrReplaceTempView("t1")
table2.createOrReplaceTempView("t2")
val query: String = "select /*+ broadcast(t2) */ * from t1
inner join t2 on t1.id = t2.id"
val queryResutls: DataFrame = spark.sql(query)
DataFrame 的 DSL 语法中使用 Join Hints :
table1.join(table2.hint("b"roadcast"), Seq("key"), "inner")
broadcast
广播数据表 :
import org.apache.spark.sql.functions.broadcast
table1.join(broadcast(table2), Seq(“key”), “inner”)
广播设置要点:以广播阈值配置为主,以强制广播为辅
累加器
累加器的作用:全局计数(Global counter) SparkContext 提供了 3 种累加器 :
longAccumulator:Long 类型的累加器- doubleAccumulator :对 Double 类型的数值做全局计数- collectionAccumulator :定义集合类型的累加器 累加器在 Driver 端定义,在 RDD 算子中调用 add 进行累加。最后在 Driver 端调用 value ,就能获取全局计数结果
// 定义 Long 类型的累加器
val ac = sc.longAccumulator("Empty string")
def f(x: String): Boolean = {<!-- -->
if(x.equals("")) {<!-- -->
// 当遇到空字符串时,累加器加 1
ac.add(1)
return false
} else {<!-- -->
return true
}
}
//用 f 对 RDD 进行过滤
val cleanWordRDD: RDD[String] = wordRDD.filter(f)
// 作业执行完毕,通过调用 value 获取累加器结果
ac.value
评论