
golang 性能诊断看这篇就够了
1.1 CPU

平均负载:0.14 0.07 0.06 分别表示过去1分钟、5分钟、15分钟的机器负载的平均值,根据经验,若负载数值小于0.7*CPU个数则正常,超过或者达到CPU核数的四五倍,则系统的负载就明显偏高。
CPU的上下文切换情况可通过vmstat命令可以查看,上下文切换发生的场景有如下几种:
时间片用完,CPU正常调度下一个任务
被其他优先级更高的任务抢占
执行任务碰到I/O阻塞,挂起当前任务,切换到下一个任务
用户代码主动挂起当前任务让出CPU
多任务抢占资源,因没抢到而被挂起
硬件中断
1.2 Memory
从操作系统角度,内存关注应用进程是否足够,可以使用 free –m 命令查看内存的使用情况。
通过 top 命令可以查看进程使用的虚拟内存 VIRT 和物理内存 RES,根据公式 VIRT = SWAP + RES 可以推算出具体应用使用的交换分区(Swap)情况,使用交换分区过大会影响 应用性能,可以将 swappiness 值调到尽可能小。
1.3 I/O
I/O 包括磁盘 I/O 和网络 I/O,一般情况下磁盘更容易出现 I/O 瓶颈。通过iostat可以查看磁盘的读写情况,通过 CPU 的 I/O wait 可以看出磁盘 I/O 是否正常。
如果磁盘 I/O 一直处于很高的状态,说明磁盘太慢或故障,成为了性能瓶颈,需要进行应用优化或者磁盘更换。
除了常用的 top、 ps、vmstat、iostat 等命令,还有其他 Linux 工具可以诊断系统问题,如 mpstat、tcpdump、netstat、pidstat、sar 等 更多Linux性能诊断工具如下图:

Profiling 收集程序执行过程中的具体事件,并抽样统计 方便精确定位问题
Tracing 一种检测代码的方法,用于分析调用或用户请求整个生命周期中的延迟,且可以跨多个Go进程。
2.1 profiling
1.首先profiling代码埋入
import _ "net/http/pprof"func main() {go func() {log.Println(http.ListenAndServe("0.0.0.0:9090", nil))}()...}
2.保存特定时间点的profile,例如保存heap信息
curl http://localhost:6060/debug/pprof/heap --output heap.tar.gz3.使用go tool pprof 分析保存的profile快照,如分析上述heap信息
go tool pprof heap.tar.gz2.1.1 CPU Profiling
pprof可以帮忙我们分析出函数执行缓慢问题 CPU占用过高问题
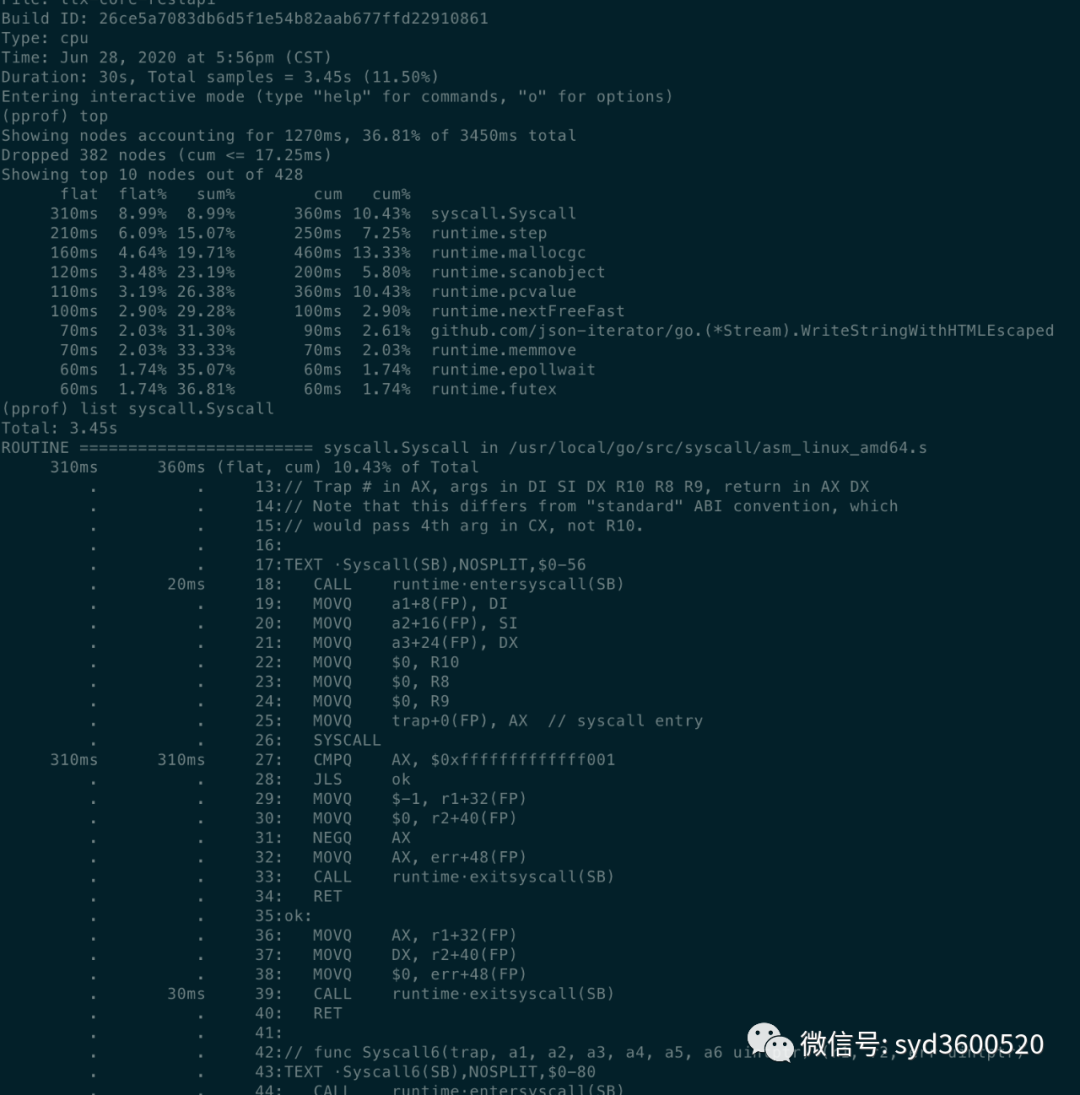
go tool pprof http://localhost:6060/debug/pprof/profile?second=10命令行方式: 常用命令 top list traces
top: 查看按照占用内存或cpu多少排序的前10的函数信息
flat:当前函数占用的CPU时长(不包含其调用的其他函数)
flat%:当前函数使用CPU占总CPU时长的百分比
sum%:前面每一行flat百分比的和
cum: 累计量,当前函数及其子函数占用CPU时长
cum%:累计量占总量的百分比
cum>=flat
list: 查看某个函数的代码 以及该函数每行代码的指标信息
traces:打印所有函数调用栈 以及调用栈的指标信息
UI界面方式:从服务器download下生成的sample文件
go tool pprof -http=:8080 pprof.xxx.samples.cpu.001.pb.gz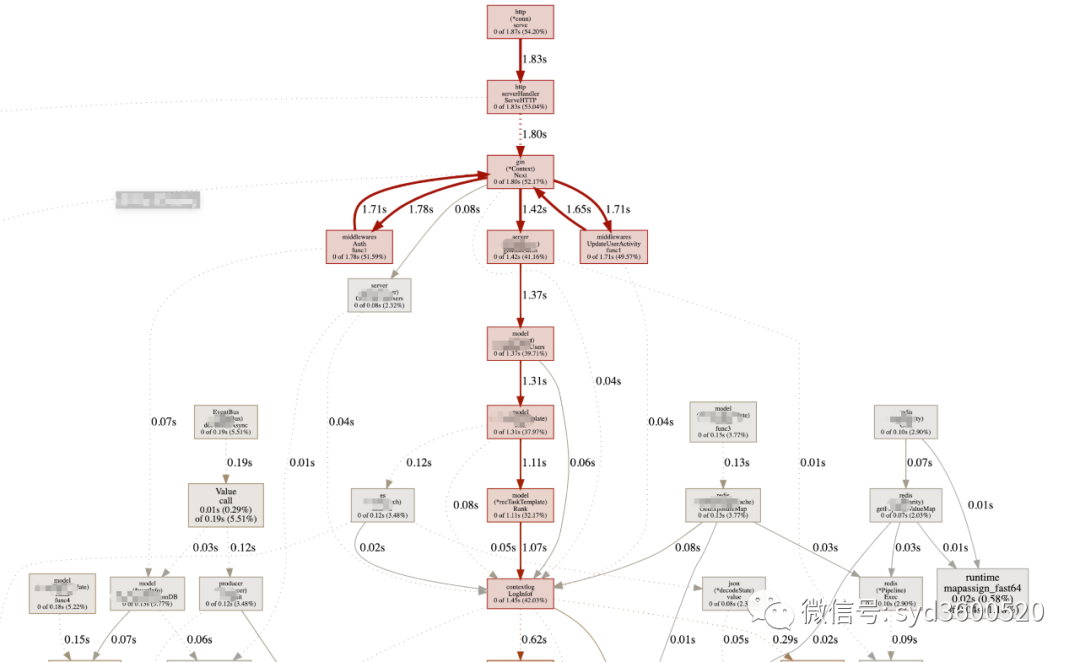
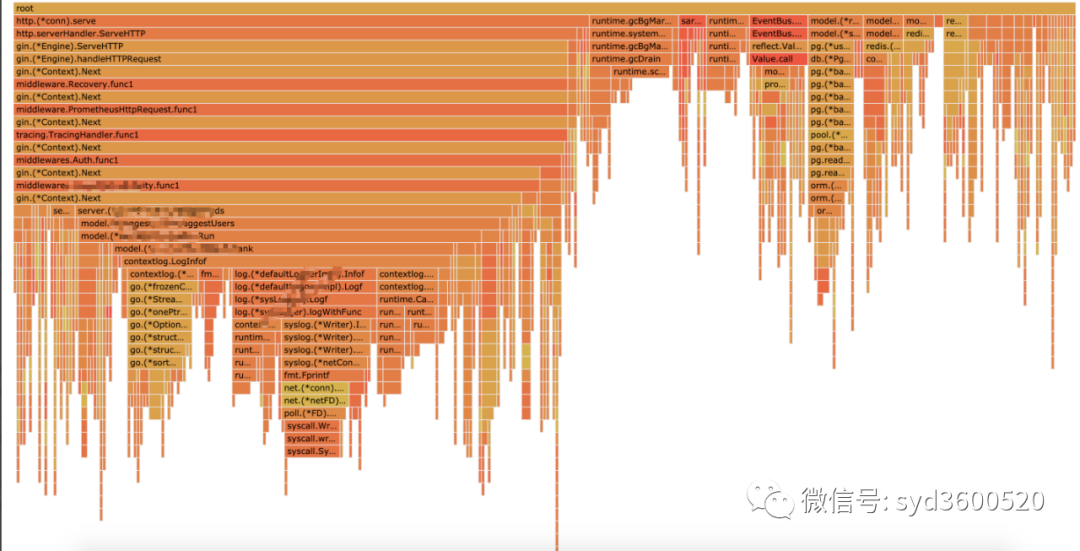
Flame graph很清晰得可以看到当前CPU被哪些函数执行栈占用
1.2 Heap Profiling
go tool pprof http://localhost:6060/debug/pprof/heap?second=10命令行 UI查看方式 同理
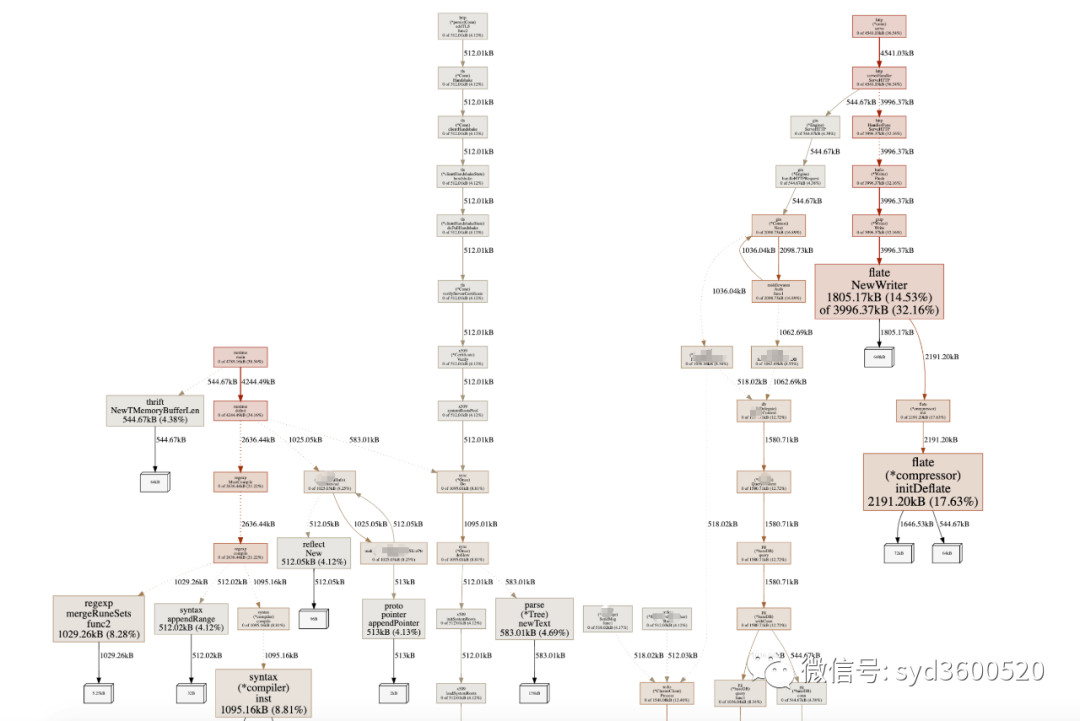

graph中方框越大 占用内存越多 火焰图 宽度越大 占用内存越多
SAMPLE->inuse_objects可以查看当前的对象数量 这个参数对于分析gc线程占用较高cpu时很有用处 它侧重查看对象数量
inuse_space图可以查看具体的内存占用
毕竟对于10个100m的对象和1亿个10字节的对象占用内存几乎一样大,但是回收起来一亿个小对象肯定比10个大对象要慢很多。
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap : 分析应用程序的常驻内存占用情况 (默认)go tool pprof -alloc_objects http://localhost:6060/debug/pprof/heap: 分析应用程序的内存临时分配情况
1.3 并发请求问题 查看方式跟上面类似。
go tool pprof http://localhost:6060/debug/pprof/goroutinego tool pprof http://localhost:6060/debug/pprof/blockgo tool pprof http://localhost:6060/debug/pprof/mutex
2.2 tracing
trace并不是万能的,它更侧重于记录分析 采样时间内运行时系统具体干了什么。
收集trace数据的三种方式:
1. 使用runtime/trace包 调用trace.Start()和trace.Stop()
2. 使用go test -trace=
3. 使用debug/pprof/trace handler 获取运行时系统最好的方法
例如,通过
go tool pprof http://localhost:6060/debug/pprof/trace?seconds=20 > trace.out获取运行时服务的trace信息,使用
go tool trace trace.out会自动打开浏览器展示出UI界面
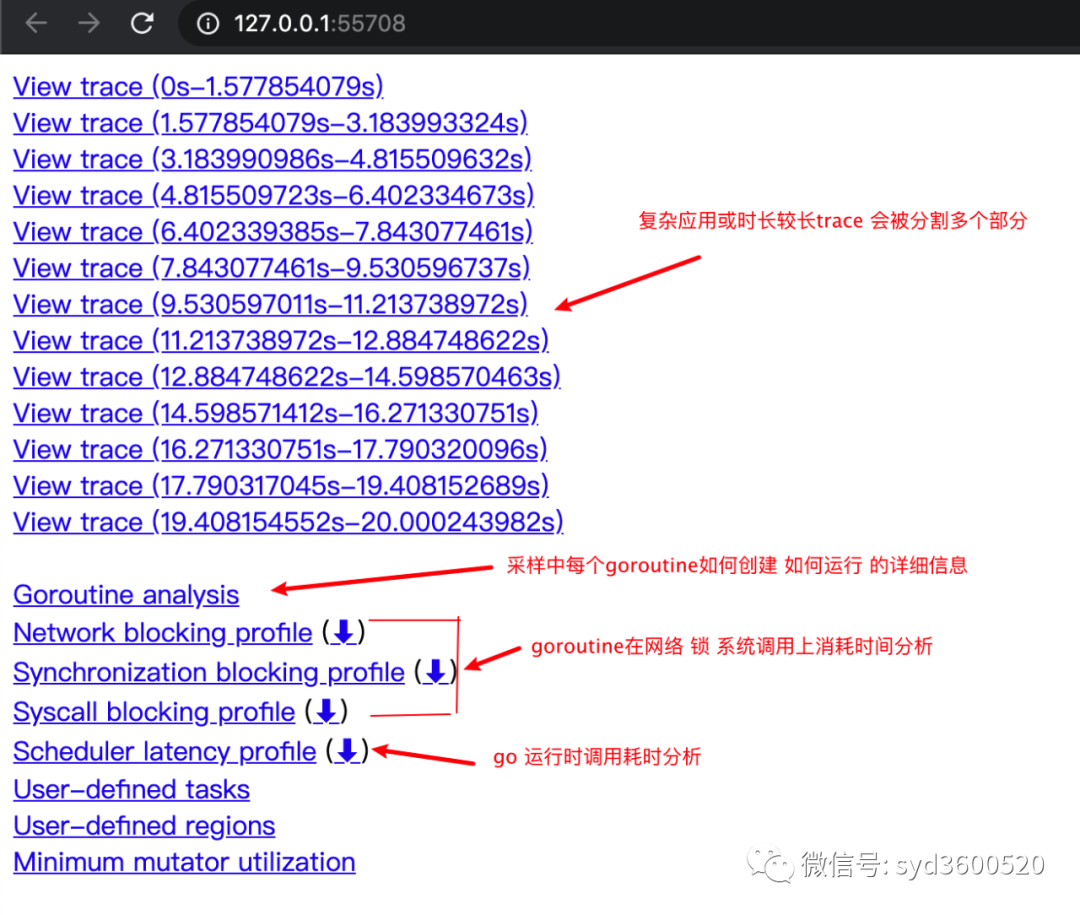
其中trace view 只能使用chrome浏览器查看,这里go截止1.14版本存在一个 bug,解决办法如下:
go tool trace trace.out 无法查看trace viewgo bug:https://github.com/golang/go/issues/25151mac 解决版本:安装gotipgo get golang.org/dl/gotipgotip downloadthen 使用 gotip tool trace trace.out即可
获取的trace.out 二进制文件也可以转化为pprof格式的文件
go tool trace -pprof=TYPE trace.out > TYPE.pprofTips:生成的profile文件 支持 network profiling、synchronization profiling、syscall profiling、scheduler profilinggo tool pprof TYPE.pprof
使用gotip tool trace trace.out可以查看到trace view的丰富操作界面:
操作技巧:
ctrl + 1 选择信息
ctrl + 2 移动选区
ctrl + 3 放大选区
ctrl + 4 指定选区区间
shift + ? 帮助信息
AWSD跟游戏快捷键类似 玩起来跟顺手
整体的控制台信息 如下图:
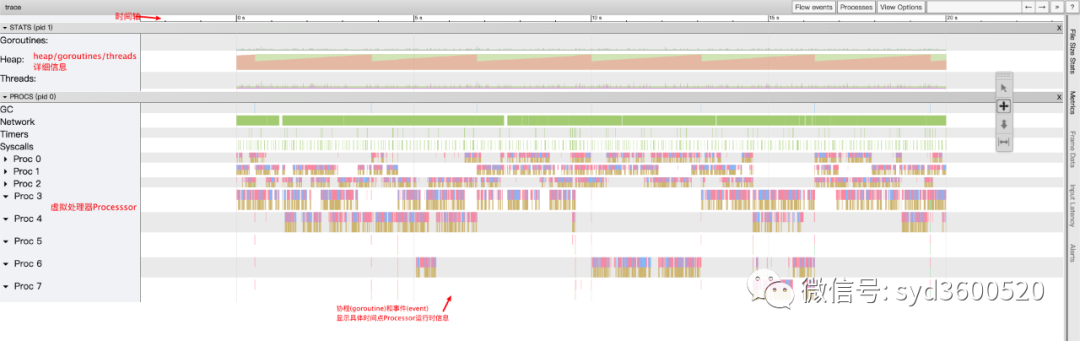
时间线: 显示执行的时间单元 根据时间的纬度不同 可以调整区间
堆: 显示执行期间内存的分配和释放情况
协程(Goroutine): 显示每个时间点哪些Goroutine在运行 哪些goroutine等待调度 ,其包含 GC 等待(GCWaiting)、可运行(Runnable)、运行中(Running)这三种状态。
goroutine区域选中时间区间

OS线程(Machine): 显示在执行期间有多少个线程在运行,其包含正在调用 Syscall(InSyscall)、运行中(Running)这两种状态。
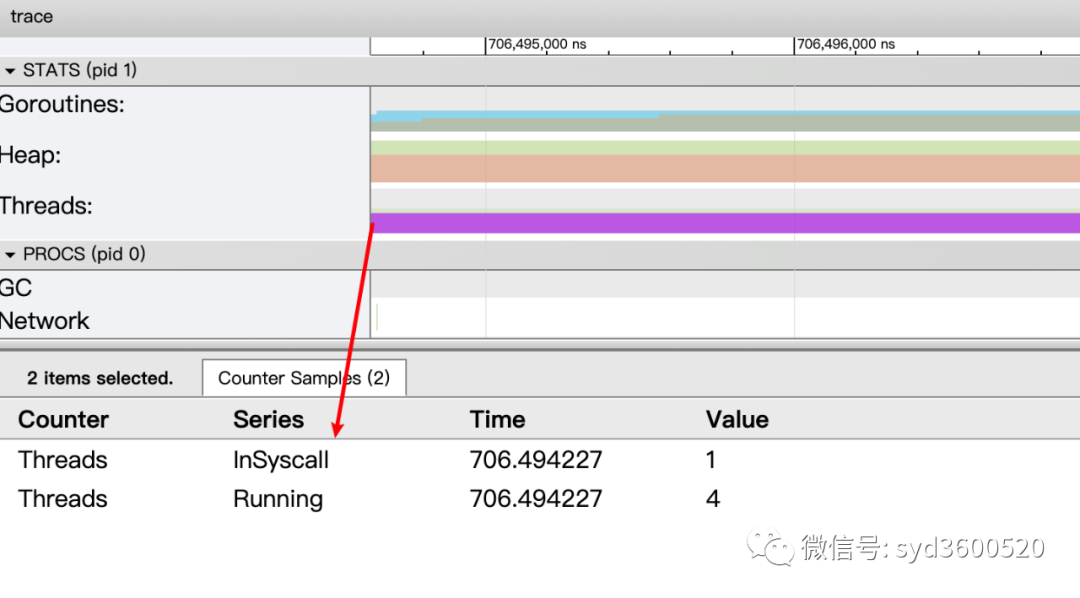
虚拟处理器Processor: 每个虚拟处理器显示一行,虚拟处理器的数量一般默认为系统内核数。数量由环境变量GOMAXPROCS控制
协程和事件: 显示在每个虚拟处理器上有什么 Goroutine 正在运行,而连线行为代表事件关联。
每个Processor分两层,上一层表示Processor上运行的goroutine的信息,下一层表示processor附加的事件比如SysCall 或runtime system events

ctrl+3 放大选区,选中goroutine 可以查看,特定时间点 特定goroutine的执行堆栈信息以及关联的事件信息
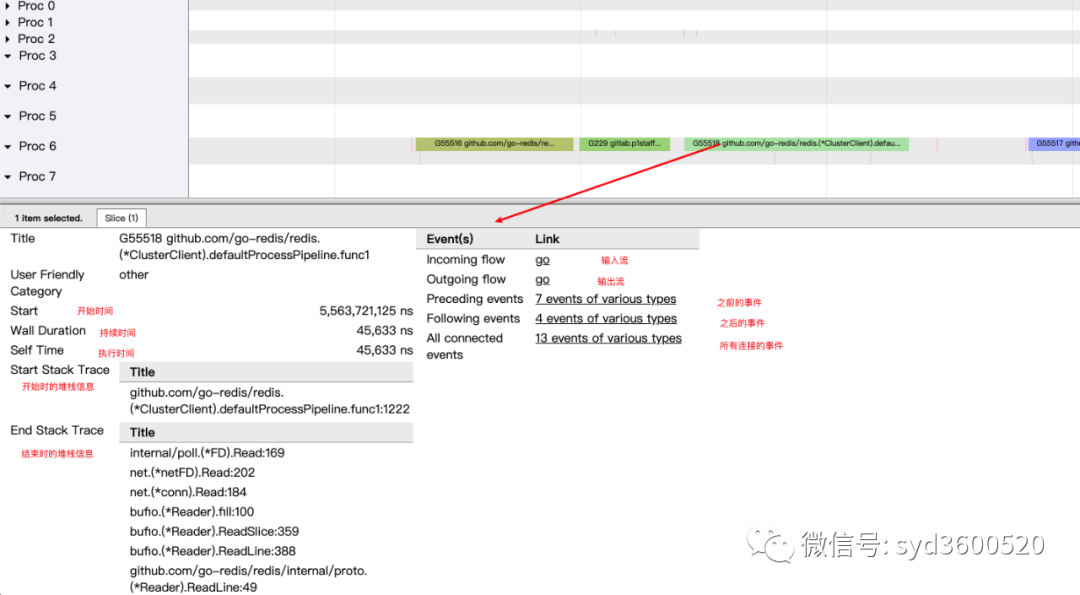
goroutine analysis

点击goroutine的id 可以跳到trace view 详细查看goroutine具体干了什么
| 名称 | 含义 |
| Execution | 执行时间 |
| Network wait | 网络等待时间 |
| Sync Block | 同步阻塞时间 |
| Blocking syscall | 系统调用阻塞时间 |
| Scheduler wait | 调度等待时间 |
| GC Sweeping | GC清扫时间 |
| GC Pause | GC暂停时间 |
实践 一个延迟问题诊断
当我们一个执行关键任务的协程从运行中被阻塞。这里可能的原因:被syscall阻塞 、阻塞在共享内存(channel/mutex etc)、阻塞在运行时(如 GC)、甚至有可能是运行时调度器不工作导致的。这种问题使用pprof很难排查,
使用trace只要我们确定了时间范围就可以在proc区域很容易找到问题的源头

上图可见,GC 的MARK阶段阻塞了主协程的运行
2.3 GC
初始所有对象都是白色
Stack scan阶段:从root出发扫描所有可达对象,标记为灰色并放入待处理队列;root包括全局指针和goroutine栈上的指针
Mark阶段:1.从待处理队列取出灰色对象,将其引用的对象标记为灰色并放入队列,自身标记为黑色 2. re-scan全局指针和栈,因为mark和用户程序并行运行,故过程1的时候可能会有新的对象分配,这时需要通过写屏障(write barrier)记录下来;re-scan再完成检查;
重复步骤Mark阶段,直到灰色对象队列为空,执行清扫工作(白色即为垃圾对象)
GC即将开始时,需要STW 做一些准备工作, 如enable write barrier
re-scan也需要STW,否则上面Mark阶段的re-scan无法终止
通过GODEBUG=gctrace=1可以开启gc日志,查看gc的结果信息
GODEBUG=gctrace=1 go run main.gogc 1 @0.001s 19%: 0.014+3.7+0.015 ms clock, 0.11+2.8/5.7/3.2+0.12 ms cpu, 5->6->6 MB, 6 MB goal, 8 Pgc 2 @0.024s 6%: 0.004+3.4+0.010 ms clock, 0.032+1.4/4.5/5.3+0.085 ms cpu, 13->14->13 MB, 14 MB goal, 8 Pgc 3 @0.093s 3%: 0.004+6.1+0.027 ms clock, 0.032+0.19/11/15+0.22 ms cpu, 24->25->22 MB, 26 MB goal, 8 Pscvg: 0 MB releasedscvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)scvg: 0 MB releasedscvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)scvg: 0 MB releasedscvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)scvg: 0 MB releasedscvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)
格式(不同版本可能会不同,具体参考 runtime 包的说明)
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
含义
gc#:GC 执行次数的编号,每次叠加。
@#s:自程序启动后到当前的具体秒数。
#%:自程序启动以来在GC中花费的时间百分比。
#+...+#:GC 的标记工作共使用的 CPU 时间占总 CPU 时间的百分比。
#->#-># MB:分别表示 GC 启动时, GC 结束时, GC 活动时的堆大小.
#MB goal:下一次触发 GC 的内存占用阈值。
#P:当前使用的处理器 P 的数量。
https://github.com/felixge/fgprof 给出了一个解决方案:
具体用法:
package mainimport(_ "net/http/pprof""github.com/felixge/fgprof")func main() {http.DefaultServeMux.Handle("/debug/fgprof", fgprof.Handler())go func() {log.Println(http.ListenAndServe(":6060", nil))}()//}git clone https://github.com/brendangregg/FlameGraphcd FlameGraphcurl -s 'localhost:6060/debug/fgprof?seconds=3' > fgprof.fold./flamegraph.pl fgprof.fold > fgprof.svg
如果遇到这种CPU消耗型和非CPU消耗型混合的情况下 可以试试排查下。
推荐阅读