
基于表征学习的行人重识别(二)
在前面的推文中,我想你已经训练好了一个行人重识别的模型,那么我们应该怎么使用这个模型呢?
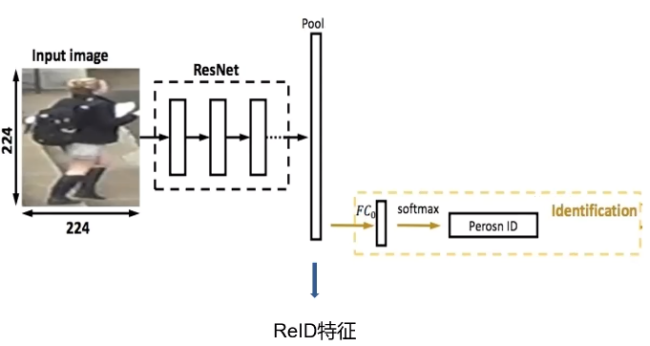
前面我们提到过,测试的时候我们会抛弃最后的输出层不用,而使用倒数第二层的全局平均池化作为输出。这是因为我们可以通过这一层输出图片的特征向量,并计算图像之间的相似度。用来判别两张图片是否是同一人。
计算图像的相似度有很多种方法,例如欧式距离,余弦距离,汉明距离等。这里我们使用的欧氏距离,欧氏距离是最常见的距离度量(用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大)。
# 欧氏距离 #
欧式距离的公式如下,当 p = 1 时,称为曼哈顿距离;当 p = 2 时,称为欧式距离;当 p = ∞ 时,称为切比雪夫距离。它是各个坐标距离的最大值。
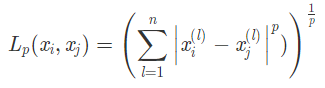
那么,在python中,我们如何计算这个欧式距离呢,在numpy中,已经帮我们实现了这个功能,我们只需要使用numpy中求范数的方法 np.linalg.norm()即可实现。
#01
特征向量提取
接下来,我们来实际操作一番,完成行人重识别的测试吧,新建一个test.py文件,首先导入依赖,然后去掉最后的FC层。完成提取特征向量的模型。
import osimport cv2import tensorflow.keras as kimport globfrom image_recognition.DarkNet.model import dreaknet53_outputimport numpy as npfrom tqdm import tqdmimport matplotlib.pyplot as pltimport matplotlib.image as imgpltinpt=k.Input((200,60,3))model=dreaknet53_output(inpt)model.load_weights('darknet_reid.h5')out=model.get_layer('global_average_pooling2d').outputmodel=k.models.Model(inpt,out)model.summary()
#02
欧式距离计算
接着,我们写入如下4个函数,分别对应的功能是,l2正则化,将特征向量的值变小;求欧氏距离;判断距离和预设值的关系;获得特征向量。
# 正则化def l2_normalize(x,axis=1,epsilon=1e-10):output=x/np.sqrt(np.maximum(np.sum(np.square(x),axis=axis,keepdims=True),epsilon))return output# 求欧式距离def person_distance(person_encodings,person_unknow):if len(person_encodings)==0:return np.empty((0))return np.linalg.norm(person_encodings-person_unknow,axis=1)# 判断距离是否小于预设值def com_person(person_list,person,tolerance=0.8):dis=person_distance(person_list,person)return list(dis <= tolerance)# 获得特征向量def get_fulters(img):img=cv2.resize(img,(60,200))img=img.reshape(-1,200,60,3)/255.p=model.predict(img)norm=l2_normalize(p).reshape([1024])return norm
#03
识别结果可视化
接着,我们可以对测试数据集进行提取,定义重识别的id进行对比,获得重识别的图片。
# 路径path=r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_test'image_paths=[os.path.join(path,p) for p in os.listdir(path)]#要进行重识别的行人idrandom_persons=['0005','0019','0023']# 存放重识别的路径img_dict={}for person in random_persons:img_paths=glob.glob(os.path.join(path,'%s_*'%person))# 随机取得一张图片img_path=np.random.choice(img_paths,1)[0]img_dict[person]=[img_path]# 获得特征向量know_img=cv2.imread(img_path)know_img_norm=get_fulters(know_img)# 在未知的图片中进行特征向量的对比for path_ in tqdm(image_paths):unknow_img=cv2.imread(path_)unknow_img_norm=get_fulters(unknow_img)out = com_person([unknow_img_norm],know_img_norm , tolerance=0.58)if out[0]:print(out,path_)img_dict[person].append(path_)# 只获取前4张重识别的图片if len(img_dict[person])>4:break
最后,我们可以通过matplotlib对重识别的结果进行可视化:
plt.figure()i = 1for key in img_dict.keys():img_paths=img_dict[key]for img_ in img_paths:img=imgplt.imread(img_)# 判断重识别是否正确if img_.split('\\')[-1].split('_')[0]!=key:img=img*[1,0,0]# 定义一个 3行5列的图plt.subplot(3,5,i)plt.imshow(img)plt.xticks([])plt.yticks([])i+=1plt.show()
程序运行结果如下,第一列的图片是我们随机选取的某个id的图片,作为我们的已知数据,后4列是进行重识别之后的结果:

#04
小结
本实验涉及到了DarkNet53、行人重识别等。DrkNet53被应用在yolov3中,是一个优秀的特征提取网络。Yolov4也在DarkNet53的基础上修改或增加了一些tricks,如SPPNet、CSPNet不仅提高了精度,还提高了速度。而行人重识别是一个比较大的领域,如果你多次运行我们的测试程序,你会发现一些有意思的情况发生:

如果我们随机取到的已知图片出现了多个人重叠的情况,后续的重识别效果并不理想,这也说明,行人检测算法的精度对行人重识别算法具有一定的影响。
#05
后续
表征学习的内容到此就结束了,运行过程序的小伙伴们应该会发现一个问题,不同人之间的特征向量距离并不是特别的大,很容易造成误识别。那么有没有一个比较好的方法能够使不同人之间的特征距离尽可能地大而同一个人之间的距离尽可能小呢?欢迎点关注接收后续推文 ,最终实现效果在本次推文中的视频可以看到哦!
,最终实现效果在本次推文中的视频可以看到哦!