走了太多弯路!
我曾经在写论文的路上,做了太多的冤枉功,走了很多弯路。科研的本质:解决问题,创造新事物(新问题、新方法、新发现、新理论)
科研论文的关键的体现在于将所得结果详实记录并进行科学分析后,总结成果写成论文由同行评议认可后发表。
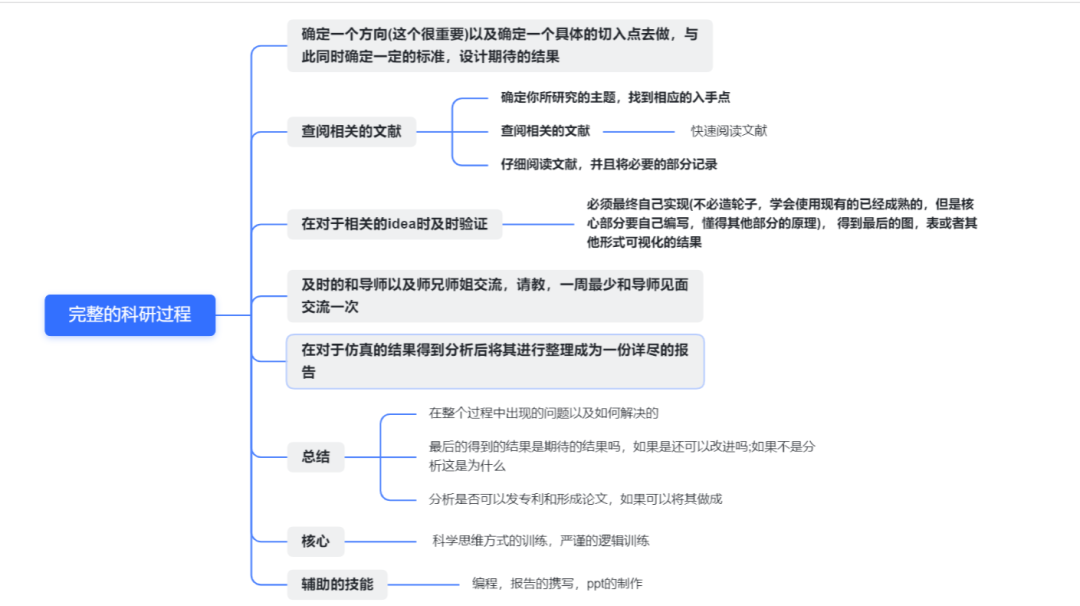
科研的完整过程
那么如何在4-6个月内产出论文呢,这次我和一些担任AAAI,ACL,EMNLP等多个会议期刊的审稿人聊了聊,给大家准备了以下攻略,希望对大家有所帮助。
扫码0.01元领取
《4-6个月产出论文实操手册》
一、如何调研确定topic
什么是好的topic,就如同寻找网易云音乐的小众歌手:
01:越直观简单越好:简单意味着自己领域知识的学习成本低,例如NLP的文本分类,CV的人脸识别
02:越小众越好:越小众,说明研究的人越少,研究竞争难度低,例如医学和CV结合的方向,NLP和生物信息(例如药物挖掘)的交叉方向
(一)如何调研确定topic
如何去寻找小而美的topic,要走金山里面找金子。
step0: 确定含金量最高的信息源
翻所在领域近三年的顶会文章,NLP领域主翻ACL/NAACL/EMNLP的顶会文章,CV主翻CVPR/ECCV/ICCV的顶会文章,机器学习主翻NIPS/ICLR/ICML,图与数据挖掘主翻KDD/WWW/SIGIR。
step1: 只看论文标题,确定10-20篇准备看摘要的论文
浏览找到顶会文章的paper title list,根据直观易懂且小众原则排序选出10-20篇论文看摘要。
step2: 看10-20篇准备看摘要的论文
找到3-5篇摘要看的懂的论文,仍然是直观易懂且小众排序原则。
step3: 精读3-5篇论文,确定研究的topic,找到一个觉得我可以的topic
精读3-5篇论文,对每篇论文所涉及的topic回答下面几个问题:
这个topic目前3-5个公认baseline以及公认的evaluation datasets是什么;
这些baseline是不是卷到特别复杂;
datasets是不是刷到特别饱和;
代码是不是自己很快可以看懂一键run起来。
扫码0.01元领取
《4-6个月产出论文实操手册》
(二)如何确定idea
空想无用,实践才能出真知。
step0:平地不好起高楼,找到好的代码
确定topic之后,搜索相关baseline的开源实现代码,评判原则readme完善,看的不吃力,跑起来容易。
step1:纸上得来终觉浅,觉知此事要躬行
确定好的开源代码实现后,对比原始论文,把对应的实验都跑一遍,看看能不能复现论文实验效果。
以及对实验的数据集多做error analysis和case study,反复实验和分析数据,洞见到提升点,能找到提升点,自然就可以产出idea。
step2: 多多讨论,寻求合作
独立科研能力虽然重要,但是对于小白更需要找到好的合作者和引路人,和相关论文代码作者多发邮件讨论问题,甚至可以邀约合作。
也可以多找靠谱的师兄姐同学讨论,一个人干很容易迷茫。
在讨论和合作中,可以更加明确idea,当然记住idea也要谨慎透露,防止idea被剽窃。
扫码0.01元领取
《4-6个月产出论文实操手册》
二、如何多快好省做实验
工程思维,快速迭代。
step0:0-1 阶段,快速验证想法
万事开头难,确定idea之后,要快速实现idea验证想法没有问题,如果没有问题,自然一顺百顺。
如果有问题,解决方法如下:
首先,最小迭代原则,自己的idea最好是在基础代码上的逐步迭代,确保实验不顺需要分析考虑的对象最少化。
其次,勇于跳坑,如果某次的实现发现经过一段时间努力后没有效果并且分析不出,及时跳坑,考虑换一个代码baseline实现,甚至要重新review讨论idea。
step1: 1-10阶段,完整solid的实验方案
实验越全面翔实,论文中稿概率越大,一个统计数据method+实验部分接近论文页数限制,基本可以中稿。
开了好头,接下来是最见逻辑和思考的阶段,初步想法验证后,需要扩展实验和分析。
如何扩展实验,借鉴baseline对应论文的实验setting,确定自己要做哪些ablation study实验以及补充哪些数据集的实验;
如何进行分析,分析最关键的是要解释出自己的实验效果如何好,一般针对自己argue的几个点,给出定量的曲线统计实验或者定性的case study实验。
扫码0.01元领取
《4-6个月产出论文实操手册》
三、如何翻过论文写作的山
先写再改,尽量降低自己的学习曲线和执行难度。
Tips:这份操作手册的核心就是以平滑的学习曲线完成自己的第一篇论文,一回生二回熟,一回生很重要。
step0: 模仿式写作
模仿实验中对比baseline的几篇文章组织和写作,优先把intro method和experiments部分写完,这一步先把内容都堆砌上再说。
step1: 梳理逻辑,讨论修改,明晰文章思路和逻辑
多寻求外部帮助,找到毕竟senior的人帮你看几遍文章,找到你文章中的明显的行文和逻辑问题;
找不到senior的人看,也可以找同等水平甚至门外汉看,这里就是跟着他们读带他们理解你的意思,这个过程中,自己同步可以发现自己的逻辑漏洞;
实在没人看,那就是自己化身reviewr反复challenge自己。
总结,这一步的修改,是找到反馈,迭代修改几轮,让自己文章的主线和思路清晰起来
step2: 格式调整,语言润色
内容基础框架和思路确定之后,就是文章的美化了。
首先是格式,严格按照所投会议或者期刊的要求调整好自己论文的格式;
然后语言,这里推荐quillbot,开会员直接可以帮你改写到地道。
最后是图表,图表多学习其他顶会文章的图表范式,美化好自己的图表,尤其是图,一图胜千言
扫码0.01元领取
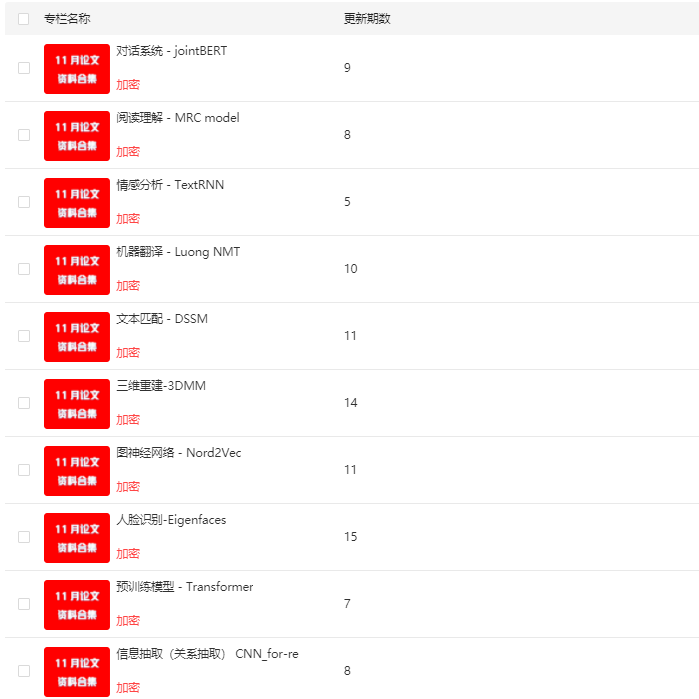
180篇AI论文讲解课
以下是论文写作干货详细大纲
《180+条AI论文讲解课》
CV篇
CV baseline —— Alexnet
1. 图像分割 —— FCN
2. 目标检测 —— YOLO V3
3. GAN —— 原生GAN
4. OCR —— CRNN
5. 轻量化网络 —— MobileNets
6. CV-transformer——VIT
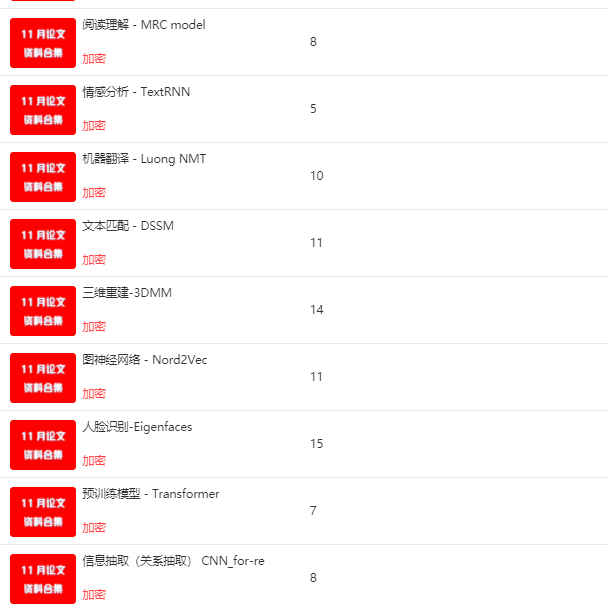
7. 人脸识别——Eigenfaces
8. 三维重建 —— Alexnet
NLP篇
NLP baseline —— Word2Vec
1. 信息抽取(命名实体识别) —— LSTM
2. 信息抽取(关系抽取) —— CNN_for-re
3. 预训练模型 —— Transformer
4. 图神经网络 —— Nord2Vec
5. 文本匹配 —— DSSM
6. 机器翻译 —— Luong NMT
7. 情感分析 —— TextRNN
8. 阅读理解 —— MRC model
9. 对话系统 —— jointBERT
10. 强化学习 —— DQN