
年轻人不讲武德,乱用索引,你到底走了多少弯路?
前言
继上一篇《explain | 索引优化的这把绝世好剑,你真的会用吗?》之后,本篇是索引相关的第2篇文章。上一篇重点介绍的是使用explain执行计划查看索引执行情况,以便于快速定位哪张表有索引使用问题。
本篇主要介绍的是索引失效的常见原因和如何用好索引,跟上一篇正好承上启下,给有需要的朋友一个参考。
本文将从以下几个方便进行讲解:
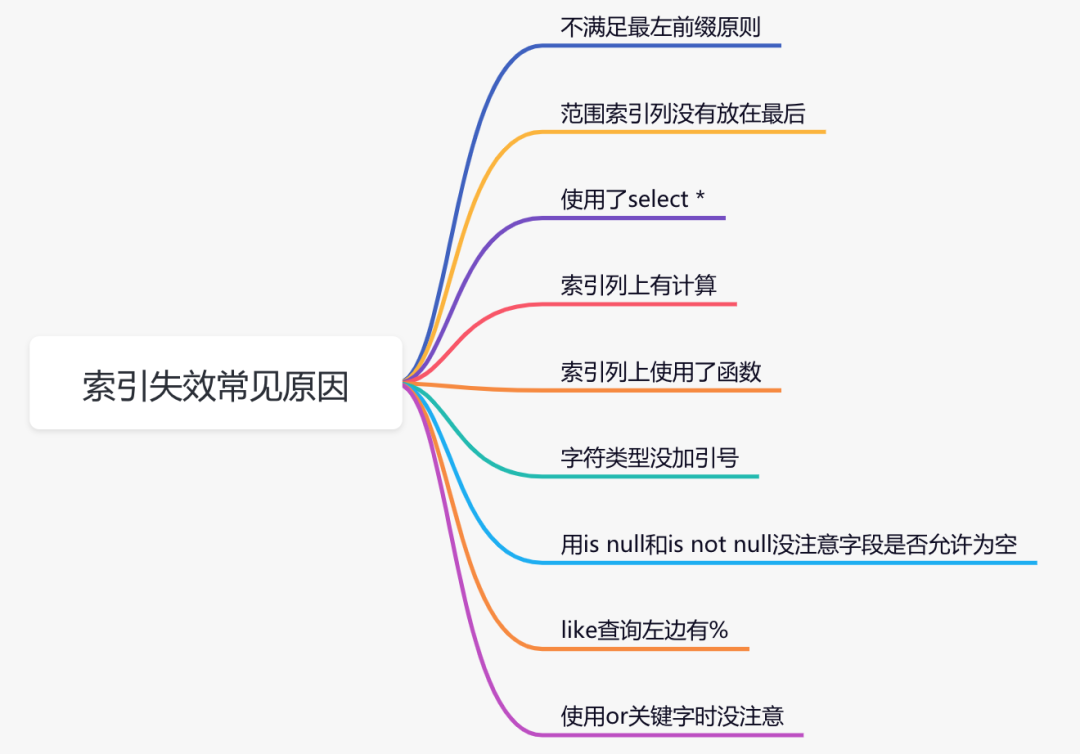
1.索引失效常见原因:
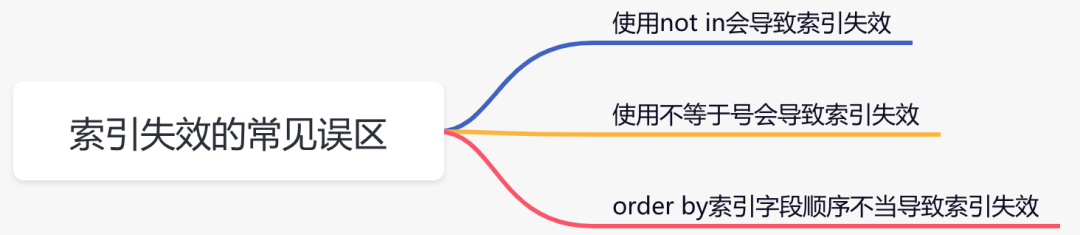
2.索引失效常见误区:
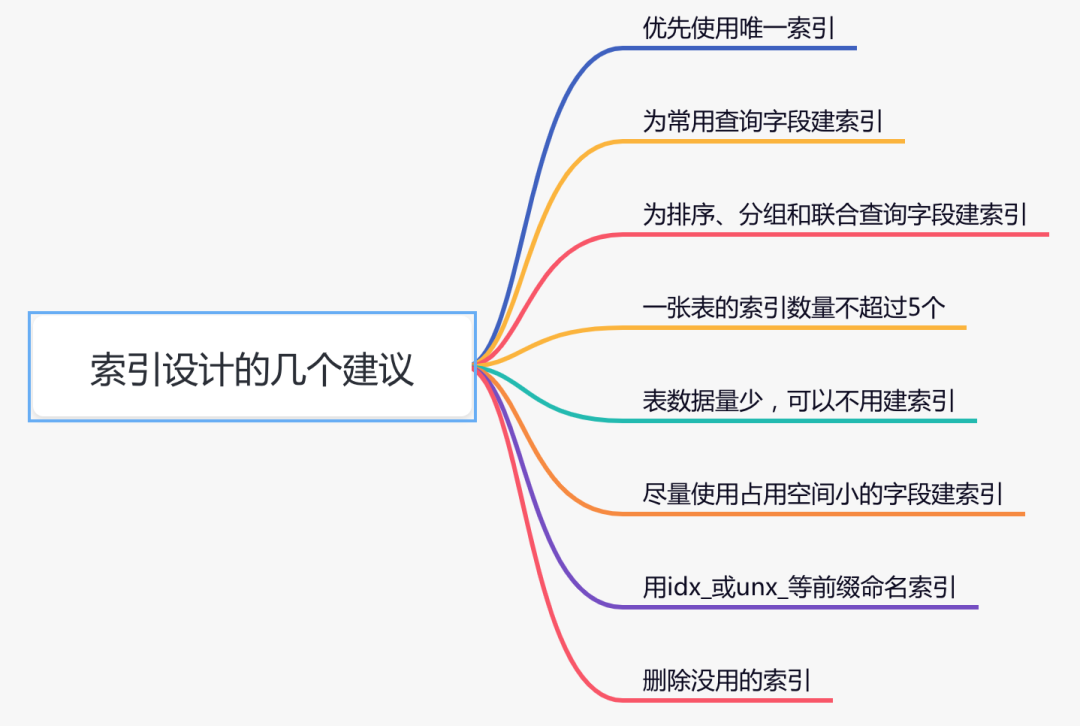
3.索引设计的几个建议:
准备工作
查看当前mysql的版本:
select VERSION();
查出当前版本为:8.0.21
创建一张表test1
CREATE TABLE `test1` (
`id` bigint NOT NULL,
`code` varchar(30) NOT NULL,
`age` int NOT NULL,
`name` varchar(30) NOT NULL,
`height` int NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_code_age_name` (`code`,`age`,`name`) USING BTREE,
KEY `idx_height` (`height`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
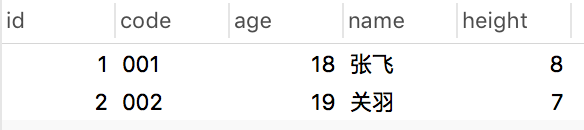
插入两条数据:
INSERT INTO `test1`(`id`, `code`, `name`, `age`,`address`) VALUES (1, '001', '张飞', 18,'7');
INSERT INTO `test1`(`id`, `code`, `name`, `age`,`address`) VALUES (2, '002', '关羽', 19,'8');
查询一下:
select * from test1;
结果:
此外建立了两个索引:idx_code_age_name(code, age, name)联合索引 和 idx_height(height)普通索引。

一. 索引失效常见原因
1.不满足最左前缀原则
第1种情况:
where条件后的字段包含了联合索引的所有索引字段,并且顺序是按照:code、age、name。
执行sql如下:
explain select * from test1
where code='001' and age=18 and name='张飞' ;
结果:

从图中标红的地方可以看出已经走了联合索引idx_code_name_age,并且索引的长度是188, 188 = 30 * 3 + 2 + 30 * 3 + 2 + 4,索引是使用充分的,索引使用效率最佳。
有些朋友可能会问:索引长度为什么是这样计算的?
答:请参考《explain | 索引优化的这把绝世好剑,你真的会用吗?》,里面给出了非常详细的讲解。
第2种情况:
where条件后的字段包含了联合索引的所有索引字段,顺序是不按照:code、age、name。
执行sql如下:
explain select * from test1
where code='001' and name='张飞' and age=18;
结果:

从上图中看出执行结果跟第一种情况一样。
★注意:这种情况比较特殊,在查询之前mysql会自动优化顺序。
”
第3种情况:
where条件后的字段包含了联合索引中的:code字段
执行sql如下:
explain select * from test1
where code='001';
结果:
从上图看出也走了索引,但是索引长度有所变化,现在变成了92,92 = 30*3 + 2,只用到了一个索引字段code,索引使用不充分。
第4种情况:
where条件后的字段包含了联合索引中的:age字段
执行sql如下:
explain select * from test1
where age=18;
结果:
从上图中看变成了全表扫描,所有的索引都失效了。
第5种情况:
where条件后的字段包含了联合索引中的:name字段
执行sql如下:
explain select * from test1
where name='张飞';
结果:从上图中看变成了全表扫描,所有的索引都失效了。
第6种情况:
where条件后的字段包含了联合索引中的:code和age字段
执行sql如下:
explain select * from test1
where code='001' and age=18;
结果:

从上图中看出还是走了索引,但是索引长度变成了:96,96 = 30*3 + 2 + 4,只用到了两个索引字段code和age,索引使用也不充分。
第7种情况:
where条件后的字段包含了联合索引中的:code和name字段
执行sql如下:
explain select * from test1
where code='001' and name='张飞';
结果:

从上图中看出走的索引长度跟第1种情况一样,长度也是92。也就是说只用到了一个索引字段code,而age字段的索引失效了。
第8种情况:
where条件后的字段包含了联合索引中的:age和name字段
执行sql如下:
explain select * from test1
where age=18 and name='张飞';
结果:

从上图中看出变成了全表扫描,所有的索引都失效了。
小结:
满足最左前缀的场景: code,code、age,code、age、name。包含: code、age、name全索引字段的情况比较特殊,这三个字段作为查询条件的任意一种排序都OK,最终mysql会优化成最左前缀的顺序。如果中间出现断层,如: code、name,只会走第一个索引code,从断层后的索引都会失效。其他的场景: age,name,age,name索引都会失效。
2.范围索引列没有放在最后
where条件后的字段age用了大于等于,具体sql如下:
EXPLAIN select * from test1
where code='001' and age>18 and name='张飞' ;
结果:
从上图中看出索引长度变成:96,96 = 30*3 + 2 + 4,只用到了两个索引字段code和age,而name字段的索引失效了。
如果范围查询的语句放到最后:
EXPLAIN select * from test1
where code='001' and name='张飞' and age>18 ;
结果:

什么鬼?怎么索引长度还是:96?
这是一个非常经典的错误
范围查询放最后是指创建联合索引的字段顺序,现在的顺序是:

调整一下把索引字段name和age的顺序调整一下:

再执行上面的sql,结果:

从上图中看出索引长度变成:188,索引使用充分了。
回过头再执行刚开始的那条sql:
EXPLAIN select * from test1
where code='001' and age>18 and name='张飞';
结果:

什么?
索引长度也是:188。
★注意:范围查询放最后,指的是联合索引中的范围列放在最后,不是指where条件中的范围列放最后。如果联合索引中的范围列放在最后了,即使where条件中的范围列没放最后也能正常走到索引。
”
3.使用了select *
其实在《阿里巴巴开发手册》中也明确说了,禁止使用select * ,这是为什么呢?
EXPLAIN select * from test1
结果:

从上图中看出走了全表扫描。
那么如果查询的是索引列:
EXPLAIN select code,age,name from test1
结果:

从图中可以看出这种情况走了全索引扫描,比全表扫描效率更高。
其实这里用到了:覆盖索引。
如果select的列都是索引列,则被称为覆盖索引。
如果select的列不只包含索引列,则需要回表,即回到表中再查询出其他列,效率相当更低一些。select * 大概率需要查询非索引列,需要回表,因此要少用。
当然,本文中很多示例都使用了select * ,主要是我表中只有两条数据,为了方便演示,正常业务代码中是要杜绝这种写法的。
4.索引列上有计算
执行sql如下:
explain select * from test1
where height+1 =7;
结果: 从上图中可以看出变成全表扫描了,由此可见在索引列上有计算,索引会失效。
从上图中可以看出变成全表扫描了,由此可见在索引列上有计算,索引会失效。
5.索引列上使用了函数
如果在索引列加某个函数,具体sql如下:
explain select * from test1
where SUBSTR(height,1,1)=8;
结果:从上图中可以看出变成全表扫描了,由此可见在索引列上加了函数,索引也会失效。
6.字符类型没加引号
废话不多说直接上sql:
explain select * from test1
where name = 123;
结果:
从图中看出走的全表扫描,索引失效了。
为什么索引会失效呢?
这里有些朋友可能会有点懵。
答:name字段是字符类型,而等于号右边的是数字类型,类型不匹配导致索引丢失。
所以在使用字符类型字段做判断时,一定要加上单引号。
★类型不匹配导致索引丢失问题,是我们平时工作中非常容易忽视的问题,一定要引起足够的重视
”
7.用is null和is not null没注意字段是否允许为空
前面创建的test1表中height字段是非空的。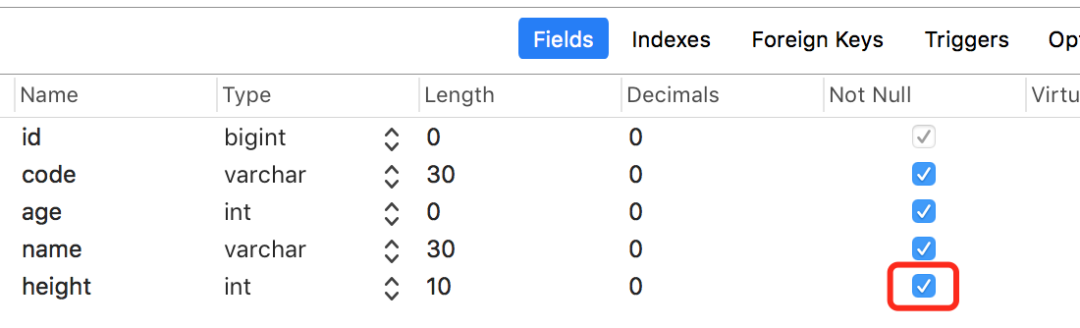
查询sql如下:
explain select * from test1
where height is null;
explain select * from test1
where height is not null;
结果都是:从上图中看出都是全表扫描,索引都失效了。
如果height字段改成允许为空的呢?
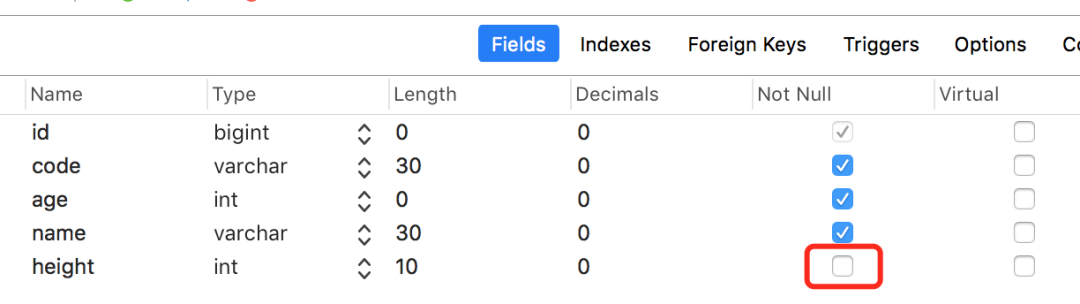
上面第一条sql执行结果:

从上图中看出走了ref类型的索引。
上面第二条sql执行结果:

从上图中看出走了range类型的索引。
小结
如果字段不允许为空,则is null 和 is not null这两种情况索引都会失效。 如果字段允许为空,则is null走 ref类型的索引,而is not null走range类型的索引。
8.like查询左边有%
like查询主要有三种情况:
like '%a' like 'a%' like '%a%'
先看看第一种情况:
explain select * from test1
where code like '%001';
结果:

从上图看出走的全表扫描,索引失效了。
再看看第二种情况:
explain select * from test1
where code like '001%';
结果:
从上图看出走的range类型的索引。
最后看看第三种情况:
explain select * from test1
where code like '%001%';
结果:从上图看出走的全表扫描,索引也失效了。
从这三种结果看出like语句只有%在右边才能走索引。
如果有些场景就是要使用like语句%在左边该怎么办呢?
答案:使用覆盖索引
具体sql如下:
explain select code,age,name from test1
where code like '%001%';
结果:

从上图看出走的index类型的全索引扫描,相对于全表扫描性能更好。
当然,最佳实践是在sql中要避免like语句%在左边的情况,如果有这种业务场景可以使用es代替mysql存储数据。
小结:
like '%a' 索引失效 like 'a%' 走range类型索引 like '%a%' 索引失效
9.使用or关键字时没有注意
用法如下:explain select * from test1
where height = 8 or height = 9;
结果:

从上图中看出走了range类型的索引,不是没问题吗?
再把sql改一下:
explain select * from test1
where code = '001' or height = 8;
结果:
从上图中可以看出变成了全表扫描,索引失效了。
我们不妨单独查询一下:
explain select * from test1
where code = '001';
结果:
和
explain select * from test1
where height = 8;
结果:
 两种单独查询的情况都走了
两种单独查询的情况都走了ref类型的索引,但是使用or关键字后sql的索引会失效。
那么,我们在想使用or的场景,又想让索引有效,该怎么办呢?
explain (select * from test1 where code = '001')
union (select * from test1 where height = 8);
没错,使用union关键字,但是跟or关键字的语法稍微有点区别,不过查询的数据结果是一样的。
上面sql执行结果如下:
我们看到走了ref类型索引。
★or关键字会让索引失效,可以用union代替
”
二. 索引失效的常见误区
1.使用not in会导致索引失效
用法如下:
explain select * from test1
where height not in (7,8);
结果:

从上图中看出是走了range类型索引的,并没失效。
★需要特别说明的是mysql5.7和5.8不同的版本效果不一样,5.7中这种情况sql执行结果是全表扫描,而5.8中使用了
”range类型索引。
2.使用不等于号会导致索引失效
用法如下:
explain select * from test1
where height!=8;
结果:

从图中看出走了range类型的索引。
★需要特别说明的是mysql5.7和5.8不同的版本效果不一样,5.7中这种情况sql执行结果是全表扫描,而5.8中使用了
”range类型索引。5.7中如果想使用索引该怎么办呢?答案:使用大于和小于代替不等于。
在这里温馨的提醒一声,不等于号不只是 != ,还包括 <>。
3.order by索引字段顺序不当导致索引失效
sql中除了where后面的字段能走索引之外,order by后面的字段也能走索引。
EXPLAIN select * from test1
where code='001' order by age,name;
结果:

从上图中看出走了ref类型的索引,索引长度是92,并且没有额外信息。
但是如果把order by 后面的条件改成如下两种排序:
EXPLAIN select * from test1
where code='001' order by name;
EXPLAIN select * from test1
where code='001' order by name,age;
结果:

从上图中看出还是走了ref类型的索引,索引长度是92,但是额外信息中提示:Using filesort,即按文件重排序。
上面两个例子能够看出有没有使用索引跟where后面的条件有关,而跟order by 后面的字段没关系。
而需不需要按文件重排序,则跟order by 后面的字段有直接关系。
问题来了,额外信息中提示:Using filesort这种该如何优化?
答:这种情况一般是联合索引中索引字段的顺序,跟sql中where条件及order by 不一致导致的,只要顺序调整一致就不会出现这个问题。
三. 索引设计的几个建议:
优先使用唯一索引,能够快速定位 为常用查询字段建索引 为排序、分组和联合查询字段建索引 一张表的索引数量不超过5个 表数据量少,可以不用建索引 尽量使用占用空间小的字段建索引 用idx_或unx_等前缀命名索引,方面查找 删除没用的索引,因为它会占一定空间
四. 彩蛋:
特别说明:索引失效除了上述的常见问题之外,mysql通过索引扫描的行记录数超过全表的10%~30%左右,优化器也可能不会走索引,自动变成全表扫描。
送给大家一个避坑口诀:
全职匹配我最爱,最左前缀要遵守 带头大哥不能死,中间兄弟不能断 索引列上少计算,范围列后全失效 like百分写最右,覆盖索引不写* 不等空值还有or,索引影响要注意; 字符字段引号不能丢,sql优化有诀窍。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
在公众号中回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。
参考:https://blog.csdn.net/sggtgfs/article/details/94439305
推荐阅读:
zuul如果两个filter的order一样,是如何排序的?