
这个项目厉害了,横跨六十余年的中文历时语料库
【公众号回复 “1024”,免费领取程序员赚钱实操经验】

大家好,我是章鱼猫。
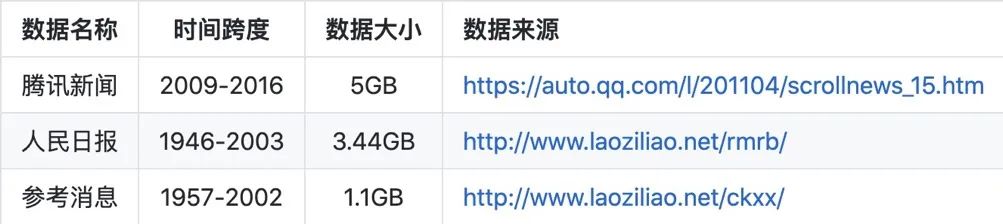
今天推荐的这个项目是「ChineseDiachronicCorpus」,中文历时语料库,横跨六十余年,包括腾讯历时新闻 2009 - 2016,人民日报历时语料 1946 - 2003,参考消息历时语料 1957 - 2002。
基于历时流通语料库,可用于历时语言变化计算、语言监测、社会文化变迁研究提供基础性的语料支持。
项目的由来
语言是人类重要的交际工具,同时也是社会的镜子,语言记录并反映了社会,对语言记录进行挖掘、计算,可以从各个层面对社会进行解读。
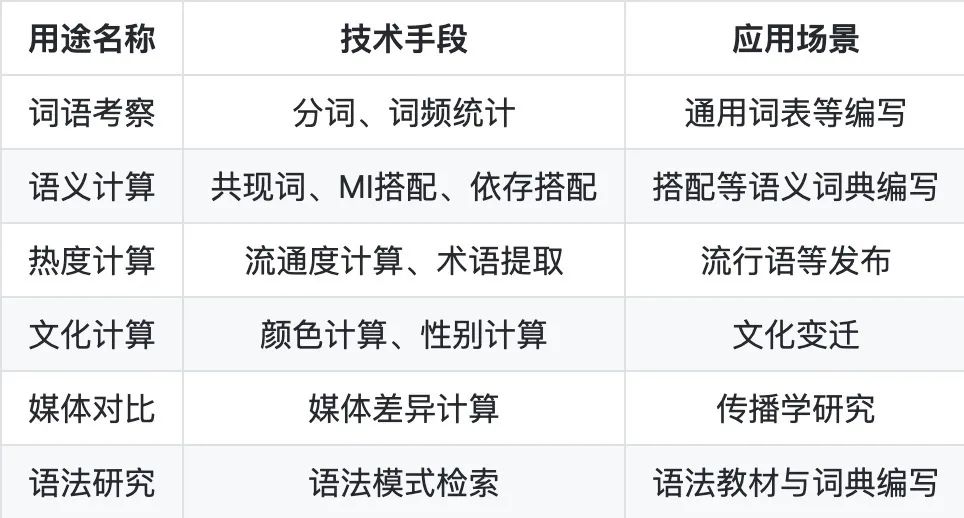
例如,基于语料库进行词语考察,以反映单个词语在不同时间周期中的使用及变动情况。以语料为载体,挖掘出属于某个特定时间周期的社会特点,例如年度关键词、年度人物、年度流行语;对词语进行文化计算,如颜色计算、性别计算、观点计算等,以考察整个社会对某一事物、看法的演变。
当前,开源可用的中文历时语料库较少。代表性的有北京语言大学国家语言资源监测与研究平面媒体中心 DCC 动态流通语料库,其对国内数十家报纸媒体进行监测,也有中国传媒大学网络媒体中心的历时语料库可以使用。
随着网络技术的发展以及采集技术的相对成熟,构建起历时语料库变得越来越容易,这就使得向外界共享历时语料库变得更为便利且必要。
本项目,旨在通过公开收集的方式,从网络媒体和平面媒体两个角度出发,形成腾讯新闻、人民日报、参考消息三大历时语料库,以供社会开放使用。
项目的用途
基于这个语料库,能够做什么呢?总结了下,至少可以从词语考察、语义计算、热度计算、文化计算、媒体对比、语法研究等六个方面开展工作。
项目的获取
对于如何获取数据,下表是对数据集的介绍,需要使用的可以开放下载使用,因涉及版权问题,暂只放数据来源。
开源项目地址:https://github.com/liuhuanyong/ChineseDiachronicCorpus
开源项目作者:刘焕勇
推荐阅读:
---特别推荐---
特别推荐:一个新的优质的专注分享各种浏览器插件、黑科技教程、各种你想不到的高效率软件及工具的公众号,「黑科技指北」,非常值得大家关注。