
什么是数据湖,什么是湖仓一体呢?
关注我👆👆👆,持续学习
大概从2021年数据湖这个概念开始火了起来,我们今天来聊聊为什么需要用数据湖。

转山转水转佛塔 只为途中与你相见班公湖
16年骑行新藏阿里北线 摄
前言
首先思考几个问题
班公湖里的水是怎么来的?
冰川融水形成小溪,溪水从山间倾泻而下,汇聚成一片宁静的湖面。
企业的数据也是一样,我们不希望各个组织的数据分散到不同地方,而是集中储存和管理。
为什么叫数据湖,不叫数据河,数据池,或者数据海?
数据要能存,而不是一江春水向东流。
要足够大,大数据太大,一池存不下。
企业的数据要有边界,可以流通和交换,但更注重隐私和安全,“海到无边天作岸”,可不行。
数据库,数据仓库,数据湖,湖仓一体,数据中台,这些概念你是否混淆?
(1)数据库 提供数据的存储和查询。
(2)数据仓库 是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策和信息的全局共享。
(3)数据湖 是一个以原始格式存储数据的存储库或系统,它按原样存储数据,而无需事先对数据进行结构化处理。一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频)。
(4)湖仓一体 数据仓库和数据湖的数据和元数据打通和自由流动,湖里的数据可以流到仓里,可以直接被使用;而仓里的数据也可以留到湖里,低成本的长久保存,供未来使用。
(5)数据中台 避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用。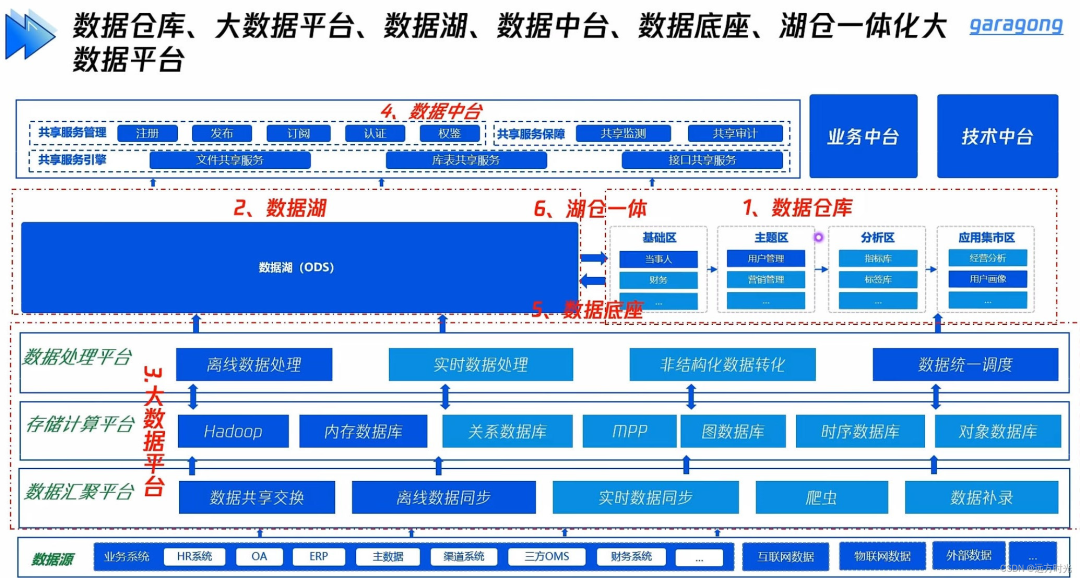
零、企业的数据困扰
困扰一:互联网的兴起和数据孤岛
随着互联网的兴起,企业内客户数据大量涌现。为了存储这些数据,单个数据库已不再足够,公司通常会建立多个按业务部门组织的数据库来保存数据。随着数据量的增长,公司通常可能会构建数十个独立运行的业务数据库,这些数据库具有不同的业务和用途。
一方面,这是一种福气:有了更多,更好的数据,公司能够比以往更精确地定位客户并管理其运营。
另一方面,这导致了数据孤岛:整个组织中数据分散到各个地方 由于无法集中存储和利用这些数据,公司对于数据的利用效率并不高。这样的痛苦让公司逐步走向数仓的利用模式。
困扰二:非结构化数据
随着数据仓库的兴起,人们发现,数据孤岛的问题貌似被数仓解决了。我们通过ETL、数据管道等程序,从各个数据孤岛中抽取数据注入数仓中等待进行维度分析。看起来有一种数据集中存储的样子。但是随着互联网的加速发展,数据也产生了爆发性的增长,数仓就表现出来了一点力不从心:
数据增长的太快,而由于数据建模的严格性,每开发一次数仓的新应用,流程就很长。无法适应新时代对于数据快速分析、快速处理的要求
随着数据行业和大数据处理技术的发展,原本被遗忘在角落中的一些价值密度低的非结构化数据便慢慢了有了其价值所在,对于这些大量的非结构化数据(日志、记录、报告等)的分析也逐步提上日程
但是,数仓并不适合去分析非结构化的数据,因为数仓的严谨性,其只适合处理结构化的数据。那么,对于非结构化数据的处理数仓就不太适合。
困扰三:保留原始数据
在以前,由于大规模存储的成本和复杂性以及大数据技术尚未开始蓬勃发展等客观原因,造成企业对于数据的存储是精简的。也就是,能够存入到企业系统中的数据都是经过处理提炼的,这些数据撇除了价值密度低的信息,只保留了和业务高度相关的核心内容。
这样可以有效的减少企业的数据容量,也就减少了存储的成本、以及管理维护的复杂度。但这样做是有一定的缺点的,那就是企业并不保留原始数据(或者说保留部分),一旦出现数据错误或者其它问题,想要从原始的数据中进行溯源就难以完成了。
并且,业务并不是一成不变的,当初因为业务被精简掉的内容,可能对未来的业务有所帮助。所以,无法大量的长期保存原始数据也是企业的困扰之一
- 数据孤岛
- 非结构化数据分析
- 想要海量的保存原始数据
基于这3个最主要的困扰,企业迫切希望能够做到:
- 数据的集中存储(解决数据孤岛),并且成本可控,使用维护简单
- 可以存储任意格式的数据(结构化的、非结构化的、半结构化的)
- 能够支持大多数分析框架
那么,数据湖的概念也就因这三种需求被逐步的提出并走向人们的视野中。
一、数据湖概念
- 能够存储海量的原始数据
- 能够支持任意的数据格式
- 有较好的数据分析和处理能力
 image.png
image.png二、数仓和数据湖的对比
 image.png
image.png三、数据湖的优势
-
轻松的收集数据(读时模式):数据湖与数据仓库的一大区别就是,Schema On Read,即在使用数据时才需要Schema信息;而数据仓库是Schema On Write,即在存储数据时就需要设计好Schema。这样,由于对数据写入没有限制,数据湖可以更容易的收集数据。
-
不需要关心数据结构:存储数据无限制,任意格式数据均可存储,只要你能分析就能存。
-
全部数据都是共享的(集中存储),多个业务单元或者研究人员可以使用全部的数据,以前由于一些数据分布于不同的系统上,聚合汇总数据是很麻烦的。
-
从数据中发掘更多价值(分析能力):数据仓库和数据市场由于只使用数据中的部分属性,所以只能回答一些事先定义好的问题;而数据湖存储所有最原始、最细节的数据,所以可以回答更多的问题。并且数据湖允许组织中的各种角色通过自助分析工具(MR、Spark、SparkSQL等),对数据进行分析,以及利用AI、机器学习的技术,从数据中发掘更多的价值。
-
具有更好的扩展性和敏捷性:数据湖可以利用分布式文件系统来存储数据,因此具有很高的扩展能力。开源技术的使用还降低了存储成本。数据湖的结构没那么严格,因此天生具有更高的灵活性,从而提高了敏捷性。
四、数据湖Data Lake三剑客:Delta、Hudi、Iceberg
哪些重要的公有云厂商在使用数据湖。
- DeltaLake: 微软云,亚马逊云,阿里云
- Hudi: 华为云
- Iceberg: 腾讯云
五、Delta Lake - 数据湖核心的增强
我工作中主要使用的微软云,所以主要讲DeltaLake。
Delta Lake是由Spark的商业化公司,也就是大名鼎鼎的砖厂:Databricks所推出并开源的一款基于HDFS的存储层框架,并将ACID事务引入到了Spark以及大数据工作负载中,通过Spark作为媒介来实现存储层面的增强。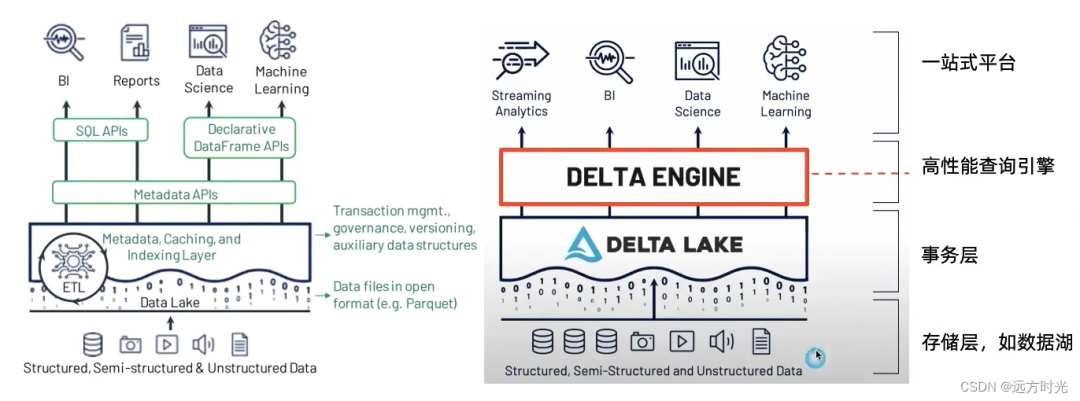
六、Delta Lake 有什么特性
(1)ACID 事务控制:数据湖通常具有多个同时读取和写入数据的数据管道,并且由于缺乏事务,数据工程师必须经过繁琐的过程才能确保数据完整性。Delta Lake将ACID事务带入您的数据湖。它提供了可序列化性,最强的隔离级别。
(2)可伸缩的元数据处理:在大数据中,甚至元数据本身也可以是“大数据”。Delta Lake将元数据像数据一样对待,利用Spark的分布式处理能力来处理其所有元数据。这样,Delta Lake可以轻松处理具有数十亿个分区和文件的PB级表。
(3)数据版本控制:Delta Lake提供了数据快照,使开发人员可以访问和还原到较早版本的数据以进行审核,回滚或重现实验。
(4)开放的数据格式:Delta Lake中的所有数据均以Apache Parquet格式存储,从而使Delta Lake能够利用Parquet固有的高效压缩和编码方案。
(5)统一的批处理和流处理的source 和 sink:Delta Lake中的表既是批处理表,又是流计算的source 和 sink。流数据提取,批处理历史回填和交互式查询都可以直接使用它。
(6)Schema执行:Delta Lake提供了指定和执行模式的功能。这有助于确保数据类型正确并且存在必需的列,从而防止不良数据导致数据损坏。
(7)Schema演化:大数据在不断变化。Delta Lake使您可以更改可自动应用的表模式,而无需繁琐的DDL。
(8)审核历史记录:Delta Lake事务日志记录有关数据所做的每项更改的详细信息,从而提供对更改的完整审核跟踪。
(9)更新和删除:Delta Lake支持Scala / Java / Python API进行合并,更新和删除数据集。
(10)100%和Apache Spark的API兼容:开发人员可以将Delta Lake与现有的数据管道一起使用,而无需进行任何更改,因为它与常用的大数据处理引擎Spark完全兼容。
七、Delta Lake 重点特性解读
中间数据
首先先来理解一下中间数据这个概念:数据湖内的原始数据,直接利用在业务分析上是比较困难的。一个主要原因就是,我们在构建数据湖的时候,汇入的数据是基于数据湖的指导原则的:数据和业务分离也就是说,这些数据是其最原始的样子,并不贴合业务分析的需求。
一般情况下,企业都会对原始数据进行一次、二次、乃至多次的迭代处理,将这些数据分阶段、分步骤的逐步处理成业务想要的样子,这样就更适合做业务分析。
那么,这些迭代处理所产生的一系列数据文件,我们称之为中间数据。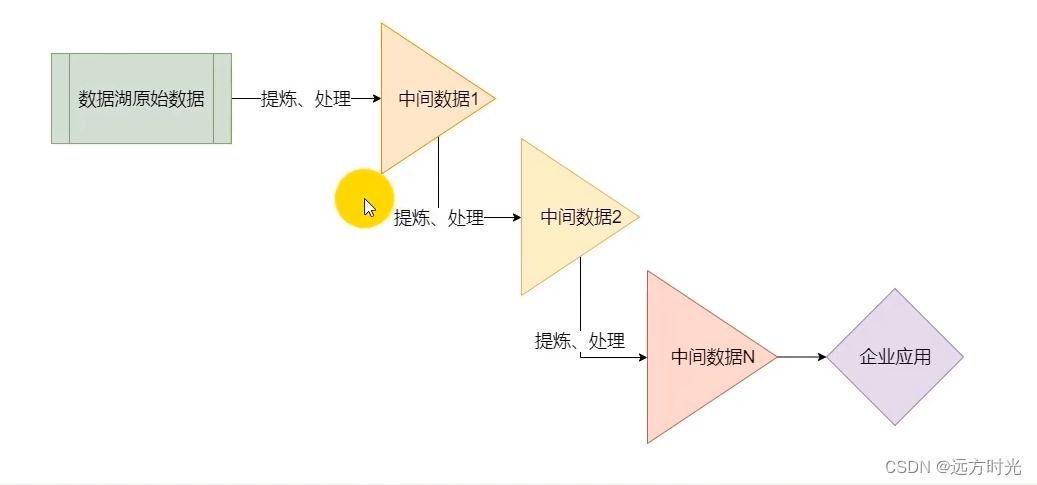 PS: 其实这种分析模式,就是Lambda架构中对于批(离线数据)的处理方式。
PS: 其实这种分析模式,就是Lambda架构中对于批(离线数据)的处理方式。
中间数据也就是Lambda架构中的Batch View。
ACID 事务控制
在基于中间数据这种处理模式下,Hadoop、Spark生态构建数据湖的一个不足之处就在于:在数据处理的过程中,没有事务控制。
原因1:在数据转换的过程中,如果出现问题,造成了数据处理的不完整,这就会导致基于此数据的后续操作均产生了偏差。
而修复这些偏差,就需要耗费工程师很大的精力,特别在数据量大的时候。
原因2:生成的中间数据,并不只会有一个人在用,如果多个人对同一个中间数据进行了修改、更新操作,就会产生冲突而这种冲突,也会造成数据迭代链条的断裂。
Delta Lake实现了事务日志的记录,对于数据的任何操作都记录在事务日志里面,同时也基于事务日志,实现了ACID的事务控制。
ACID级别的事务控制,可以有效的帮助工程师控制中间数据迭代的过程,并避免冲突。
数据版本控制
同样,对于一份中间数据,可能被我们折腾了多次版本更新后发现,最初的样子才是最好的样子。但是,中间数据已经被我们修改的面目全非了怎么办?这就是Hadoop Spark生态构建数据湖的第二个不足之处:没有数据版本控制Delta Lake带来了这个特性,可以让我们随时随地的回退到数据在任何时间点之上的版本。
注意,是任意版本。也就是说,从这个数据被创建,到最新的状态,这中间任何时间点的版本均可回退。这就给工程师们倒腾数据提供了一个强有力的支撑:再也不怕折腾废了。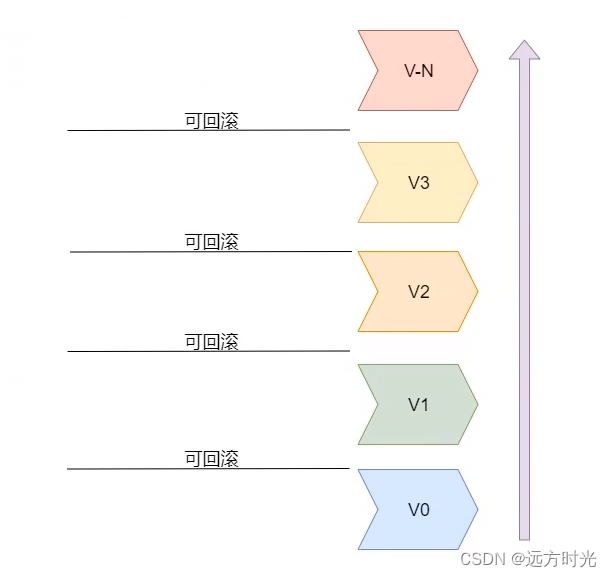 所以,数据版本控制,对于构建数据湖生态体系同样重要。
所以,数据版本控制,对于构建数据湖生态体系同样重要。
可伸缩的元数据处理
Delta Lake可以帮助我们控制事务,以及进行任意时间点的数据回滚操作。那么,如果某些中间数据经过了超多次的版本更新,并且其数据内容非常巨大。对于这样的情况,如何做到任意时间点的回滚呢?
这就是Delta Lake的另一个强大之处:强大的元数据处理能力,在Delta Lake的设计中,元数据(数据的事务日志)也是当成一种普通的数据对待。对于元数据的处理,当成一种普通的Spark任务去做,应用Spark强大的分布式并行计算能力,可以完成对超大规模的数据的管理和溯源。
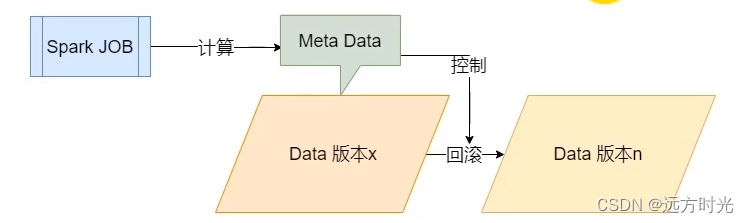
审核历史记录
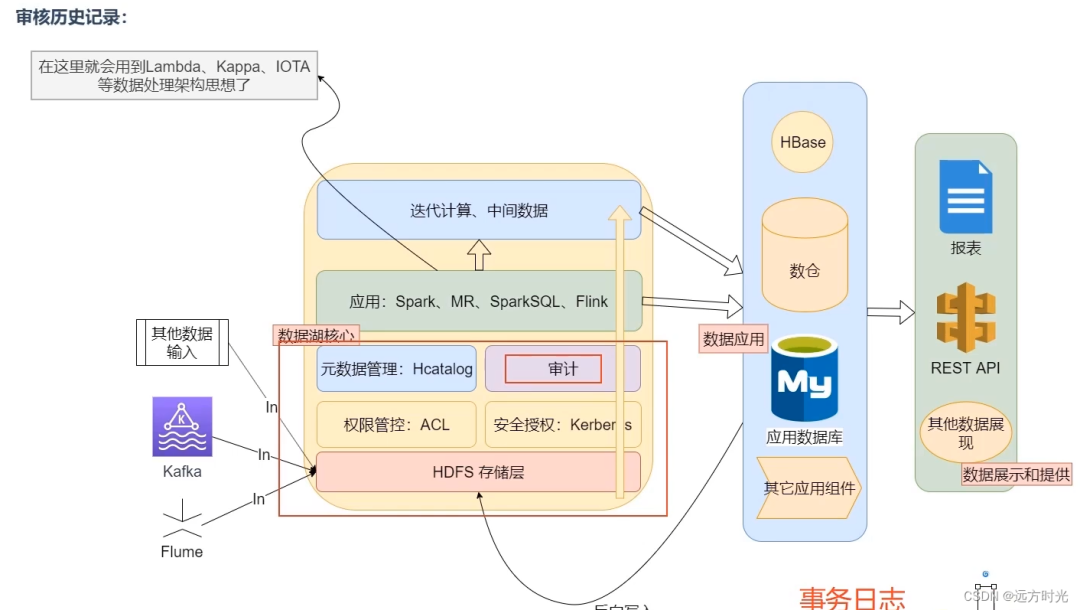 在这个图中我们可以看到,对于数据的审计同样是数据湖需要实现的功能之一。
在这个图中我们可以看到,对于数据的审计同样是数据湖需要实现的功能之一。
基于Delta Lake的事务日志,除了能够提供:事务控制、数据版本控制以外,同样可以通过对事务日志的检索,来做数据的审查。这样更能清楚的知道,在什么时间点,做了什么操作,改了哪些内容,删了什么东西。
统一的批处理和流处理的source 和 sink
Delta Lake的表可以作为离线统计的输出, 同样也可以作为 流式计算的 Source 以及Sink也就是说,不管是离线批处理,还是实时流计算,都可以对同一张表,同一个Schema进行操作。这样,让流和批统一起来,更加适合企业的架构。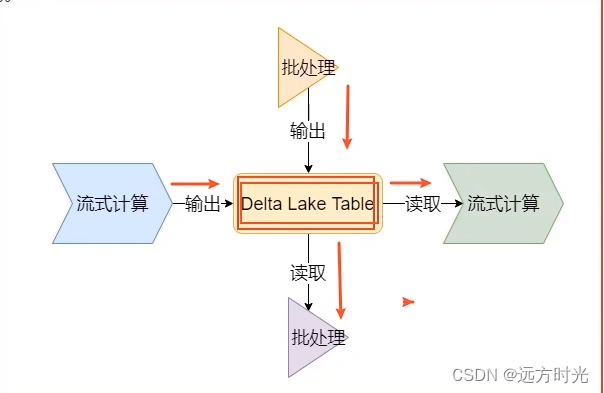 由图可以看出,对于Delta Lake表的操作 不分流和批,调用SparkAPI 可以直接对Delta Lake Table进行操作,因为Delta Lake还有一个特性就是:100%兼容Spark API,Spark API可以直接对Delta Lake Table进行操作。
由图可以看出,对于Delta Lake表的操作 不分流和批,调用SparkAPI 可以直接对Delta Lake Table进行操作,因为Delta Lake还有一个特性就是:100%兼容Spark API,Spark API可以直接对Delta Lake Table进行操作。
八、Delta Lake -代码示例
maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.5.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-core_2.13</artifactId>
<version>2.4.0</version>
</dependency>
代码示例:
import io.delta.implicits.DeltaDataStreamWriter
import org.apache.spark.eventhubs.{EventHubsConf, EventPosition}
import org.apache.spark.sql.functions.{get_json_object, substring}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, SparkSession}
object Test {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("ccuPoc").master("local[*]").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
//iothub链接字符串
val connectionString = "Endpoint=sb://iothub-ns-ccu-1560602-a12efb2383.servicebus.chinacloudapi.cn/;####"
val eventHubsConf: EventHubsConf = EventHubsConf(connectionString)
.setConsumerGroup("iothubtodatalake")
.setMaxEventsPerTrigger(1000)
.setStartingPosition(EventPosition.fromEndOfStream)
val incomingStream: DataFrame = spark.readStream.format("eventhubs").options(eventHubsConf.toMap).load()
//获取vehicleName车名, createAt事件时间,body二进制车辆数据,追加年、月、日、时
val outputStream: DataFrame = incomingStream
.select(
get_json_object($"body".cast("string"), "$.vehicleName").alias("vehicleName"),
get_json_object($"body".cast("string"), "$.data").alias("data"),
get_json_object($"body".cast("string"), "$.createAt").alias("createAt"),
$"body"
).withColumn("createAtYear", substring($"createAt", 1, 4))
.withColumn("createAtMonth", substring($"createAt", 6, 2))
.withColumn("createAtDay", substring($"createAt", 9, 2))
.withColumn("createAtHour", substring($"createAt", 12, 2))
.select()
//控制台打印
/* outputStream
.writeStream
.outputMode("update")
.partitionBy("vehicleName", "createAtYear", "createAtMonth", "createAtDay", "createAtHour")
.format("console") //输出到控制台
.option("truncate", false)
.start().awaitTermination()*/
println("------->> 写入datalake运行成功 <<---------")
//输出到Azure Datalake
outputStream
.writeStream
.outputMode("append")
.partitionBy("vehicleName", "createAtYear", "createAtMonth", "createAtDay", "createAtHour")
.trigger(Trigger.ProcessingTime("5 minutes")) //每5分钟一次输出到数据湖
.option("mergeSchema", "true")
.option("checkpointLocation", "/mnt/stvcdpbatchvehicledev/ods/ods_vehiclefromeventhub_deltaTable/_checkpoints/") //记录消费消息队列的offset
.delta("/mnt/stvcdpbatchvehicledev/ods/ods_vehiclefromeventhub_deltaTable")
.awaitTermination()
}
}
来看看储存的文件什么样子
总目录
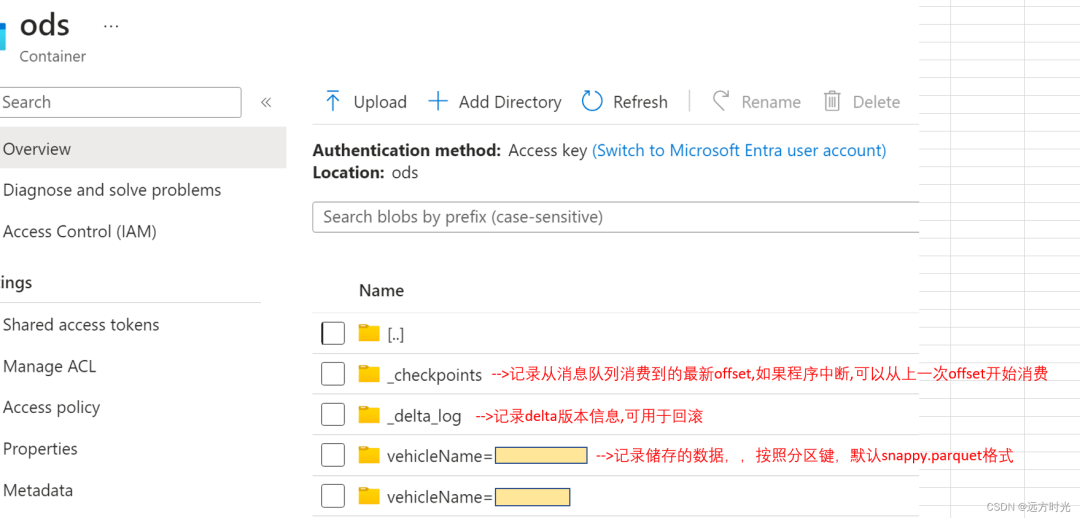
储存数据
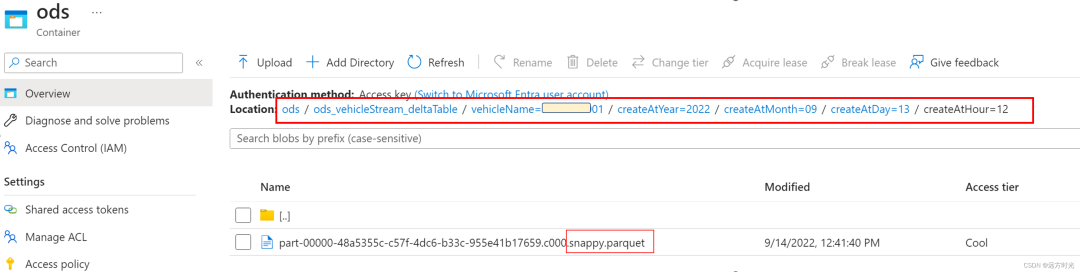
按照我的分区:vehicleId/year/month/day/hour delta默认储存格式为snappy.parquet
delta版本信息是怎么记录的 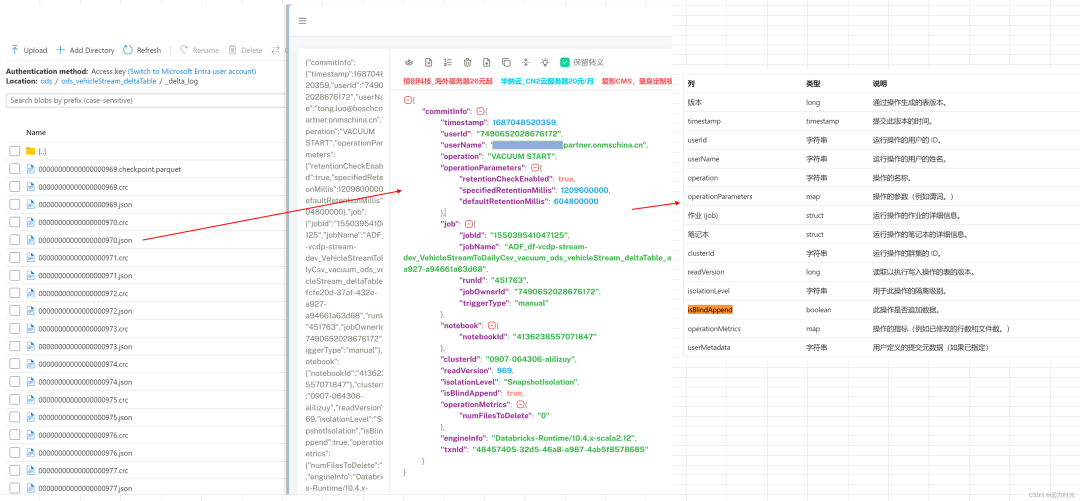
可以使用history命令来查看所有版本信息
查看最新一次操作import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, "/tmp/delta/events")
val fullHistoryDF = deltaTable.history() // get the full history of the table
val lastOperationDF = deltaTable.history(1) // get the last operation
scala> lastOperationDF.show
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+
|version| timestamp|userId|userName|operation| operationParameters| job|notebook|clusterId|readVersion|isolationLevel|isBlindAppend|
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+
| 11|2020-02-13 00:39:...| null| null| MERGE|[predicate -> ((o...|null| null| null| 10| null| false|
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+
_checkpoint目录(重要)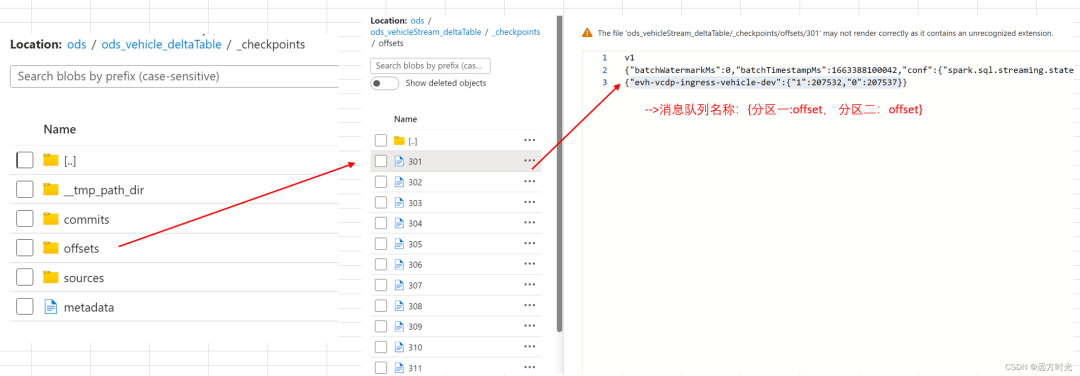 在Spark Structured Streaming中,Checkpoint是一种机制,用于在流式应用程序中维护元数据和状态信息,以确保应用程序的容错性和可靠性。它的主要目的是在应用程序发生故障或重启时,能够从之前的状态继续处理数据流,而不是从头开始重新处理。
在Spark Structured Streaming中,Checkpoint是一种机制,用于在流式应用程序中维护元数据和状态信息,以确保应用程序的容错性和可靠性。它的主要目的是在应用程序发生故障或重启时,能够从之前的状态继续处理数据流,而不是从头开始重新处理。
具体而言,Checkpoint 在 Spark Structured Streaming 中执行以下功能:
容错性: Checkpoint 将应用程序的元数据和状态信息写入持久存储(如分布式文件系统,如HDFS)中。这有助于防止数据丢失,因为在应用程序发生故障时,可以从 Checkpoint 恢复状态,而不是从流的起点重新处理数据。
应用程序更新: Checkpoint 可以用于支持应用程序升级或更改。如果你修改了应用程序的逻辑或添加了新的处理步骤,Checkpoint 可以确保在应用程序重启后,它从先前的状态继续处理数据流。
提高性能: Checkpoint 还可以改善性能,因为它可以帮助 Spark 进行优化执行计划。通过保存中间数据和计算结果,Spark 不必每次都从头开始计算,而是可以在 Checkpoint 处继续执行。
要使用 Checkpoint,你需要提供一个目录路径,该路径指定了在分布式文件系统中存储 Checkpoint 数据的位置。在 Structured Streaming 中,可以使用 writeStream 方法的 option("checkpointLocation", "") 选项来指定 Checkpoint 的位置。