
显著改善分割预测,ETH开源基于情景图储存网络的视频目标分割|ECCV2020
点击蓝字
关注我们

极市导读
本文着力于解决视频目标分割领域的一个基本问题:使分割模型有效适应特定视频以及在线目标的外观变化。提出了一种简洁快速的新图存储机制,显著改善了分割预测。此外,图存储网络产生的框架还可以推广到one-shot和zero-shot视频目标分割任务。>>极市直播预告:CSIG-ECCV2020 论文预交流会,29位ECCV2020一作联合直播

1.引言
2.方法
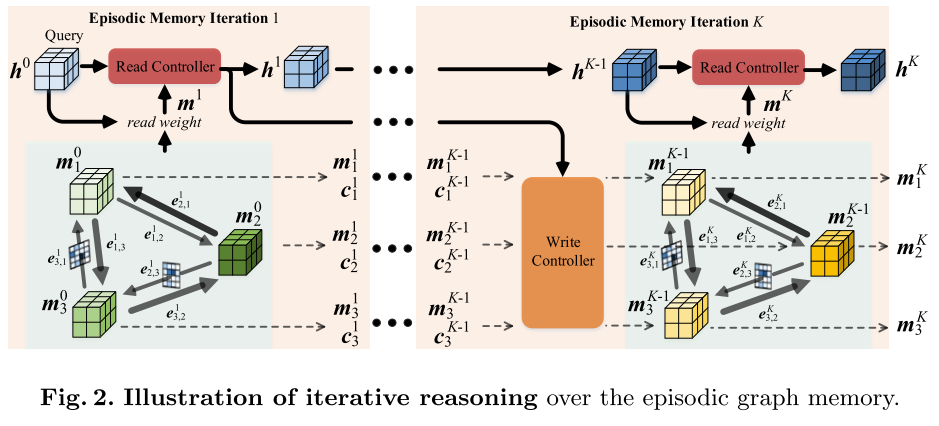
2.1 预备知识:情景记忆网络
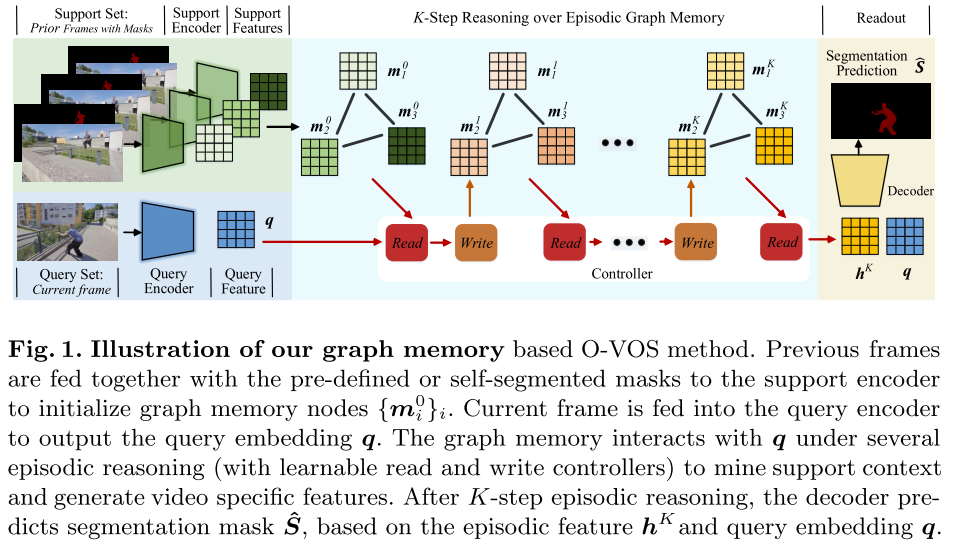
控制器:进行读取和写入操作,与图存储器交互,通过权重的缓慢更新来长期存储。通过控制器,模型可学习两方面的内容:1.其放入内存的表示类型,2.以后如何将这些表示用于细分预测的通用策略。
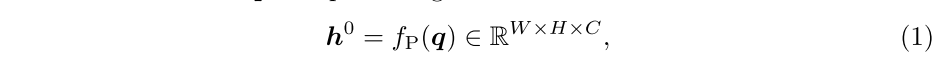
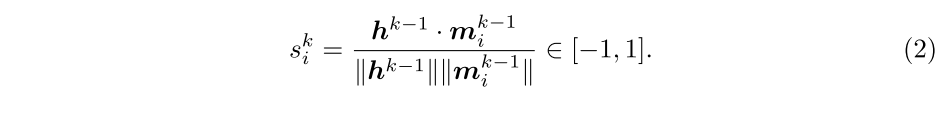
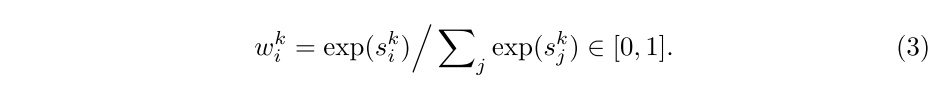
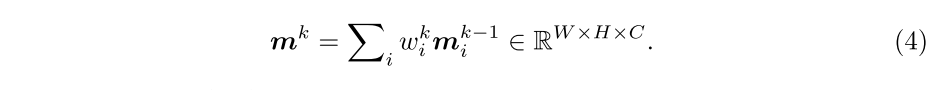
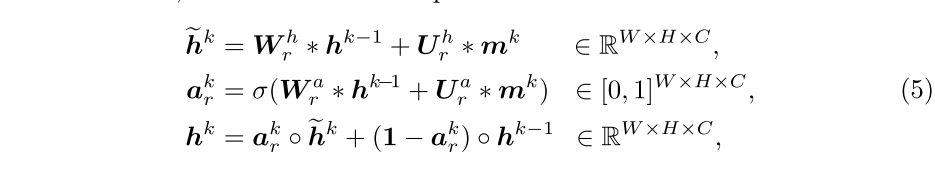
首先将从到的关系公式化为其特征矩阵的内积相似性:
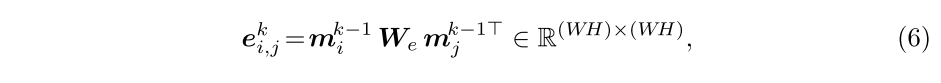
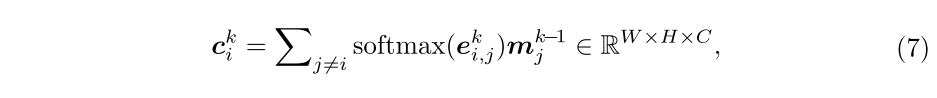
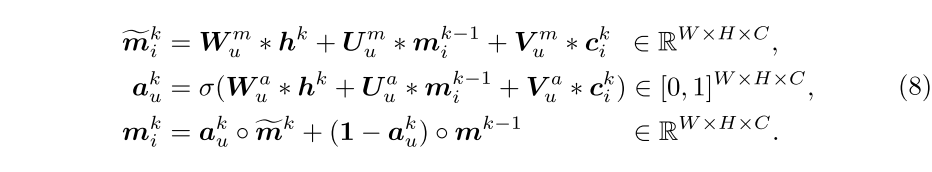
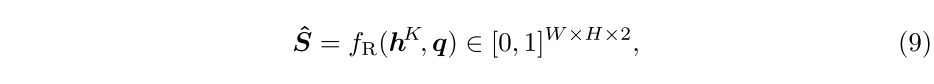
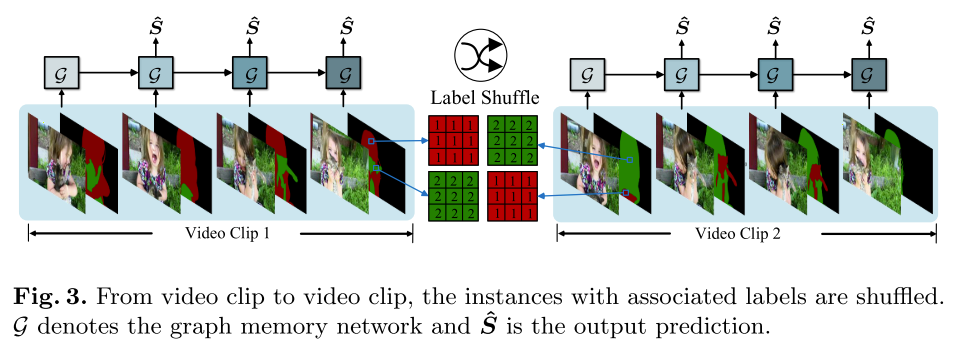
3.实验结果
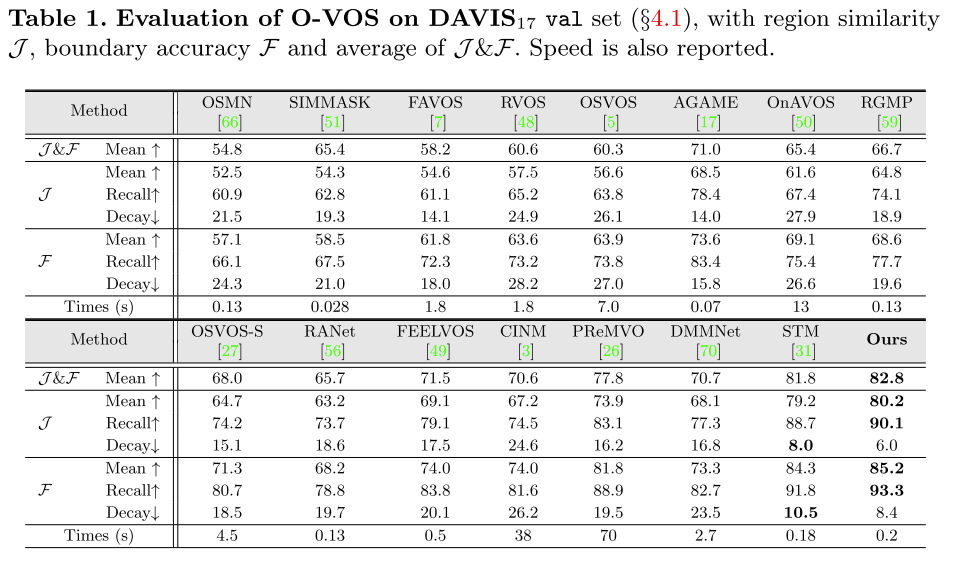
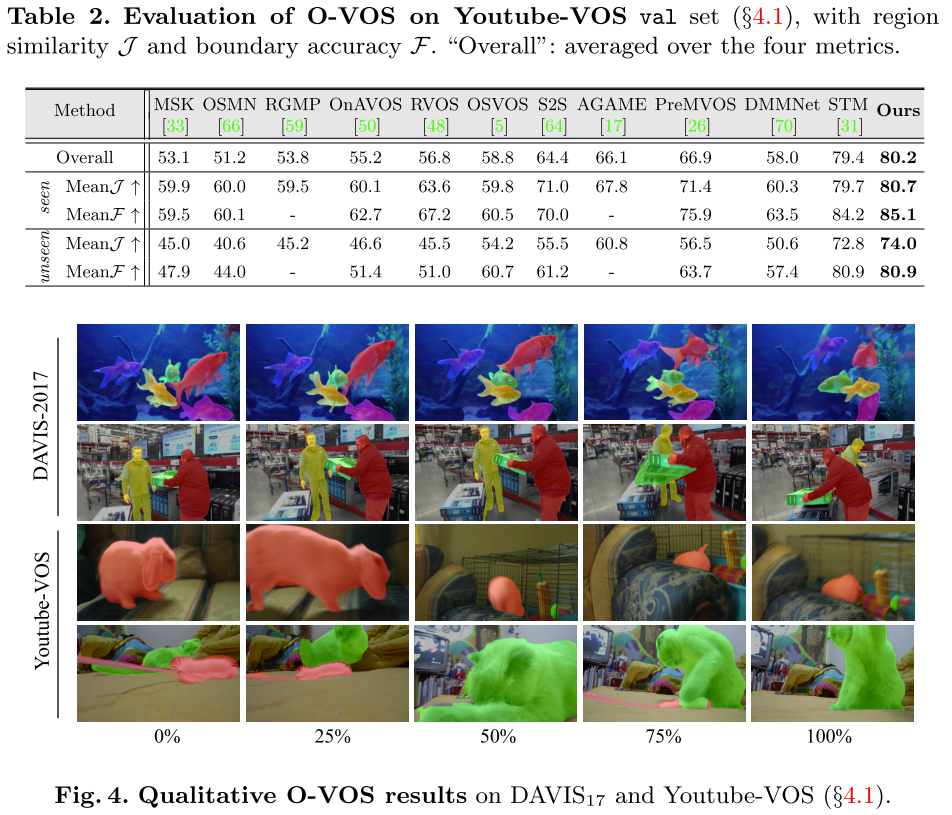
3.2 Z-VOS的性能
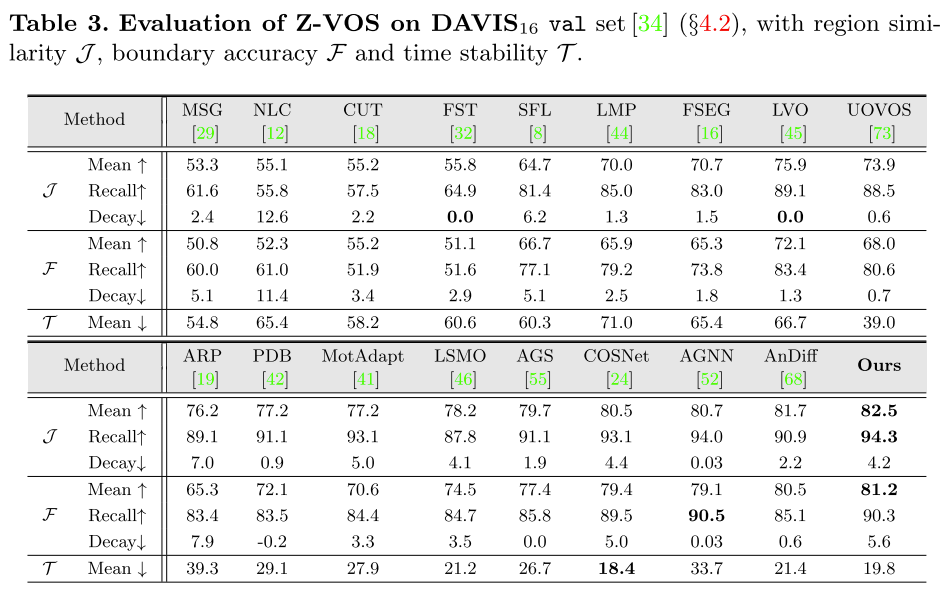
表3 Z-VOS在DAVIS16的评估
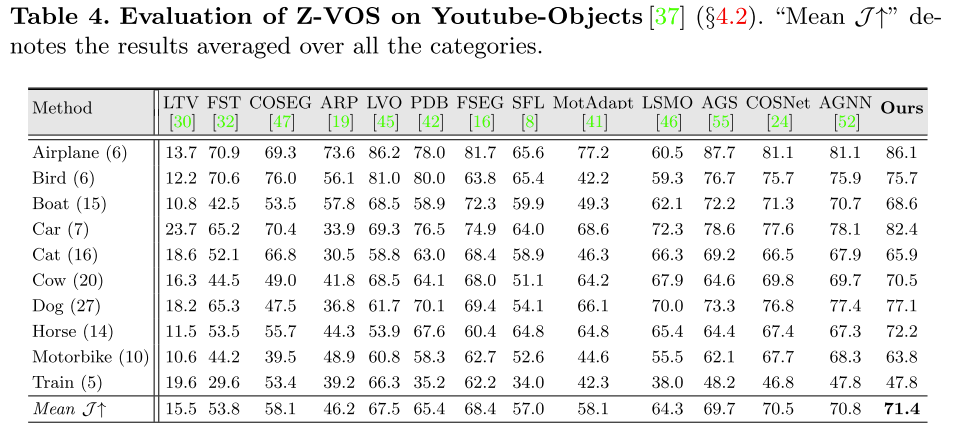
表4 Z-VOS在Youtube-Object的评估
 图5 Z-VOS的量化结果
图5 Z-VOS的量化结果
4.总结

评论