
从实现原理谈谈低代码
点击关注公众号,Java干货及时送达👇

来源:zhuanlan.zhihu.com/p/451340998
1 本文里的「低代码」指的是什么? 2 低代码的实现方案 3 生成代码的方案算不算低代码? 4 前端代码实现原理 - 界面渲染 5 交互逻辑的实现 6 后端低代码的方案 7 低代码平台未来会怎样? 8 总结 9 在了解原理之后
我们在低代码领域探索了很多年,从2015 开始研发低代码前端渲染(amis),从 2018 年开研发后端低代码数据模型,发布了爱速搭低代码平台,这些年调研过了几乎所有市面上的相关技术和产品,发现虽然每家产品细节都不太一样,但在底层技术上却只有少数几种方案,因此我们认为不同产品间的最大区别是实现原理,了解这些实现原理就能知道各个低代码平台的优缺点,所以本文将会介绍目前已知的各种低代码实现方案,从实现原理角度看低代码。
1 本文里的「低代码」指的是什么?
在讨论各个低代码方案前,首先要明确「低代码」究竟是什么?
这个问题不好直接回答,因为低代码是非常宽泛的概念,有很多产品都声称自己的低代码,但我们很容易反过来回答另一个问题:「什么是低代码产品唯一不可缺少的功能?」
我认为这个功能是可视化编辑,因为非可视化编辑就是代码编辑,而只有代码编辑的产品不会被认为是低代码,因此可视化编辑是低代码的必要条件,低代码其实还有另一个更清晰的叫法是可视化编程。
既然可视化编辑是低代码的必要条件,那从实现角度看,实现可视化编辑有什么必要条件?
我认为可视化编辑的必要条件是「声明式」代码,因为可视化编辑器只支持「声明式」代码。
解释一下什么是「声明式」,除了声明式之外还有另一种代码模式是「命令式」,我们分别举两个例子,如果想绘制一个红色区块,用「声明式」来实现,可以使用 HTML+CSS,类似下面的方法:
"background:red; height:50px"> 而换成用「命令式」来实现,可以使用 Canvas API,类似下面的方法:
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'red';
const rectangle = new Path2D();
rectangle.rect(0, 0, 100, 100);
ctx.fill(rectangle);
虽然最终展现效果是一样的,但这两种代码在实现思路上有本质区别:
「声明式」直接描述最终效果,不关心如何实现。 「命令式」关注如何实现,明确怎么一步步达到这个效果。
从可视化编辑器的角度看,它们的最大区别是:
「声明式」可以直接从展现结果反向推导回源码 「命令式」无法做到反向推导
反向推导是编辑器必备功能,比如编辑器里的常见操作是点选这个红色区块,然后修改它的颜色,在这两种代码中如何实现?
如果是「声明式」的 HTML+CSS,可以直接改 style 的 background 值,而基于 Canvas 的命令式代码则无法实现这个功能,因为无法从展现找到实现它的代码,命令式代码实现同样效果的可能路径是无数的,除了前面的示例,下面这段代码也可以实现一样的效果:
const ctx = canvas.getContext('2d');
ctx.beginPath();
ctx.moveTo(0, 0);
ctx.lineTo(50, 0);
ctx.strokeStyle = '#ff0000';
ctx.lineWidth = 100;
ctx.stroke();
甚至有可能这个颜色是多个字符串加随机数拼接而成,即便通过静态分析也找不到来源,从而无法实现可视化修改。
「命令式」代码无法实现可视化编辑,而可视化编辑是低代码唯一不可少的功能,所以我们可以得到结论:所有低代码平台必然只能采用「声明式」代码,这也是为什么所有低代码平台都会有内置的「DSL」。
既然低代码都是声明式,那我们可以通过分析其它「声明式」语言来了解低代码的优缺点,其实在专业研发里,声明式语言在部分领域已经是主流了:
HTML+CSS 是一种页面展现的 DSL SQL 是一种数据查询及处理的 DSL K8S 的 yaml 是一种服务部署的 DSL NGINX conf 是一种反向代理的 DSL
上面这些方案目前都是主流,但它们早期并不被看好,比如十几年前还曾经争论过到底是用 B/S 还是 C/S 架构,CSS 2 的功能主要是面向图文排版,并不适合用来构建应用界面。
SQL 最开始也不被看好,下面引用《硅谷简史》这本书里的部分文字:
1970年,IBM研究员特德·科德(Ted Codd)发表了一篇里程碑式的论文,《大型数据库的系统模型》,介绍了关系数据库理论。
当时大多数人认为关系数据库没有商业价值,因其速度太慢,不能满足大规模数据处理或者大量用户存取数据,虽然关系数据库理论上很漂亮而且易于使用,但它的速度太慢。
上面两段其实说的是 Oracle 的发家故事,可以看到当时关系型数据库并不被看好,因为大家都觉得慢,这点很好理解,数据库在查询前还得先解析 SQL语法、估算各种查询的代价、生成执行计划,存储也只能使用通用的数据结构,没法根据不同业务进行定制。
综合来看这些「声明式」语言有以下优点:
容易上手,因为描述的是结果,语法可以做得简单,非研发也能快速上手 HTML 及 SQL。 支持可视化编辑,微软的 HTML 可视化编辑 FrontPage 在 1995 年就有了,现在各种 BI 软件可以认为是 SQL 的可视化编辑。 容易优化性能,无论是浏览器还是数据库都在不断优化,比如可以自动改成并行执行,这是命令式语言无法自动实现的。 容易移植,容易向下兼容,现在的浏览器能轻松渲染 30 年前的 HTML,而现在的编译器没法编译 30 年前的浏览器引擎代码。
而这些语言的缺点是:
1、只适合特定领域,命令式的语言比如 JavaScript 可以用在各种领域,但 HTML+CSS 只适合渲染文档及界面,SQL 只适合做查询,所有这些语言都。
2、灵活性差,比如 SQL 虽然内置了很多函数,但想只靠它实现业务是远远不够的,有些数据库还提供了用户自定义函数功能(UDF),通过代码来扩展。
3、调试困难,遇到问题时如缺乏工具会难以排查,如果你在Firefox出现前开发过页面就会知道,由于IE6没有开发工具,编写复杂页面体验很差,遇到问题要看很久代码才发现是某个标签没闭合或者 CSS 类名写错了。
4、强依赖运行环境,因为声明式只描述结果而不关注实现,因此强依赖运行环境,但这也带来了以下问题:
功能取决于运行环境,比如浏览器对 CSS 的支持程度决定某个属性是否有人用,虽然出现了CSS Houdini 提案,但 Firefox 和 Safari 都不支持,而且上手成本太高,预计以后也不会流行。 性能取决于运行环境,比如同一个 SQL 在不同数据库下性能有很大区别。 对使用者是黑盒,使用者难以知道最终实现,就像很少人知道数据库及浏览器的实现细节,完全当成黑盒来使用,一旦遇到性能问题就不知所措。 技术锁定,因为即便是最开放的 HTML 也无法解决,很多年前许多网站只支持 IE,现在又变成了只支持 Chrome,微软和 Opera 在挣扎了很多年后也干脆直接转向用 Chromium。同样的即便有 SQL 标准,现在用的 Oracle/SQL Server 应用也没法轻松迁移到 Postgres/MySQL 上。低代码行业未来也一样,即便出了标准也解决不了锁定问题,更有可能是像小程序标准那样发展缓慢,功能远落后于微信。
因为低代码就是一种声明式编程,所以这些「声明式」优缺点,其实就是低代码的优缺点,了解声明式的历史及现状就能更好理解低代码,因为:
低代码的各种优点是「声明式」所带来的。 低代码被质疑的各种缺点也是「声明式」所导致的。
2 低代码的实现方案
说完了声明式,我们就对低代码有了全面认识,接下来进入正题,开始介绍已知的各种低代码实现原理,将会分为前端和后端两部分。
3 生成代码的方案算不算低代码?
在讨论各种方案前,有一种方案比较特别,它虽然也有配置规范或 DSL,甚至有可视化编辑,但最终应用运行是通过生成代码的方式实现的,不依赖依赖运行环境。
这个方案最大的优点是可以和专业开发整合,因此灵活性强、可以使用原有的开发流程,本质上和专业开发一样。
但也有如下缺点:
强依赖研发,无法做到给非研发使用,因为后续代码需要编译上线。 无法持续可视化编辑,因为代码无法可视化编辑,生成代码后只要有修改就没法再反向还原成低代码的形式,后续只能代码编辑。 难以实现完全用低代码开发应用,因为不能生成太复杂的代码,使得这种方案一般不包括交互行为,通常是只有前端界面支持可视化编辑。 无法做到向下兼容,因为生成的那一瞬间代码依赖的框架版本就固定了,目前还没见过哪款前后前端框架做过到完全向下兼容。
因此我认为生成代码的方案不算真正的低代码,本质上它还是一种开发辅助方式,一种高级点的脚手架工具,和大部分IDE的生成样板代码能力一样,使用这种方案无法做到持续可视化开发,我还没见过有人将 HTML+CSS 编译成 C++ 代码后二次开发。
4 前端代码实现原理 - 界面渲染
前面提到前端 HTML+CSS 可以看成一种描述界面的低代码 DSL,因此前端界面实现低代码会比较容易,只需要对 HTML+CSS 进行更进一步封装,这里以我们的开源项目 amis 为例进行介绍。
amis 核心原理是将 JSON 转成自研的 React 组件库,然后使用 React 进行渲染。
比如下面这段 JSON:
{
"type": "page",
"title": "页面标题",
"subTitle": "副标题",
"body": {
"type": "form",
"title": "用户登录",
"body": [
{
"type": "input-text",
"name": "username",
"label": "用户名"
}
]
}
}
可以理解 amis 原理就是转成了下面这样的 React 组件树,最终由各个 React 组件库渲染 HTML:
"页面标题" subTitle="副标题">
"用户登录">
"username" label="用户名" />
虽然也有低代码平台直接使用 HTML+CSS 来实现更灵活的界面控制,但这样做会导致用起来复杂度高,因为通常需要多层嵌套 HTML 才能实现一个组件,使用者还必须熟悉 HTML 及 CSS,上手门槛过高,因此大部分低代码平台都是类似 amis 那样使用 JSON 进行简化。
这里有个小问题,为什么大家几乎全都使用 JSON?我觉得有两方面原因:
低代码平台编辑器几乎都是基于 Web 实现,JavaScript 可以方便操作 JSON。 JSON 可以支持双向编辑,它的读取和写入是一一对应的。
第二点怎么理解?可以对比一下 YAML,它有引用功能,导致了不好实现双向编辑,比如下面 YAML 示例:
paths:
root_path: &root
val: /path/to/root/
patha: &a
root_path: *root
转成了对应的 JSON 数据后,就变成了:
{
"paths": {
"root_path": {
"val": "/path/to/root/"
},
"patha": {
"root_path": {
"val": "/path/to/root/"
}
}
}
}
可以看到之前的引用关系没了,而是复制出了一部分,如果直接基于这个数据进行可视化编辑,编辑器在修改的时候就只会改一处,也没法再还原成之前的 YAML 了,要想实现 YAML 可视化编辑就不能先转成 JSON,而是要对 YAML 解析后的树形结构进行操作,前端界面实现成本很高,因此目前还没见过 YAML 的可视化编辑器。
但 JSON 的优点就是它的缺点,因为它的用途是数据交换而不是人工编写,导致基于 JSON 构建 DSL 不方便编辑,会有以下 3 个问题:
不支持注释 不支持多行字符串 语法过于严格,比如不支持单引号,不能在最后多写一个逗号
其中我们对这个注释问题进行了特殊支持,开发了带注释的 JSON 解析,存储的时候将注释内嵌到一个特殊的字段中,在代码显示的时候将它提取出来变成注释。
另外许多低代码平台会将这个 JSON 配置隐藏,只提供界面编辑,但在 amis 可视化编辑器里提供了直接修改 JSON 的功能,因为对于熟悉的开发者,直接编写 JSON 要比在属性面板里找半天效率高,还可以直接将 amis 文档中的示例粘贴进来快速创建。

amis 开始编辑器里 JSON 编辑模式
前面提到声明式容易向下兼容,amis 自己就是最好的例子,在 amis 诞生的 2015 年前端框架和现在有大量区别:
Vue 还是 1,现在已经到 3 了,不向下兼容。 Angular 还是 1,现在已经 13 了,不向下兼容。 React 虽然整体用法没变,但有大量细节不向下兼容,加上 hooks 推出后,许多第三方库改成了 hooks 版本,导致旧的类组件形式没法直接使用。
而 amis 早期的界面配置现在还能继续使用,不受框架升级影响。
5 交互逻辑的实现
前面说到前端界面低代码是比较容易,但交互及逻辑处理却很难低代码话,目前常见有三种方案:
使用图形化编程 固化交互行为 使用 JavaScript
先说第一种图形化编程,这是非常自然的想法,既然低代码的关键是可视化,那直接使用图形化的方式编程不就行了?
但我们发现这么做局限性很大,本质的原因是「代码无法可视化」,这点在 35 年前没有银弹的论文里就提到了。
为什么代码无法可视化?首先想一想,可视化的前提条件是什么?
答案是需要具备空间形体特征,可视化只能用来展现二维及三维的物体,因为一维没什么意义,四维及以上大部人无法理解,所以如果一个事物没有形体特征,它就没法被可视化。
举个例子,下面是一段 amis中 代码,作用是遍历 JSON 并调用外部函数进行处理:
function JSONTraverse(json, mapper) {
Object.keys(json).forEach(key => {
const value = json[key];
if (isPlainObject(value) || Array.isArray(value)) {
JSONTraverse(value, mapper);
} else {
mapper(value, key, json);
}
});
}
虽然只有 10 行代码,却包含了循环、调用函数、类型检测、分支判断、或操作符、递归调用、参数是函数这些抽象概念,这些概念在现实中都找不到形体的,你可以尝试一下用图形来表示这段代码,然后给周围人看看,我相信任何图形化的尝试都会比原本这段代码更难懂,因为你需要先通过不同图形来区分上面的各种概念,其他人得先熟悉这些图形符号才能看懂,理解成本反而更高了。
代码的这些抽象思维难以像积木一样进行拼接,积木拼接这种方式只适合用来实现简单的逻辑,比如 scratch。
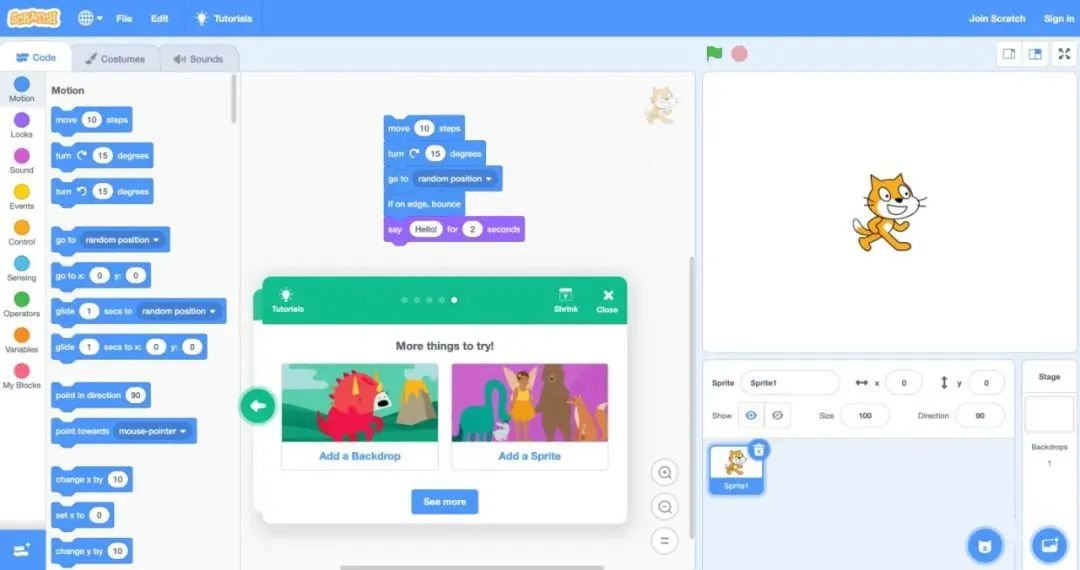 Scratch
Scratch
而前面图形化是低代码唯一不可少的功能,这就使得低代码不适合做复杂的抽象逻辑处理,这是图形化缺陷决定的,因此在复杂逻辑处理方面低代码永远无法彻底取代专业代码开发。
但如果是面向特定领域,低代码平台可以先将这个领域难以图形化的算法预置好,让使用者只需做简单的处理,比如在 Blender 中将 PBR 算法封装了,使用的时候只需要调整参数就行。
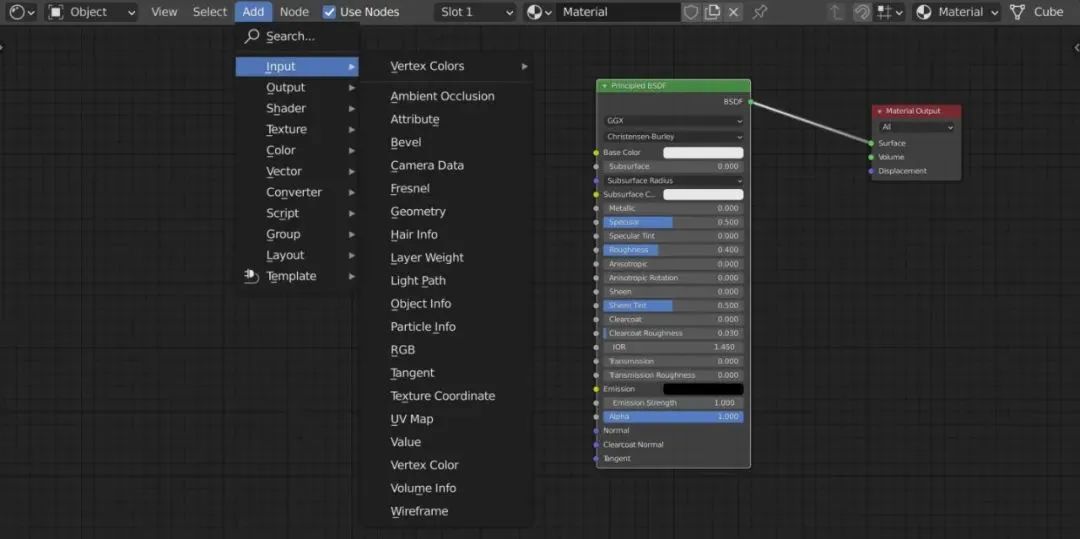 Blender 中的材质节点编辑
Blender 中的材质节点编辑
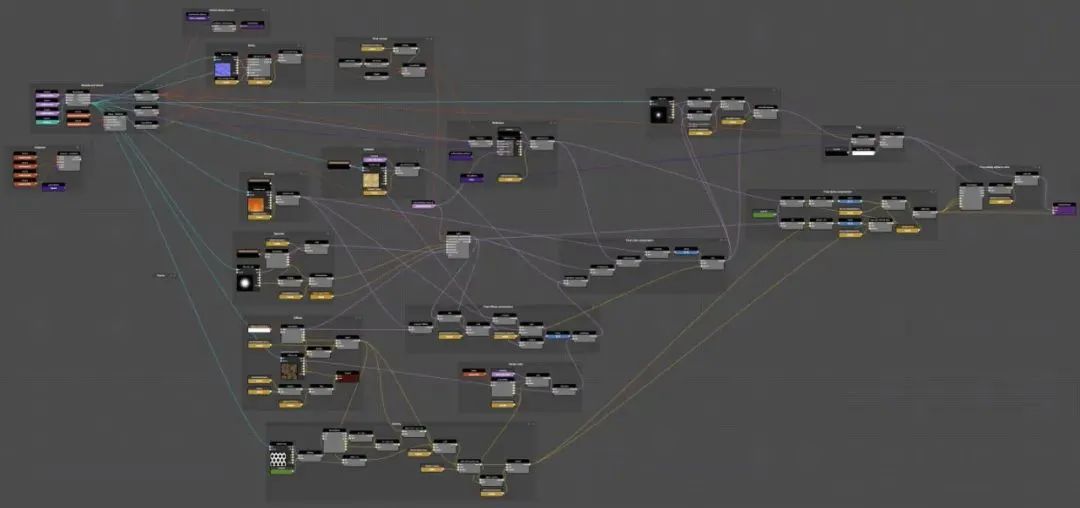
如果真要用节点实现这个算法会非常复杂,大概长这样:
在复杂逻辑下,图形中的连线反而变成了视觉干扰,比如下面的例子:
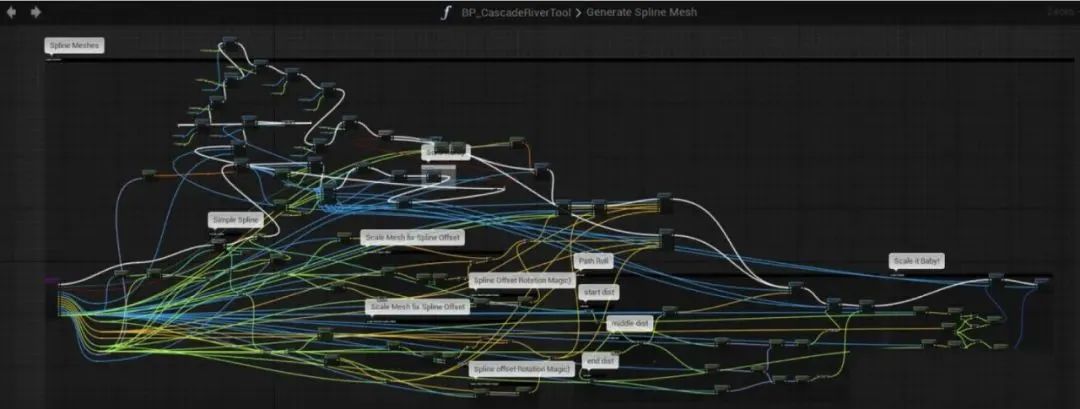 来自 UE4 Blueprints From Hell 里的一张图
来自 UE4 Blueprints From Hell 里的一张图
想象一下假设客户做出了上面这个图的复杂逻辑,然后找你排查问题,而客户的程序是部署在内网的,没法导出,只能通过微信拍屏幕给你看……
因此我认为图形化不适合用来实现业务逻辑,只适合用来做更高层次流程控制,比如审批流,审批流是现实真实存在的,没有复杂的抽象逻辑,因此适合图形化。
在爱速搭中,我们除了实现流程功能,还实现了树形结构的 API 编排功能,它本质上是模仿代码结构,将会在后面进行介绍。
说完了图形化编程,接下来谈第二种方案:固化交互行为,这是不少低代码平台的做法,我们还是以 amis 为例进行介绍。
amis 将常用的交互行为固化并做成了配置,比如弹框是下面的配置:
{
"label": "弹框",
"type": "button",
"actionType": "dialog",
"dialog": {
"title": "弹框",
"body": "这是个简单的弹框。"
}
}
除了弹框之外还有发起请求、打开链接、刷新其它组件等,使用固化交互行为有下面两个优点:
可以可视化编辑 整合度高,比如弹框里可以继续使用 amis 配置,通过嵌套实现复杂的交互逻辑
但这个方案最大的缺点是灵活性受限,只能使用 amis 内置的行为。
要实现更灵活的控制,还是得支持第三个方案:JavaScript,目前有的低代码平台只在界面编辑提供可视化编辑,一旦涉及到交互就得写 JavaScript,这和 30 年前的 C++ Builder 本质上是一样的:
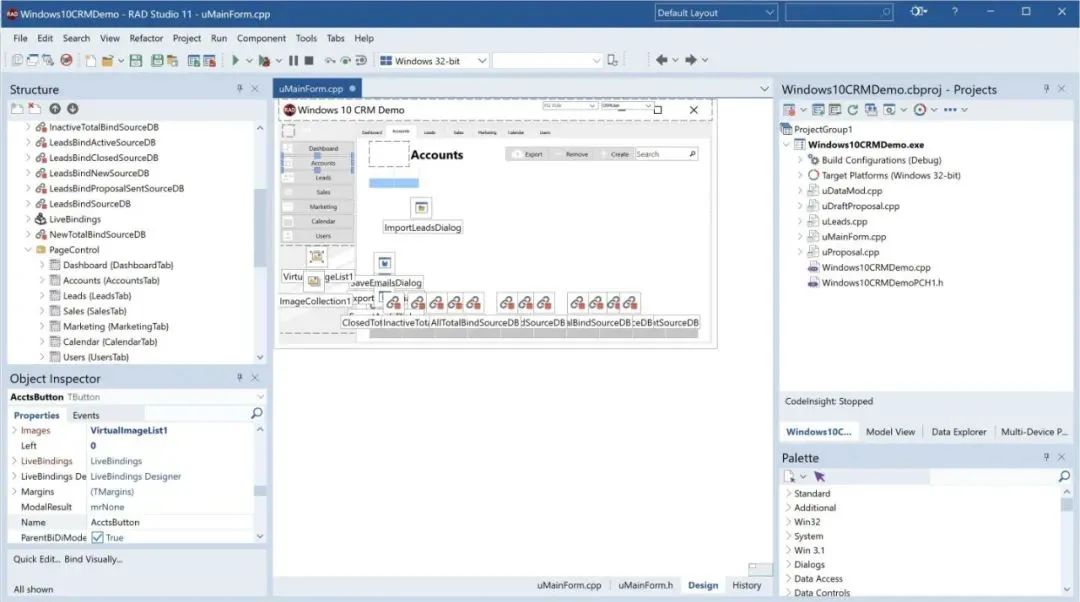 RDA Studio 11 的界面编辑
RDA Studio 11 的界面编辑
但第三个方案的最大缺点就是无法可视化编辑,因此不算是低代码。
6 后端低代码的方案
前端讨论完了,接下来是后端部分,后端低代码需要解决以下三个问题:
1、如何自定义数据存储?
低代码平台需要支持用户存储自定义数据,因为每个应用所需的字段是不一样的。
自定义数据存储是后端低代码最重要的功能,使用什么方案将直接影响这个产品的适用范围,目前我们已知有 5 种方案,每种都有自己的优缺点。
存储的实现方案 1:直接使用关系型数据库
这个方案的原理是将数据模型的可视化操作转成数据库 DDL,比如添加了一个字段,系统会自动生成表结构变更语句:
ALTER TABLE 'blog' ADD 'title' varchar(255) NULL;
这个方案的优点是:
所有方案里唯一支持直连外部数据库,可以对接已有系统。 性能高和灵活性强,因为可以使用高级 SQL。 开发人员容易理解,因为和专业开发是一样的。
但它的缺点是:
需要账号有创建用户及 DDL权限,如果有安全漏洞会造成严重后果,有些公司内部线上帐号没有这个权限,导致无法实现自动化变更。 DDL 有很多问题无解,比如在有数据的情况下,就不能再添加一个没有默认值的非 NULL 字段。 DDL 执行时会影响线上性能,比如 MySQL 5.6 之前的版本在一个大数据量的表中添加索引字段会锁整个表的写入(但也有数据库不受影响,比如 TiDB、OceanBase 支持在线表结构变更,不会阻塞读写)。 部分数据库不支持 DDL 事务,比如 MySQL 8 之前的版本,导致一旦在执行过程中出错将无法恢复。 实现成本较高,需要实现「动态实体」功能,如果要支持不同数据库还得支持各种方言。
尽管这个方案有很多缺点,但它的优点也很突出,因此爱速搭里实现了这个方案,因为我们觉得能连已有数据库是非常重要的,其它方案都只适合用来做新项目,这个方案使得可以逐步将已有项目低代码化,不需要做数据迁移。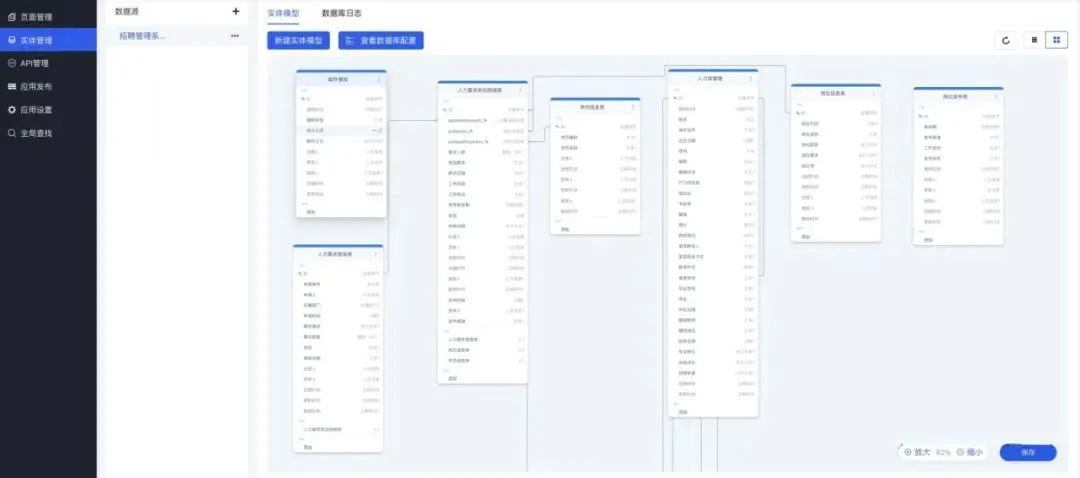
爱速搭里的数据库模型
实现这个方案的关键是「动态实体」,在专业开发中实体(Entity)定义都是静态的,以 Java 为例,它从 2006 年开始就有专门的 JPA 规范,但这个规范是定义基于 Java 代码注解,使得需要经过编译才能使用,毕竟它的定位是面向专业开发,只有写在代码里才能支持代码提示,提升开发体验。
而低代码平台中需要将这个实体定义抽象成配置,在运行时动态生成实体,如果使用 JPA 就需要生成 Java 代码后进行编译,这很容易出错,不太适合低代码平台,所以使用这个方案需要实现「动态实体」功能,是整个方案最大难点。
存储的实现方案 2:使用文档型数据库
文档型数据库不需要预先定义表结构,因此它很适合用来存储用户自定义数据,这个方案实现起来比较简单,以 MongoDB 为例,可以这样做:
用户创建一个自定义表的时候,系统就自动创建一个 collection,所有这个表的数据都存在这个 collection 里。 用户新增字段的时候,就随机分配一个 fileId,后续对这个字段的操作都自动映射到这个 fileId 上,用 fileId 的好处是用户重命名字段后还能查找之前的数据,因为所有数据查询底层都基于这个 fileId。 查询的时候先找到对应的 collection,再通过 meta 信息查询字段对应的 fileId,使用这个 fileId 来获取数据。
这个方案的优点是实现简单,用户体验可以做得更好,是目前大部分零代码平台的选择,使用这个方案的产品也很好识别,只要看一下它的私有部署文档,如果有要求装 MongoDB 就肯定是。
但这个方案也有显著缺点:
无法支持外部数据库,数据是孤岛,外部数据接入只能通过导入的方式。 MongoDB 在国内发展缓慢,接受度依然很低,目前还没听说有哪家大公司里最重要的数据存在 MongoDB 里,一方面有历史原因,另一方面不少数据库都开始支持 JSON 字段,已经能取代大部分必须用 MongoDB 的场景了。 不支持高级 SQL 查询。
你可能会问,现在 MySQL、Postgres 等数据库都支持 JSON 字段类型了,是否可以用这个字段来实现低代码?
答案是不太行,只适合数据量不大的场景,虽然 JSON 字段可以用来存用户自定义数据,但无法创建字段索引,比如在 MySQL 要想给 JSON 创建索引,还是得创建一个特殊的字段,这又需要 DDL 权限了,没有索引会导致这个方案无法支持大量数据查询。
在爱速搭中我们也实现这个方案,目前是基于 MySQL JSON 字段,后续可能也会支持存储使用 MongoDB,目前它的使用场景是流程执行过程中的数据存储,因此数据量不会很大,我们希望流程功能用起来可以更简单些。
它的最大特点是界面编辑和数据存储是统一的,当你拖入文本框到页面后就会自动创建对应的字段,不需要先创建数据模型再创建界面,因此用起来更简单。
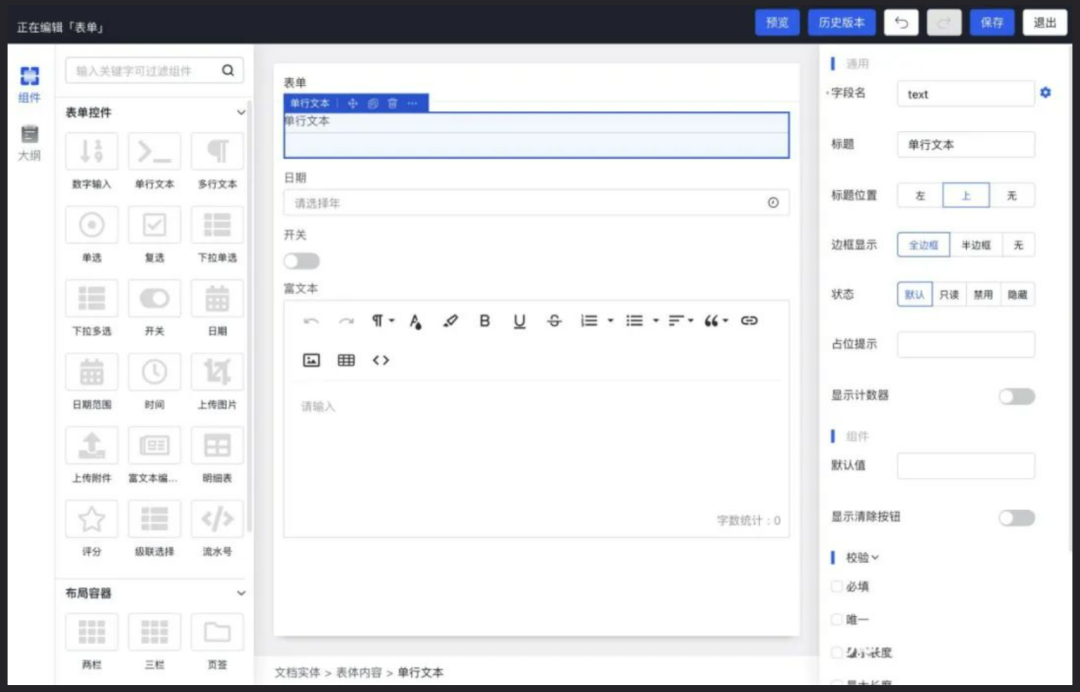
爱速搭里的表单模型
存储的实现方案 3:使用行代替列
这是很多可扩展平台里使用的技术,比较典型的是 WordPress,它的扩展性很强,装个扩展就能变成电商网站。而整个 WordPress 只有 12 个表,它是怎么做到的?方法是靠各种 meta 表,比如用于扩展文章的 wp_postmeta 表结构如下:
CREATE TABLE wp_postmeta (
meta_id bigint(20) unsigned NOT NULL auto_increment,
post_id bigint(20) unsigned NOT NULL default '0',
meta_key varchar(255) default NULL,
meta_value longtext,
PRIMARY KEY (meta_id),
KEY post_id (post_id),
KEY meta_key (meta_key)
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
其中的关键就是 meta_key 和 meta_value 这两个字段,相当于将数据库当 KV 存储用了,因此可以任意扩展字段名及值。
这个方案的优点是实现简单,但缺点也很明显:
查询性能低,如果有 10 个字段就要查 10 行。 无法支持 SQL 高级查询,因为数据是按行存的。
这个方案主要用于成熟项目的扩展,比如在 CRM 产品中允许用户扩展字段,但因为性能较低,并不适合通用低代码平台。
存储的实现方案 4:元信息+宽表
早期数据库不支持 JSON 字段的时候,有些开发者会预留几个列来给用户扩展自定义属性,比如在表里加上 ext1、ext2、ext3 字段,让用户可以存 3 个定制数据,基于这个原理我们可以进一步扩展,通过预留大量列来实现应用自定义存储。
这个方案最早出现在 force.com,具体细节可以阅读它架构说明文档[1]。
实现它有两个关键点:元数据、预留列,这里简单说明一下原理,首先系统预先创建一个 500 列的表,比如就叫 data:
| tenant_id | table_id | uuid | value0 | value1 | …… | value 4000 |
|---|---|---|---|---|---|---|
也可以创建更多,但注意有的数据库对列的数量有限制,比如 MySQL 最多是 4096 列。
上面的 data 表里主要有 4 类字段:
tenant_id 是租户 id,用于隔离不同租户 table_id 是自定义表的 id uuid 是具体这一行数据的 id 后面的 value0 到 value500 都是预留的列,用于存储实际数据,一般使用变长字符串类型
当用户给这个表新增一个字段的时候,怎么知道这个字段放哪?这就需要另一个用于描述字段信息的元数据表,比如增加一个「标题」字段时,使用另一个 table_fields 表来描述这个字段的信息,示例如下:
| tenant_id | table_id | field_id | value_index | name | type |
|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 标题 | string |
在这个 table_fields 表里:
tenant_id 和 table_id 和前面一样。 field_id 对应的是给这个「标题」字段分配的 id。 value_index 对应前面那个 data 表里预览列的位置,比如这个值是 0,就意味着 value0 列被分配给了这个「标题」字段。 name 用来存名称,type 用来标识类型,这样查询和写入数据的时候,首先从这里查询 value_index 是什么,然后再去前面那个预留列的表中查询对应列的值。
最终在实际查询的时候需要根据元数据表做一下转换,比如 select 标题 from blog 要转成 select value0 from data where tenal_id = 1 and table_id = 1。
要完全实现这个方案还有很多细节问题得解决,由于篇幅原因这里不详细介绍,感兴趣可以阅读前面提到的 force.com 技术白皮书,这里列举其中几个问题:
因为存储只能是字符串,所以对于日期、数字等其他类型,因此读取的时候需要根据类型使用数据库里的函数进行转换,比如 STR_TO_DATE。 需要单独处理唯一性功能,因为这个数据表是所有租户共用的,没法设置表级别的唯一性索引,这时就需要新建一个表来单独做,坏处是数据多份容易产生不一致,需要在所有更新操作都加事务。 需要单独处理索引功能,同样是因为字段是字符串,因此没法直接在 data 表里加索引,如果数据存储的是数字,排序就是错的,为了解决这个问题需要另外创建一个一个包含常见字段的索引表,数据更新的时候。 自增字段需要自己实现。 元数据信息需要缓存,不然每次查询前都需要先查询元数据信息,然后再去查询真正的数据。
这个方案比前面几个方案的优点是:
比起第一种原生数据库表方案,它不需要 DDL 操作,不容易出问题,跟适合 SaaS 产品。 比起第二种文档型数据库方案,它的存储使用更为成熟的关系型数据库,相关的运维工具多。 比起第三种行代替列方案,它的查询性能好,因为是读取一行数据。
但它也有许多缺点:
无法支持 SQL 所有功能,比如 force.com 的 SOQL 无法 select *、没有视图、不支持写入和更新数据,通过这个特点就能识别出使用这个方案的产品,这类产品虽然看起来很像在用传统数据库,也支持使用 SQL,但这个 SQL 一定是受限的。 数据泄露风险高,因为所有租户的数据都存在一张表里,而数据库都不支持行级别权限的账号,所以意味着所有租户其实共享一个数据库账号,只要有某个功能的查询漏了加租户过滤就能查到所有租户数据。相比之下前面提到的原生表及文档型数据库方案都能直接使用数据库自带的账号进行有效隔离。 一些数据库高级字段难以支持,比如坐标数据、二进制类型等,只能用单独的表存,导致了查询开销。 整体实现成本高,其中很多细节需要处理好,比如保证数据一致性,因为为了实现唯一性、索引等功能需要拷贝数据,更新的时候要同时更新。
爱速搭中没有实现这个方案,我们曾经考虑过但后来放弃了,我认为这个方案虽然很适合 SaaS 类的低代码产品,但它的用户定位比较尴尬,一方面是有一定复杂度导致不能做到零代码平台那样的易用性,另一方面是有不少限制导致专业研发不喜欢,所以最终是两边都不讨好,这种产品想做成需要依赖广泛使用的平台。
因此 Salesforce 才能做成,而国内类似情况我能想到的唯一成功案例是微信小程序,尽管有很多限制,但因为微信广泛使用,所以才成功了,如果是一个独立的小程序平台肯定没人用。
这里说一段小历史,在十几年前,当时云计算领域最先推出的是谷歌 2008 年发布的 App Engine,这是谷歌的第一个云产品,而当时类似 AWS EC2 那样的虚机产品国内都还没有,毕竟 KVM 也才刚发布。
如果你当时问云计算的专家,云计算的未来是 App Engine 还是虚拟机,我听到不少专家的回答是 App Engine,因为这看起来更有前景,你只需要写代码,不用操心运维,平台会自动水平扩展,这才是云该有的样子,当时国内不少公司都推出了类似产品。
但 13 年后的今天,国内 App Engine 平台几乎都关闭了,而虚机不但是主流,还更进一步出现了物理机产品。这个元信息方案给我的感觉和当年 App Engine 很像,看上去能完成增删改查的简单应用,但如果深入就发现缺少很多功高级功能,导致两边不讨好:
技术薄弱的开发者不会用,比如因为 App Engine 是分布式部署,导致上传文件不能放本地,必须改成对象存储,所以没法直接用 WordPress 没法用,对于小站长来说还不如用虚拟主机。 对于有技术实力的开发者,又会觉得平台能力受限,不利于自己后续发展,比如谷歌的 App Engine 直到 2019 年才支持 WebSocket。
整体而言我不看好这个方案在国内的发展。
存储的实现方案 5:使用单文件
这个方案目前只在「仿 Excel」的零代码平台中见过,它和 Excel 类似,数据全都放一个文件里,查询过滤完全靠前端,优点是:
实现简单,部署成本低,因为表的存储就是单文件。 容错性强,数据类型都是靠前端处理的,不会出现存数据库导致。
缺点是:
如果要支持行列级别权限校验,还得在后端实现一遍过滤,而每次都加载一个巨大的 JSON 文件对服务器内存有较高要求。 难以支持事务操作,尤其是支持行级别的操作。 目前看十万级别数据处理可以只靠前端,但再大量的数据就不合适了,一次性加载太多对带宽和浏览器内存要求比较高。 只能当成 Excel 的替代品,数据是孤岛,不能直连外部数据库。
这个方案比较特殊,主要工作量在前端,有大量细节体验优化,在爱速搭中没实现,后续可能会考虑。
2、后端业务逻辑的实现
说完了存储,接下来是第二个问题:如何实现后端业务逻辑?
前面提到过代码难以图形化,这在后端也是一样的,因此大概有这几种方案:
逻辑图形化,这个目前看各个产品效果都不太理想,看上去还不如代码易读。 固定行为,主要是对数据存储提供增删改查操作。 支持 JavaScript 自定义。 简化 DSL 语言,类似 Excel 中的公式。
前面两种方案之前介绍过了,这里只讨论后面两种。
后端支持使用 JavaScript 是种常见做法,主要原因是 JavaScript 引擎容易被嵌入,而且启动速度快,了解的人多,比如市值超过 1200 亿美元的 ServiceNow 后端自定义业务逻辑就是基于 Rhino 引擎实现的。
简化 DSL 语言的主要是使用场景是做表达式计算,比如在流程中的分支流转规则判断,需要用户能自定义表达式,比如金额大于多少换成总监审批,这时用公式会比 JavaScript 会更简单,因为系统可以自动转换数据类型,并自动处理异步函数的调用,目前爱速搭的流程里有实现,同时在 amis 里也提供了。
另外除了上面提到这四种,我们在爱速搭中还设计了另一个方案:执行树,它长这个样子:
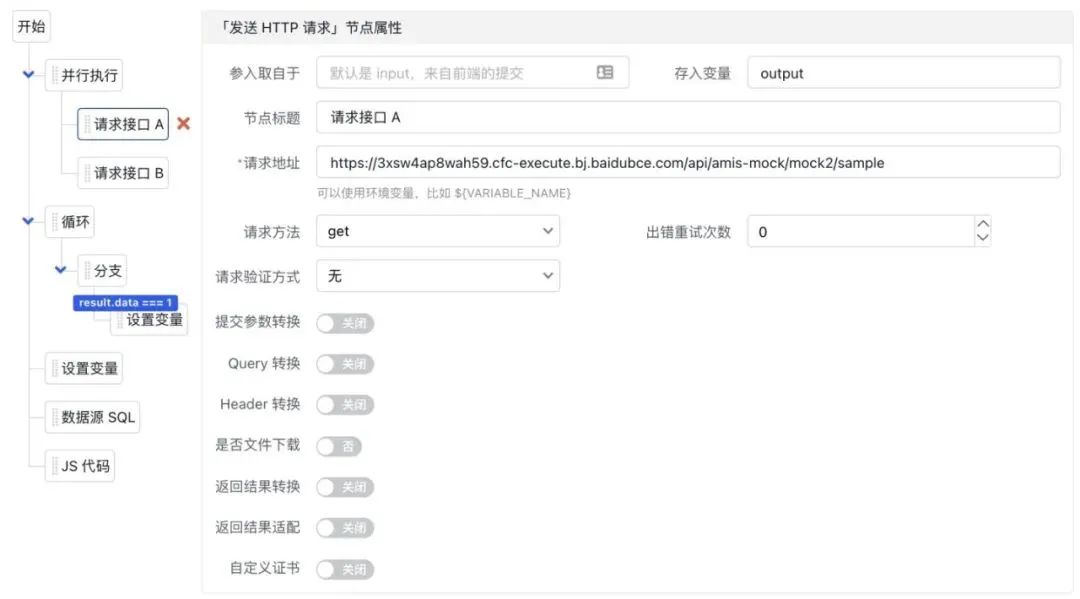
左侧是树形结构,右侧是点中某个节点时的参数配置,左侧的树形结构其实是直接参考代码的树形结构:
默认从上往下执行,但有个特殊的「并行执行」节点可以并行执行。 对于循环和分支会创建子节点,并且子节点可以无限嵌套,相当于代码里的花括号。 节点可以折叠,这样就能先将复杂的逻辑折叠起来方便看主流程,这是使用图模式难以实现的,在图里收起后无法修改其它节点的位置,导致空出一块。
为了方便实现简单逻辑处理,我们还增加了 JavaScript 节点和 SQL 节点。
但执行树这个方案目前的定位是聚合多接口,将多个后端接口数据合并后给前端,类似于 BFF 的作用,我们推荐复杂的后端逻辑还是用 Spring Boot 吧,成熟稳定且好招人。
3、流程的实现
接下来是第三个问题:如何实现流程?这是大部分低代码平台标配的功能,流程的逻辑不像普通代码那么抽象,因此适合用可视化编辑。
流程可视化存在很久了,著名的 BPMN 规范最早版本在 2004 就发布了,因此大部分产品都会支持 BPMN 2.0 规范。
但 BPMN 本质上是一种图形规范,它的最大作用是给事件、动作及分支条件这些抽象概念分配了不同的形体,使得熟悉这个规范的用户有了共同语言。
BPMN 不能解决平台锁定问题,在一个平台开发的流程无法直接迁移到另一个平台。
流程的核心是实现流程流转引擎,以爱速搭为例,流程可视化布局后最终存储的格式是有向图,比如下面这个最简单流程:

简化后的存储数据格式是两条连线和三个节点:
{
"lines": [
{
"id": "d4ffdd0f6829",
"to": "4a055392d2e1",
"from": "e19408ecf7e3"
},
{
"id": "79ccff84860d",
"to": "724cd2475bfe",
"from": "4a055392d2e1"
}
],
"nodes": [
{
"id": "e19408ecf7e3",
"type": "start",
"label": "开始"
},
{
"id": "4a055392d2e1",
"type": "examine-and-approve-task",
"label": "审批节点"
},
{
"id": "724cd2475bfe",
"type": "end",
"label": "结束"
}
]
}
流程流转算法的核心就是根据当前状态和这个有向图,判断出下个节点是什么,然后执行那个节点的操作。
同时因为主要面向的是审批流,所以还需要处理审批场景特有的逻辑,比如有的审批是全部通过才算通过,有的审批是只需要一个人通过就算通过,还有回退、加签等功能,并处理各种边界条件,比如找不到审批人的时候怎么办。
虽然目前业界有开源的流程引擎,但这些引擎大多是面向代码开发,不太好改造成平台模式,因此在爱速搭里自己实现了流程引擎,这样才能更好定制功能。
7 低代码平台未来会怎样?
前面提到了各种低代码的实现方案细节,这里抛开具体细节,来整体讨论一下未来低代码平台会怎样。
最开始提到过低代码唯一不可缺少的功能是可视化编辑,这是低代码的最大优势,但是低代码的最大缺陷,因为可视化难以表达复杂的抽象逻辑,因此长远看低代码并不会在所有领域取代专业开发,更多是和专业开发配合来提升效率。
从技术方案上看低代码平台主要有两个方向:
1、偏向零代码的方案,它的特点是:
易用性强 灵活性差 适合小公司,客单价低,但客户数多 标准化程度高,导致功能都很类似,将面临同质化竞争 产品使用简单,客户支持成本低
2、偏向专业开发的方案,它的特点是:
易用性弱 灵活性强 适合中大型公司,客户数少,但客单价高 标准化程度低,每家都有各自的特点 产品使用复杂,客户支持成本高
未来会怎样呢?我的想法是:
偏向零代码方案,因为功能类似支持成本低,可以同时支持很多用户,容易出现赢者通吃的情况,但由于 toB 领域发展速度慢,所以还是有不少机会。
可以类比 BI 数据可视化产品,BI 这个领域的软件出现至少 20 年了,比如 Qlik 1994 就发布了,现在市面上的 BI 软件在基本功能上都大体相同,但没有哪个产品占据绝大部分市场份额,我们的 Sugar 产品虽然两年前才推出,但依然得到了不少优质客户,所以只要产品优秀就有机会。
零代码产品有好几种形态,和去年一样,我更看好「在线 Excel」,因为既然是面向非开发者,类 Excel 是上手成本最低的方案,而且这一年来许多「在线 Excel」的产品都加上了低代码功能,比如 Airtable 的 Interface,在功能上和表单驱动的零代码越来越接近了。
而偏向专业开发的方案,因为支持成本高导致没法同时支持很多客户,因此更难出现一家独大的情况,而偏向研发会导致细节方案有很多区别,没太多可比性。
以我们的爱速搭为例,目前产品选择的方案是偏向专业开发,现有客户都是知名企业,但也导致了支持成本很高,因为客户问的问题都很专业,大多只有核心研发才能解答,在功能方面我们的特点是前端使用了我们开源的 amis 框架,这个其它家是不会提供的。
8 总结
前面字太多了,总结一下主要观点:
低代码都是一种「声明式」编程,因为只有声明式才能可视化编辑,而可视化编辑是低代码唯一不可少的功能。 低代码的优缺点其实来自于「声明式」本身。 编写代码是一种抽象思维,因此并不适合可视化,导致低代码只能面向特定领域,复杂应用需要和专业开发配合。 前端界面的 HTML+CSS 可以认为是一种低代码 DSL,因此界面的低代码比较容易实现,只需要在 HTML+CSS 基础上抽象一层。 后端存储的低代码有几种方案,但没有哪个方案是完美的,它们都有各自的优缺点,这将决定一个低代码平台的适用范围,建议在选型时重点关注。
9 在了解原理之后
前面介绍了各种低代码实现原理,看起来都不难,但真正要实现还需要大量细节工作,以我们的 amis 为例,从 2015 年启动至今一直在持续更新,下面是 amis 开源这两年半来的提交历史[2],基本除了春节和国庆之外都在提交:
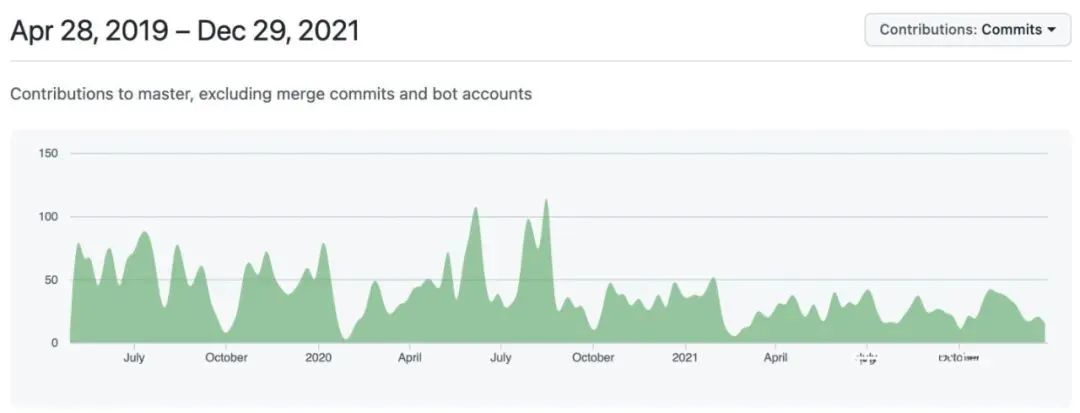
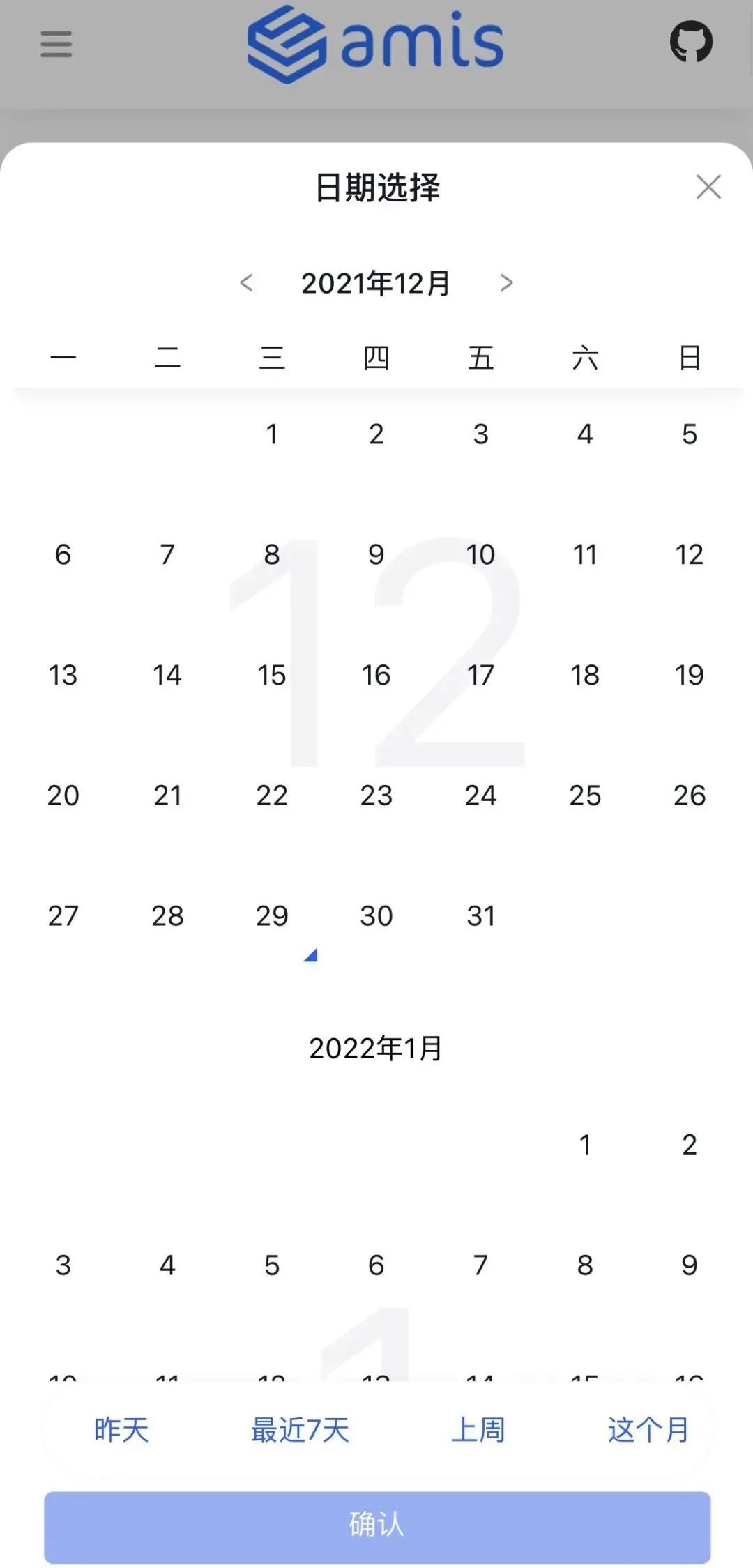
但今天 amis 现在仍然有大量功能要做,比如本周将发布的 1.6.0 版本终于开始初步增强移动端 UI,下面是新版移动端日期选择:
除了无尽的功能要加,还有许多基础工作要做,比如组件单元测试覆盖率只有 40%,此刻还有 360+ issues 要处理,感谢阅读到这,有什么问题欢迎留言交流,我要去处理 issue 了……
作者介绍
吴多益,百度智能云主任架构师,超过14年从业经验,参与过百度贴吧、搜索、空间等产品的研发,曾长期负责百度前端基础技术团队,从2015年起开始探索低代码方向,并开源了前端低代码框架amis,目前在百度智能云负责低代码产品爱速搭的研发。
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦😀
