
架构揭秘:「京东白条」的数据架构进化之路
最近小伙伴在讨论单体到微服务架构中数据这块如何演进,相信这篇能给大家带来启发。
来源:SphereEx
链接:https://segmentfault.com/a/1190000041107436
京东白条的快速发展满足了当前人们日益增长的消费需求。在京东商城上用京东白条来支付,已经成为一大批用户的消费习惯,更是在某种意义上成为了京东对外的『标签』。而作为一家互联网金融消费平台,京东白条的后台技术团队更是不容忽视的存在。而其也正是支撑京东白条自 2014 年初上线伊始,至今服务数亿用户的最终根源所在。正是京东白条技术团队多年的努力,才造就了当前京东白条的『土生土长』,但具有京东白条特色的金融级数据库选型方法论。
当京东白条的金融类业务启动时,现任京东白条研发负责人张栋芳,虽然预料到了其数据体量的大幅度增长,却没有想到这种增长将导致数据库选型方面的一系列变化,以及对数据库未来发展模式的启发。
作为京东科技旗下的杀手级金融消费应用,今天的京东白条已经成长为服务数亿用户、日均产生巨额流量的庞大金融生态。在业务和数据量飞速增长的同时,京东白条后台的研发人员,也在紧张的焦头烂额中....
这一点,完美契合了京东白条后台数据架构的成长过程。
1、技术的保质期:从 MySQL 到 NoSQL 再到 DBRep
对于技术人而言,没有永远正确的技术,只有最适合于当下的技术选型。
京东白条业务诞生之初正是互联网金融与消费行业的高速发展期,经历这些年的发展,从草根走向专业,从弱小走向规模,从分散走向统一,从杂乱走向规范。京东白条的发展,正是一步步见证了国内互联网消费金融产业的快速迭代。
同样,京东白条的技术选型历程,也可作为国内互联网消费金融产业发展过程的一个缩影。
从技术架构的角度来看,并没有绝对的好与不好,需要放在彼时的背景下来看,要考虑业务的时效价值、团队的规模和能力、环境基础设施等等方面。只有架构演进的生命周期适时匹配好业务的生命周期,才能发挥最好的效果。
2014~2015
Solr + HBase 的方案解决了核心、非核心业务系统对关键数据库的访问问题,Solr 作为被检索字段的索引,HBase 用作全量的数据存储。
通过 Solr 集群分担部分读和写的业务,缓解核心库的压力; Solr 扩展体验上欠佳,对业务也存在较大的入侵。
2015~2016
引入 NoSQL 方案,业务数据以月份进行分表存储在 MongoDB 集群中,阶段性满足了结算处理场景中海量数据导入导出的需求。
查询热点数据效率高,非结构化的存储方式易于修改表结构; 依然面对着扩展差、对业务入侵强的局面,而且耗内存。
2016~2017
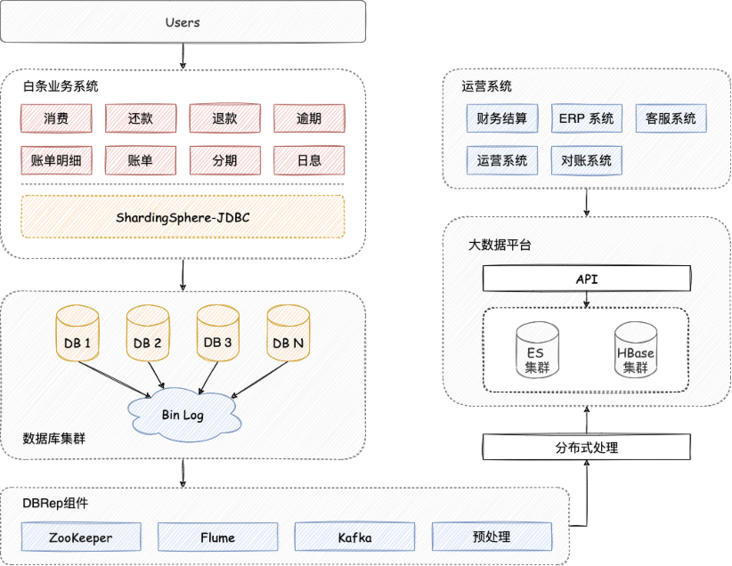
随着业务快速发展,数据量突破百亿大关,此时 MongoDB 面临着容量和性能的双重考验。京东白条大数据平台通过 DBRep 以 MySQL Slave 的形式采集变动信息并存储到消息中心,最后落盘到 ES 和 HBase 中。
该方案具有较强的数据实时性,扩展性良好; 基于业务框架的数据分片难以降低代码维护成本。
2、为了让你能够更痛快的剁手,他们先『分解』了自己的后台架构
网购,贵在手速,但也在于钱包的厚度。京东白条的诞生就是为了解决用户钱包的厚度问题。如今,京东白条也打起了“闪电战”。为了保证用户在消费过程中的体验,后台数据库的稳定性与规律性,就成为了京东白条技术侧亟待考虑和平衡的问题。
为保证业务系统在数据激增情况下始终能保持高效运行,京东白条技术团队在设计初期使用了数据分片数据架构,发挥极致性能的同时也兼顾代码的可控性,采用基于应用框架的数据拆分方案完成了数据拆分工作。
其实说来说去,本质上就是一个问题,即随着产品的升级迭代,早期的解决方案逐渐演变为了阻碍今天前进的绊脚石。通过业务框架实现的数据分片方案导致业务代码复杂度增加、维护成本不断攀升,紧耦合的弊端逐渐显露,应用每次升级都需要投入较多的精力对分片做相应调整,研发人员难以专注于业务本身。
于是,解耦成了京东白条技术突围的唯一关键。在京东白条而言,主要从以下这四个方面开始解耦:
数据架构解耦,降低架构之间的耦合度,确保不会因单独业务线变更而导致多个后端架构的调整; 技术架构解耦,简化业务系统升级工作所带来的复杂研发流程; 业务关系解耦,需要让用户在使用过程中每个动作都不受影响,不另外产生新的学习成本,为系统提供良好的扩展能力,从容应对“618”和“11.11”等平台大促活动; 研发流程解耦,解放后端研发生产力,减少业务代码的复杂度。
因后台数据库与业务之间的耦合度过高,为整个业务的发展埋下了增速放缓的隐患。面对如上诉求,京东白条技术团队经权衡后开始考虑使用成熟的分库分表组件来承担这部分工作,让业务系统升级和架构调整不再复杂。但京东白条业务体量巨大,是名副其实的金融级高并发、海量数据的业务场景,因此在选择分库分表组件时应具备以下 4 个特点:
产品成熟稳定。只有成熟且稳定维护的产品,才能够给京东白条这样一款体量的金融产品予以稳定性的保证。使用数据分片来进行架构解耦,本身就是为了确保稳定性; 极致性能表现。金融场景下的应用,对于数据响应、实时反馈等性能的要求非常高。尤其在交易这种敏感且特殊的场景下,对于性能的表现,一点也不能马虎; 处理海量数据。京东白条需要处理海量的用户数据,尤其在“618”、“11.11”等大促节日下,面对蜂拥而至海量交易数据与请求,要能够在短时间内快速处理; 架构灵活扩展。业务灵活多变是当前互联网产品的共性。
对此,京东白条从多个方面考虑自研框架与成熟分库分表中间件 ShardingSphere 优劣性,性能对比图如下:
| 基于自研框架分片 | 基于 ShardingSphere 分片 | |
|---|---|---|
| 性能 | 高 | 高 |
| 代码耦合度 | 高 | 低 |
| 业务入侵程度 | 高 | 低 |
| 升级难度 | 高 | 低 |
| 扩展性 | 一般 | 良好 |
最终,京东白条选择采用 Apache ShardingSphere 来进行金融级别的数据库分片任务。
3、场景趋于融合,但数据库却无法相容:Apache ShardingSphere 解决方案
京东白条采用 Apache ShardingSphere-JDBC 解决方案处理在线应用。ShardingSphere-JDBC 是 Apache ShardingSphere 的第一款产品,它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingSphere-JDBC 的以下特点能够很好地满足白条业务场景:
产品成熟: 经数年打磨产品成熟度高,且社区活跃; 性能良好: 微内核、轻量化的设计,性能损耗极小; 改造量小: 支持原生的 JDBC 接口,研发工作量小; 扩展灵活: 搭配使用迁移同步组件轻松实现数据扩展。
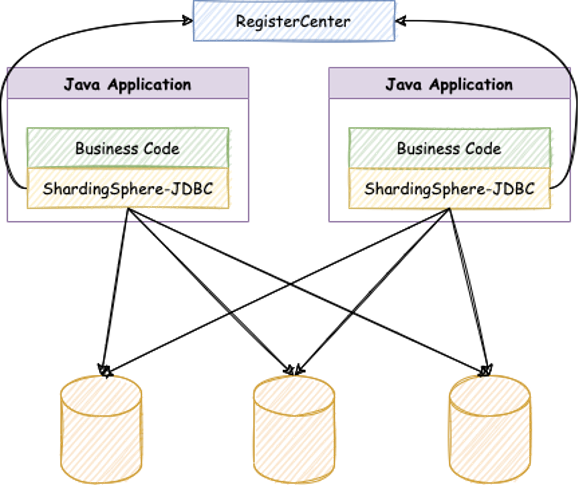
经内部大量系统性验证之后,Apache ShardingSphere 成为了京东白条数据分片中间件的首选方案,2018 年底正式开始对接。
产品适配
为全面支撑白条业务、提供更好的业务体验,Apache ShardingSphere 在京东白条业务落地过程中对产品的功能和性能方面进行了更多的支持和提升,产品再一次经历典型案例的打磨。
升级 SQL 引擎
白条的业务逻辑非常复杂且庞大,多样化场景的需求对 SQL 的兼容程度有着较高要求,Apache ShardingSphere 重构了 SQL 解析模块,并支持了更多的 SQL。经两团队通力合作,京东白条业务与 Apache ShardingSphere 相结合的各项指标满足预期,性能与原生 JDBC 几乎一致。
关于对接过程中的问题详情及方案,请通过《Apache ShardingSphere 对接京东白条实战》一文来了解。
业务割接
Apache ShardingSphere 使用定制化 HASH 策略对数据进行分片,有效避免了热点数据问题,拆分后的数据节点数达近万个,整个割接过程大约持续了 4 周左右的时间。
DBRep 读取数据,通过 Apache ShardingSphere 将数据同步至目标数据库集群; 两套集群并行运行,数据迁移后再使用自研工具对业务和数据进行校验。
DBRep 是 ShardingSphere-Scaling 产品设计的基石,Scaling 具备的自动化能力为后续的迁移扩容工作提供了更多的便利。
配好业务的生命周期,才能发挥最好的效果。
价值收益
简化升级路径
通过架构解耦,业务系统升级所涉及技术栈得到有效缩短,研发团队不再需要关注分表设计,精力全部聚焦于业务本身,升级路径得到大幅度优化;
节省研发力量
引入成熟的 Apache ShardingSphere 无需重新开发分表组件,在简化业务升级路径的基础上节省了大量研发力量;
架构灵活扩展
搭配使用 Scaling 同步迁移组件从容面对“618”和“11.11”等大型活动,系统灵活扩容。
4、面对新的不稳定业态,需要相对稳定的标准来应对
如何理解不稳定,并平衡这种不稳定。
随着数据的重要性日益凸显,以及终端场景领域的持续细化,业务线『开枝散叶』已是常态,市场上的数据库产品层出不穷。某种意义上,发展了许多年的京东白条,早已不再是当年的数据体量,其金融消费场景已经是一个相对稳定和成熟的场景而言,京东白条仍然是一个快速生长的互联网巨量头部产品,用户和数据体量还远没有达到接近天花板级别。
这也意味着,随着业务数据量的增长,未来京东白条还需要经历多次具备『阵痛期』的架构转型。而每一次转型,无疑都是一次冒险,这对于追求稳定和体验的金融级产品而言,无疑是需要慎重考虑的。
而在现阶段通用的数据架构体系下,整个行业都在经历一种新的不稳定业态。面对这种不稳定的业态,京东白条需要一种相对稳定的标准和生态,来『对抗』这种不稳定的趋势。基于此,张栋芳提到了 Database Plus 的概念。
2018 年,Apache ShardingSphere 作者张亮就曾提出过 Database Plus 的概念。彼时数据库已经呈现出碎片化的趋势,企业在后端数据库管理层面,已经开始产生不小的成本。如果能够在数据库上层重新建设起具备统一管理底层数据的中间层生态,对于企业以及工程师而言,都会极大提高研发与管理的效率。
所以,Sharding-JDBC 在京东内部,正式升级为 ShardingSphere,寓意打造一个新的生态,并在张亮和社区需求的引导下,逐步确立起了 Database Plus 的发展方向。伴随着近日 Apache ShardingSphere 5.0.0 正式版的更新,Database Plus 理念已正式在 Apache ShardingSphere 生态中得到践行。
目前,Apache ShardingSphere 通过可插拔架构,已能够在数据库上层构建起一套全新的数据治理生态,如让传统关系型数据库同时具备水平扩展和数据加密的功能,或在传统关系型数据库的基础上单独打造分布式数据库解决方案等,而无需调整底层数据库架构。
而这种技术,无疑是应对数据库碎片化趋势的最好方案之一。 而对于未来数据库发展的理解,张栋芳认为,在多样化的数据库上层,构建起统一的数据管理平台,将数据库能力分布在中间层并实现可插拔化,追求功能与业务诉求的高度匹配,筛去冗余的能力,并能够在需要时进行快速变动,始终保证数据架构的整洁、专一。
5、事物终归需要回归到它的本质
从市场和用户规模来看,中国有着全球最广泛的互联网用户群体,产生着最大的数据体量,诞生了一系列成长最快速的互联网科技公司....但是与庞大需求所不匹配的是,国内数据服务市场却始终处于同质化竞争之下,没能有颠覆海外数据库巨头的产品出现。
张栋芳认为,各家厂商专注于各自的应用场景之下,缺少一个抬头环顾四周的过程。我们始终在谈新技术,始终在追求业务的最高效化。但对于一些需要实现“大象起舞”的金融、证券、制造、零售等领域而言,最新的技术不一定是最适合他们的,在现有技术基础上,提供增量能力的中间件,打造适配于当下业务场景的技术体系,而不是颠覆。
“事物需要回归它的本质。”对于数据治理方式而言,同样如此。
我今天跟大家的分享到这里。谢谢大家。
推荐阅读: