
实时数仓 | 京东计算架构演进之路
前
言
导读:初级工程师搞技术,高阶工程师搭平台。没有几个工程师天赋异禀,技术的差距,是认知的差距。谢邀!

从2004年开始,京东进军互联网线上化开始到至今,随着京东的高速发展,京东商城的订单量从万级到百万级、最终到达亿级。而对于实时的数据需求也是层出不穷,实时数仓、实时计算架构随着数据量的增长,不断进行革新与演进优化。
(1)订单量万级、百万级(以京东海外站为例)
在订单量万级、百万级别的时候,也存在不少实时的数据需求,比如:商家需要看看自己每天的成交量、老板需要看看整体的成交金额,以为后续的融资做准备。类似于现在很多的a、b轮创业公司数据体量。
解决方案:而此时为了节省更少的资源,减少更少花销。在实时架构设计上就需要尽量用更少的成本来解决这种问题。基于mysql的实时数据统计方案就比较适合了。
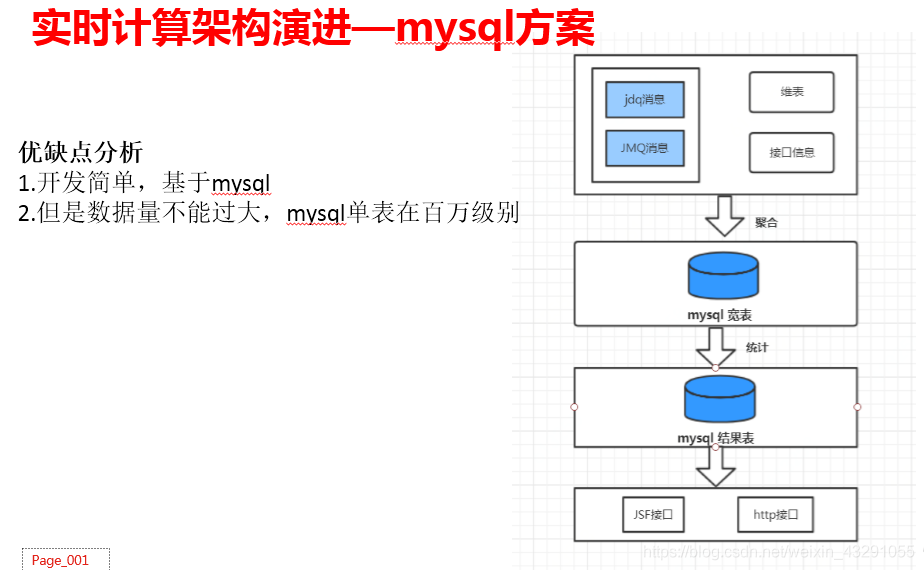
步骤:将线上业务系统数据实时同步到大数据中心(在mysql的基础上搭建了一套大数据架构),避免了Hadoop生态庞大复杂的体系。基于mysql数据宽表进行数据统计,将统计结果写到mysql指标结果表中,输出一些报表或者服务。详细步骤见下图。
架构优缺点:
(1)开发简单,基于mysql,同时避免hadoop生态复杂的体系,节省开销。
(2)数据量过大,查询和聚合性能较差,mysql单表量级在百万级别。
(3)在此架构中需要对mysql及其熟练,如何设计索引,如何进行查询统计优化。
(2)订单量亿级(以京东主站为例)
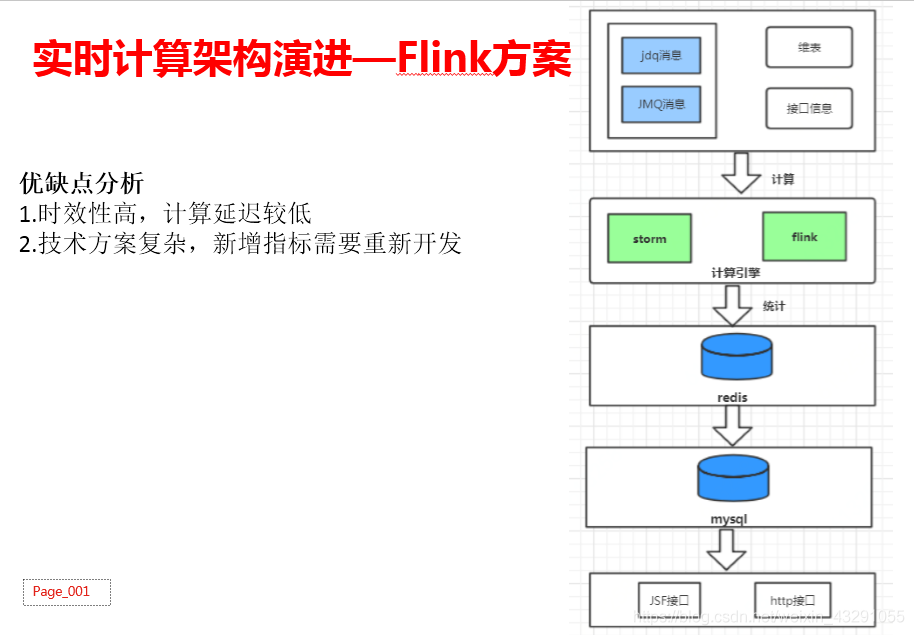
随着公司的发展,数据体量的增大,达到千万甚至亿级别时,基于mysql的数据统计方案已经完全没办法满足统计需求了,mysql查询也查不动了。基于此产生了一套新的技术方案:flink接kafka消息数据,直接进行指标计算,写入到redis里面,最后提供最外提供服务。详细步骤见下图。
架构优缺点:
(1)能够支撑亿级数据量的统计需求,对于大数据量友好
(2)时效性高,计算延迟较低
(3)技术方案相对复杂,新增指标需要重新开发,上线任务。
(3)订单量亿级(以京东主站为例)
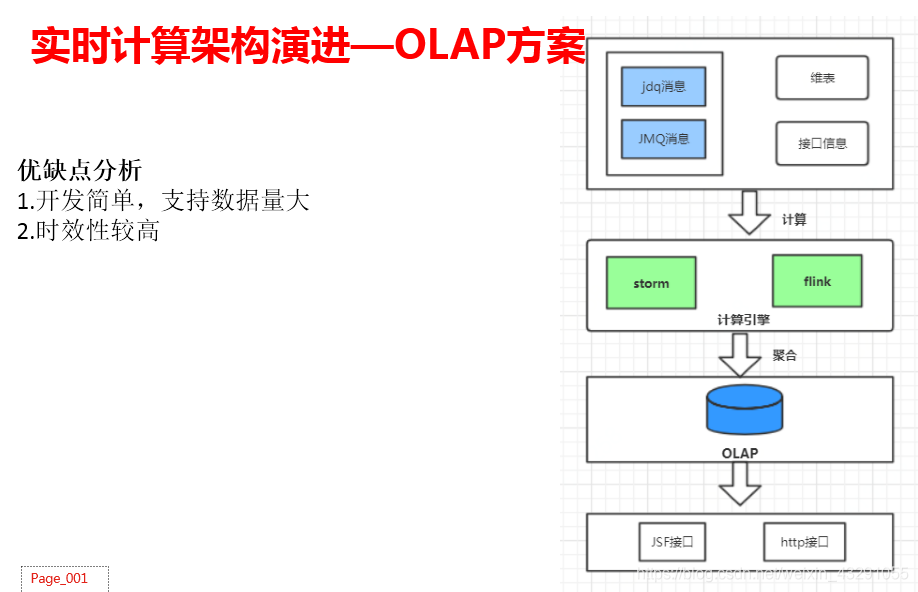
上述基于flink 直接指标计算的方案,优点非常明显,缺点也非常明显,如果新增指标,需要重新开发上线,对于频繁的业务需求变更,已经很难满足了,因此产生了基于OLAP的技术方案。Flink接kafka 消息,将明细数据写入到OLAP引擎(clickhouse、apache doris)当中,构建一张宽表,然后直接进行数据查询统计基于OLAP引擎,对于新增指标只需要新增不同的sql查询语句就能解决需求,而不用重新开发,提高了整体效率,能够应对业务的频繁变更。详细步骤见下图。
架构优缺点:
(1)能够支撑亿级数据量的统计需求,对于大数据量友好
(2)时效性较高
(3)开发简单,能够快速应对业务需求。
随着公司高速发展,数据体量的改变对于技术的选型也是不断进行变更的。只有了解不同的技术架构的优缺点,在合适的阶段选择不同的数据架构,才能够更好的服务于业务。同时根据自己所处的公司当前的发展状况,预估公司后续的发展,在技术架构选型上也是有前瞻性的。