
Python的Functools模块简介

模块中有什么?
functools模块是Python的标准库的一部分,它是为高阶函数而实现的。高阶函数是作用于或返回另一个函数或多个函数的函数。一般来说,对这个模块而言,任何可调用的对象都可以作为一个函数来处理。
functools 提供了 11个函数:
cached_property()
cmp_to_key()
lru_cache()
partial()
partialmethod()
reduce()
singledispatch()
singledispatchmethod()
total_ordering()
update_wrapper()
wraps()
在整篇文章中,我们将更深入地研究每个函数,并给出一些有用的示例。你可以在GitHub上找到文章中使用的代码片段。享受吧!
备注:本文基于Python 3.8.2 (CPython)。有些函数在CPython的早期版本中可能不存在。
functools中 的函数
@cached_property - 缓存实例方法
想象一下,你有一个大型数据集,为了分析它,你实现了一个保存整个数据集的类。此外,你还实现了一些函数来计算诸如手头数据集的标准偏差之类的信息。问题:你每次调用该方法时,它都会重新计算标准偏差—这需要时间啊!这就是@cached_property派上用场的地方了。
它的目的是将类的一个方法转换为一个属性,该属性的值只计算一次,然后被缓存为实例生命周期中的一个普通属性。其行为与内置的@property 装饰器[2]非常相似,只是增加了缓存过程。让我们来看一下来自Python文档中的例子:
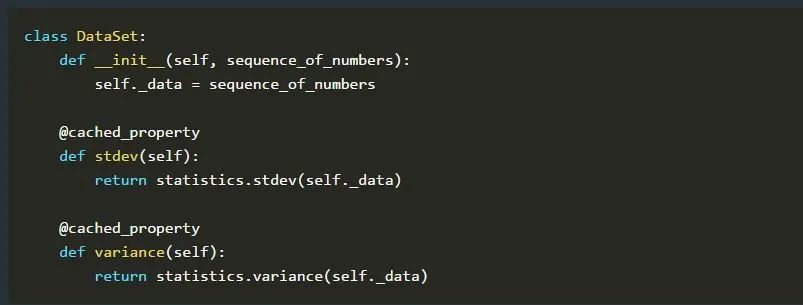
在当前的场景中,我们在一个DataSet实例中存储了一个(很大的)数字序列。此外,我们还定义了两个方法,分别用来计算标准偏差和方差。我们将@cached_property装饰器[3]分别应用于这两个函数,以将它们转换为缓存属性。这意味着值确实只计算了一次,然后就被缓存了。
备注:DataSet的每个实例都需要有一个带有不可变映射的__dict__属性。这是装饰器能够正确工作所必需的。
cmp_to_key() - 一个转换函数
在继续之前,我们首先需要理解比较函数和键函数之间的区别。
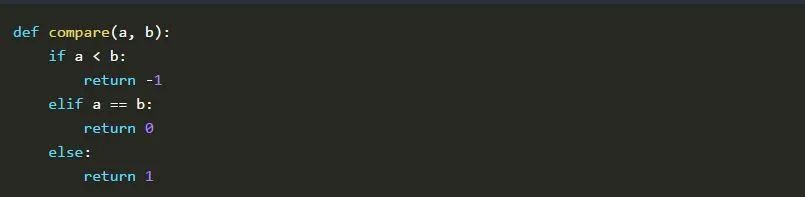
比较函数是任何可调用的对象,它会接受两个参数,比较它们并根据所提供的参数顺序返回一个数字。负数表示第一个参数小于第二个参数,零表示它们相等,正数表示第一个参数大于第二个参数。Python中的一个简单实现可能是这样的:
相反,键函数是一个可调用对象,它接受一个参数并返回另一个用作排序键的值。这个分组的一个突出代表是operator.itemgetter()键函数[4],你可能从日常的编码中已经了解了它。键函数通常会被提供给像sort()、min()和max()之类的内置函数。
实际上,cmp_to_key()会将一个比较函数转换为一个键函数。cmp_to_key()函数的实现是为了支持从Python2到Python3的转换,因为在Python2中存在一个用于比较和排序的名为cmp()的函数(以及一个双下划线方法__cmp__())。
@lru_cache() - 通过缓存增加代码性能
@lru_cache()是一个装饰器,它用一个记忆化的可调用对象来包装一个函数,这个可调用对象可以保存最近的maxsize次调用(默认值:128)。
备注:简单来说,记忆化意味着保存一个函数调用的结果,如果这个函数再次使用相同的参数被调用时,则返回该结果。有关更多信息,请参阅Dan Bader关于Python中记忆化的文章[5]。
如果你有昂贵的或I/O绑定的函数,而这些函数会被周期性地使用相同的参数进行调用,那么这一点特别有用。LRU缓存代表最近最少使用的缓存,指的是这样一个缓存,它会在条目达到最大大小时删除最近最少使用的元素。如果maxsize设置为None,则LRU特性会被禁用。
让我们来看两个例子。在第一个示例中,我们定义了一个函数get_pep(),它接受一个PEP编号(Python增强提案)并返回这个PEP的内容,如果该PEP存在的话。
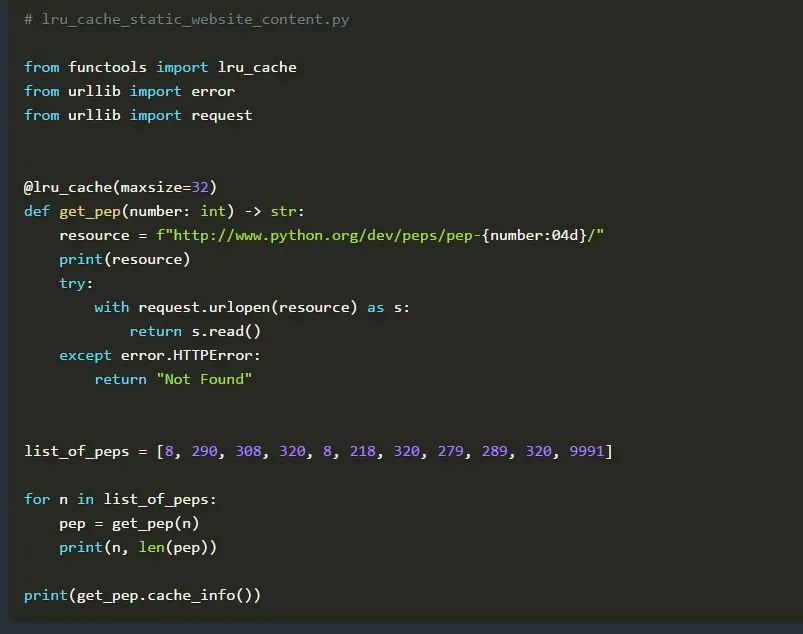
如你所见,我们将@lru_cache()装饰器添加到了函数中,并将缓存的最大大小设置为32。我们在使用许多PEP一个for循环中调用get_pep()。如果你仔细查看list_of_peps,你可以看到有两个数字在列表中出现了两次甚至三次:8和320。
一旦你执行了这个脚本,你就会发现所获取的PEP会在不打印出其URL的情况下立即出现,这些PEP我们已经从python.org请求过了。这是由于我们没有调用函数并再次从网站获取它,而是从我们的缓存中获取它。
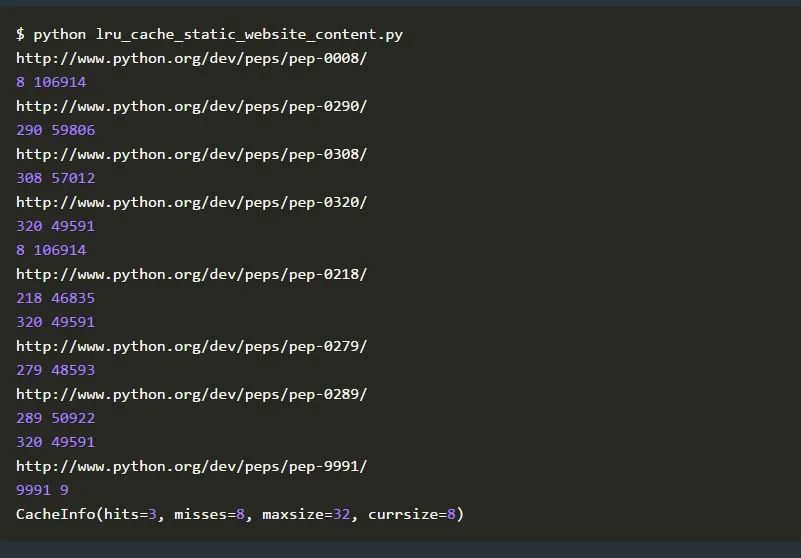
在这个脚本的最后,我们打印了get_pep()的缓存信息。这表明我们有三次命中,这意味着Python使用了一个缓存值三次,而不是再次调用该函数(一次使用数字8,两次使用320)。另外8次调用未命中,因此调用了函数并将结果添加到了缓存中。因此,最终的缓存由8个条目组成。
在第二个例子中,我们有一个想要加速的斐波那契数列的递归实现。
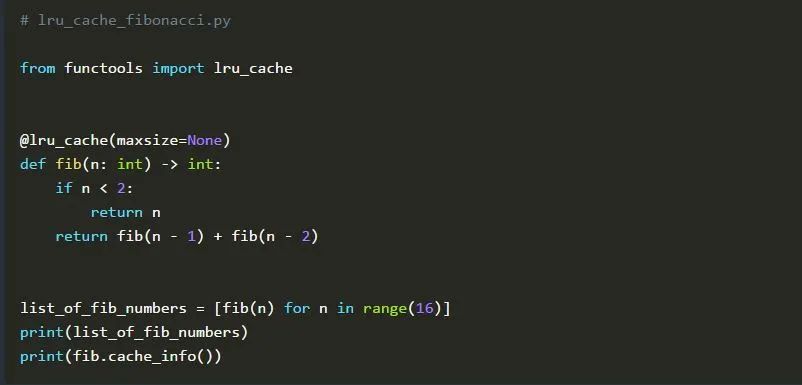
在这个例子中,我们计算了一个长度为16的斐波那契数列,并打印生成的序列以及fib()函数的缓存信息。

你可能会对缓存的命中次数和未命中次数感到惊讶。但是,请考虑以下情况:首先,我们计算n=0时的结果。因为我们的缓存中还没有条目,所以需要计算结果,这将使未命中增加1,并导致hits=0 和 misses=1。当你以n=1调用fib()时,又会出现这种情况。接着,fib()会被以n=2调用。我们通过计算n=1和n=0的结果并将它们相加来递归地计算结果。我们已经计算了这两个结果,所以我们可以从缓存中获取它们。因此,我们只有一个新的未命中,因为我们还没有n=2的条目。这个过程会一直持续到所有16个n都被传递给fib(),最后的结果只有16次未命中。
你想知道在本例中我们使用@lru_cache()节省了多少时间吗?我们可以使用Python的timeit .timeit()函数来测试它,这个函数会向我们展示一些不可思议的东西:

通过使用 @lru_cache(),fib()函数快了约100000倍-哇偶!这绝对是一个你想记住的装饰器。
@total_ordering - 通过使用装饰器来减少代码行数
用Python编程通常需要编写自己的类。在某些情况下,你希望能够比较该类的不同实例。根据你想要比较它们的方式,你最终可能会实现像__lt__()、__le__()、__gt__()、 __ge__() 或__eq__() 这样的函数,以便能够使用相应的<、<=、>、>=和==操作符。另一方面,你可以使用@total_ordering装饰器。这样,你只需要实现一个或多个丰富的比较排序方法,这个装饰器就会为你提供其余的方法。此外,我也建议你定义 __eq__()方法。
假设你有一个Pythonista类,你希望能够按字典顺序对它们进行排序。要做到这一点,你需要实现丰富的比较排序方法。但是,我们并没有实现所有这些方法,而是只实现了__lt__()方法和__eq__()方法。通过使用@ total_ordering修饰符,其他方法可以被自动定义。
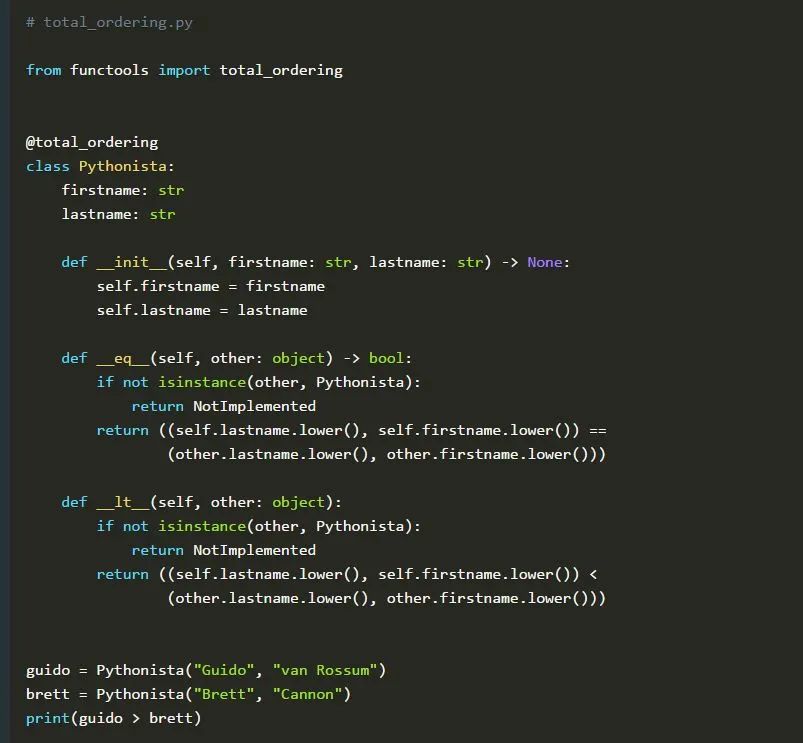
执行该脚本将打印出True,因为c在v之前。注意,尽管我们没有显式地实现__ge__(),但我们也可以使用>操作符。
如果希望根据不同的属性比较实例,@total_ordering装饰器是一种减少代码行数和调整代码的位置的好方法。但是,使用@total_ordering装饰器会增加开销,从而导致执行速度变慢。此外,派生的比较方法的堆栈跟踪更为复杂。因此,如果你需要非常高性能的代码,你就不应该使用该装饰器,而应该自己去实现所需的方法。
partial() - 简化签名
使用partial()你可以创建partial对象。这些对象的行为类似于传递给partial()的函数,该函数使用提供给partial()的(关键字)参数进行调用。因此,与原始函数相比,新创建的(partial)对象具有一个简化的签名。
这里是一个例子:
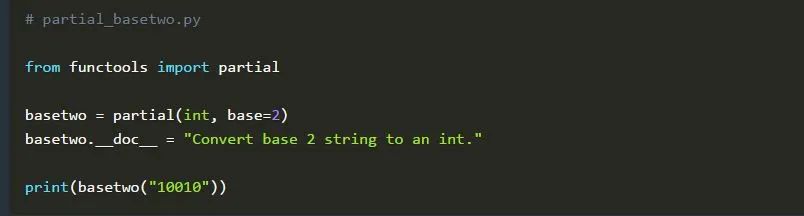
我们基于内置的int()函数创建了一个partial对象。在本例中,我们提供base=2作为关键字参数。因此,新创建的basetwo对象的行为就像我们用base=2调用int()一样。但是,我们仍然可以通过向base2提供一个base参数来覆盖这种行为。因此,执行basetwo("10010", base=10)计算的结果与int("10010")相同。
我们来看另一个例子。
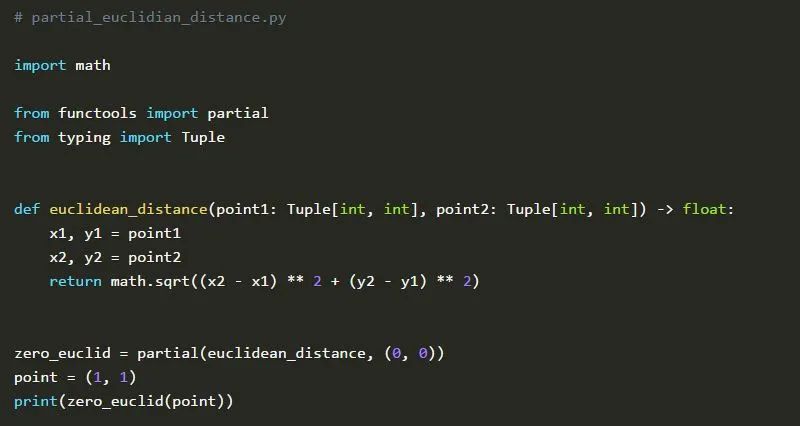
这个函数会计算二维空间中两点之间的欧氏距离。我们可以创建一个partial对象,它只接受一个参数(一个点)并计算我们所提供的点与点(0,0)之间的欧式距离。
partialmethod() - 方法的partial()
partialmethod()是一个函数,它会返回partialmethod描述符。你可以将它看作方法的partial()函数。这意味着它不是可调用的,而只是定义新方法的一种方式。我非常喜欢Python文档[6]中的示例,所以我们来看看它。
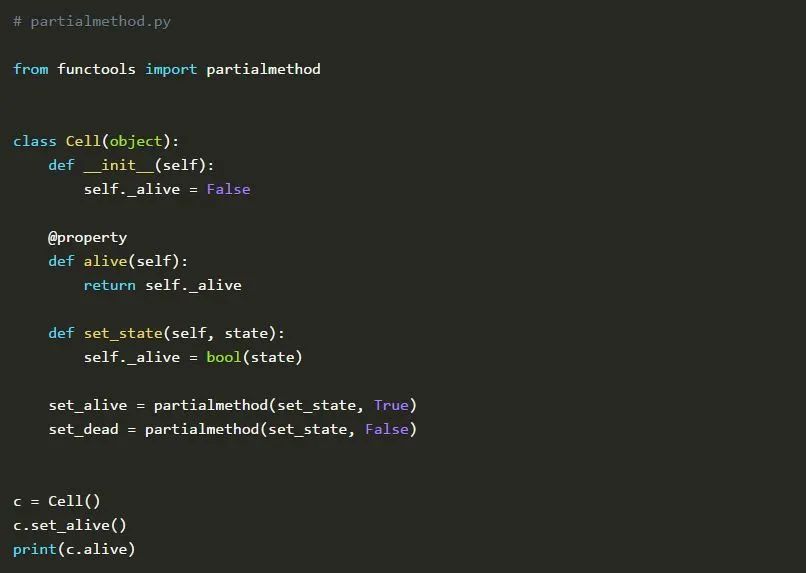
我们定义一个表示单个单元格的类Cell。它有一个alive属性和一个将alive设置为True或False的实例方法set_state()。此外,我们还创建了两个partialmethod描述符set_alive()和set_dead(),它们会分别用True和False调用set_state()。这允许我们创建Cell类的一个新实例,调用set_alive()将该单元格的状态更改为True并打印出该属性的值。
reduce() - 基于多个值计算单个值
假设你有一个由数字组成的可迭代对象,并希望将其缩减为单个值。在本例中,结果值是所提供的可迭代对象的所有元素的和。实现此目的的一种方法是使用reduce()。

如你所见,我们定义了一个包含数字1到5的列表。我们通过以operator.add()作为第一个参数,以该列表为第二个参数调用reduce()函数来计算这个列表中所有元素的和。当然,你也可以使用内置的sum()函数,但是如果你想计算所有元素的乘积呢?你惟一需要更改的是将operator.add()函数替换为operator.mul() - 搞定!
@singledispatch - 函数重载
根据定义,@singledispatch装饰器会将一个函数转换为一个单分派泛函数。在@singledispatch的情况下,分派发生在第一个参数的类型上。
备注: 泛函数是由多个函数组成的函数,这些函数为不同的类型实现了相同的操作。在调用期间应该使用哪个实现由分派算法[7]决定。
备注: 单分派是泛函数分派的一种形式,其中,实现是基于单个参数[8]的类型进行选择的。
简单来说,@singledispatch允许你在Python中重载函数。让我们以一个例子来说明它。
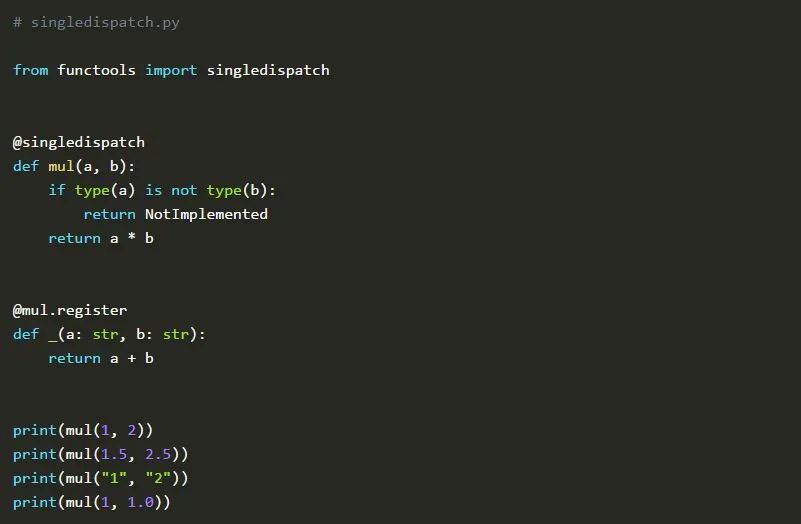
在这个例子中,我们定义了一个函数mul(),它接受两个参数并返回它们的乘积。然而,在Python中,两个字符串相乘会引发一个TypeError。我们可以通过注册_()函数来提供一个补丁。执行脚本后的结果是:

@singledispatchmethod - 方法重载
@singledispatchmethod 装饰器解决了与@singledispatch装饰器相同的任务,只不过它是针对方法的。
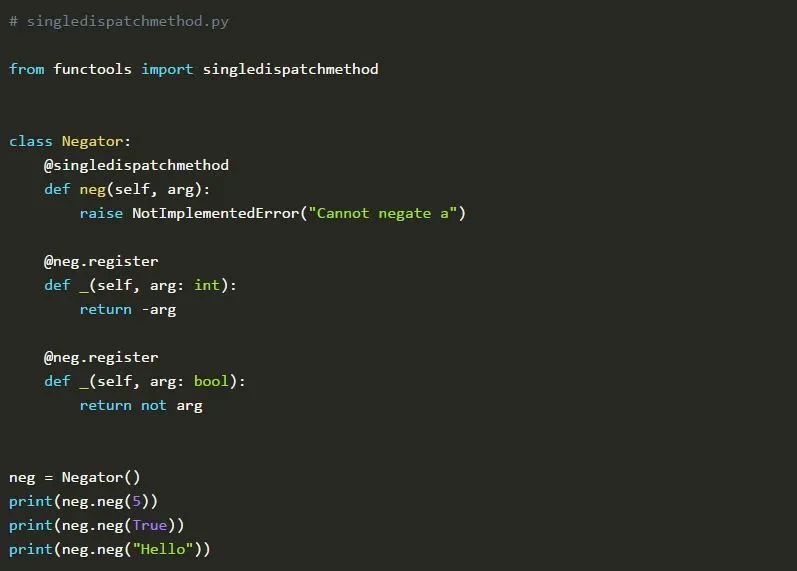
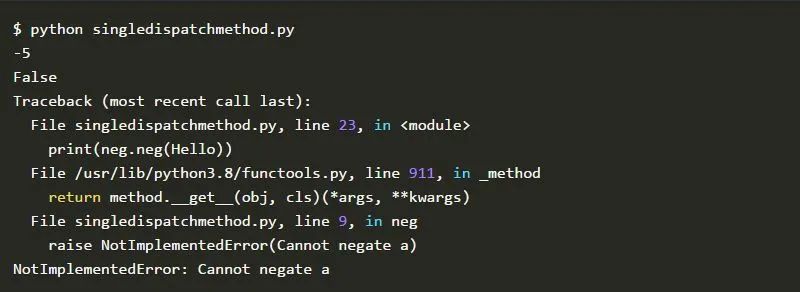
Negator类有一个名为neg()的实例方法。在默认情况下,neg()函数会引发一个NotImplementedError。但是,对于整数和布尔类型,该函数会被重载,并在这些情况下返回否定。执行脚本后的结果是:
update_wrapper() - 隐藏包装器函数
update_wrapper()函数背后的思想是以一种方式更新一个包装器函数(顾名思义),使其看起来像包装后的函数。为了实现这一点,update_wrapper()将包装后的函数__module__, __name__, __qualname__, __annotations__和 __doc__赋给包装器函数。此外,它还会更新该包装器函数的__dict__。
让我们以一个实际的例子看一下@wraps装饰器。
@wraps - update_wrapper()的便捷函数
@wraps是一个装饰器,它充当一个调用update_wrapper()的便捷函数。确切地说,它与调用partial(update_wrapper, wrapped=wrapped, assigned=assigned, updated=updated)是一样的。在阅读了关于update_wrapper()和@wraps的技术细节之后,你可能会问自己我们为什么需要隐藏我们的包装器函数。
下面的代码片段定义了一个装饰器@show_args。它会在函数自身被调用之前打印出用来调用该函数的参数和关键字参数。
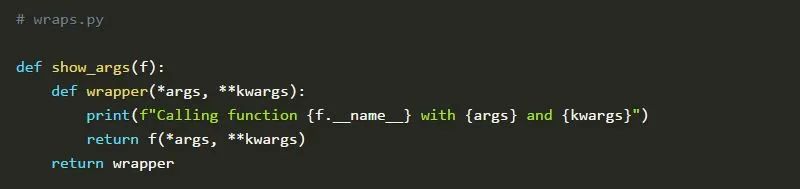
现在,我们可以定义一个函数add(),它会返回两个传递的整数的和。此外,我们还会将新编写的装饰器应用于它,因为我们对该函数的参数和关键字参数比较感兴趣。在脚本的最后,我们打印了一个简单加法的结果以及该函数的文档字符串和名称。
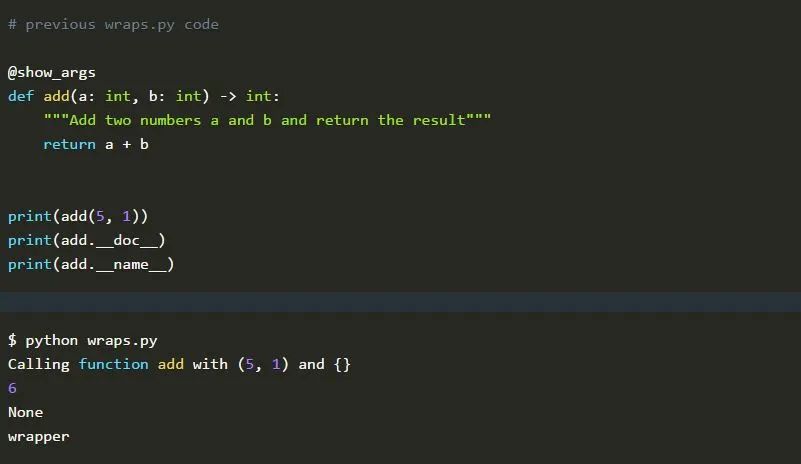
你是否期望看到一个与打印的文档字符串和名称不同的文档字符串和名称呢? 这是因为我们没有访问包装后的函数的文档字符串和名称,而是访问了包装器函数的文档字符串和名称。这里@wraps就派上用场了。我们需要在代码中更改的惟一的东西就是将这个装饰器应用到wrapper()函数。
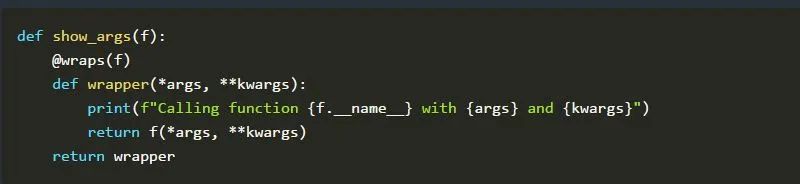
如果我们现在运行该脚本,我们会看到预期的输出:

总 结
恭喜,你已经顺利阅读完了这篇文章!现在,你已经对functools模块所包含的函数有了大致的了解。此外,你还实现了一些示例,其中的这些函数非常有用。
希望你享受阅读这篇文章。记得与你的朋友和同事分享哦。如果你还没有,请考虑在Twitter上关注我,我是@DahlitzF,或者订阅我的时事通讯,这样你就不会错过以后的文章了。保持好奇心,持续编码!
参考资料
functools文档
内置property()函数
Python装饰器入门
itemgetter()文档
Python 中的记忆化:如何缓存函数结果
partialmethod()文档
泛函数 - 词条
单一分派 - 词条
英文原文:https://florian-dahlitz.de/blog/introduction-to-functools
译者:天天向
↓扫描关注本号↓