
【Python实战私活】200元:批量Excel的Vlookup和透视
金融表格信息自动化提取填表
花了一晚上的时间才算把这个单子啃完,算上定金赚了200块,业务逻辑不是很难,难点是表格的处理很繁琐。先炫耀下成果:)
项目需求如下:
一共有4个表,我们姑且称它们为表1,2,3,4吧,表1和表2的买入方和卖出方,需要分别取表3和表4,进行全名替换,也就是如果有简称,需要去表3和表4中将对应的机构名替换为全称,替换完以后,要按照表1中标黄的6个字段和表2进行比对,如果有全部相同的选项,那就是经纪人经手的交易,需要在后续生成的透视表中单独生成一列,也就是是否有经纪人作为标记,其次,最终的展现结果需要表1中的所有数据保持原样,也就是咱们刚才做的机构名替换我还要还原回去,但是在这个原样表旁边,多了一个买入和卖出机构的信息表,这里面要他们的替换名,属实说我当时觉得代码可能会太过啰嗦,不过好在想到了简单的处理办法。除了这个表,就是经纪人表,经纪人表需要原始数据保持不变,同样要生成买入机构和卖出机构的相关交易信息,同样涉及数据的替换和还原。
先看下处理后的数据图:
表1: 这个表格就是全部的交易明细数据,它是有可能由多个工作表组成的数据集,我的代码需要将这些信息想做整合,然后才能实现接下来的需求。考虑到表格众多,为了使程序具有复用性,我全部把每个功能封装进了函数中,看下表格1的处理代码:
这个表格就是全部的交易明细数据,它是有可能由多个工作表组成的数据集,我的代码需要将这些信息想做整合,然后才能实现接下来的需求。考虑到表格众多,为了使程序具有复用性,我全部把每个功能封装进了函数中,看下表格1的处理代码:
# 合并表1中所有的工作表
def df_form1(file_path):
app = x w.App(visible=False,add_book=False)
wb = app.books.open(file_path)
df_list = []
for i in wb.sheets:
df = i.range('A4').expand('table').options(pd.DataFrame).value
df_list.append(df)
df_form1 = pd.concat(df_list)
df_org = pd.concat(df_list)
df_form1['券面总额'] /=10000
df_form1.rename({'券面总额':'券面总额(万元)'},inplace=True,axis=1)
df_form1['成交净价'] = np.round(df_form1['成交净价'],1)
df_form1.reset_index(drop=False,inplace=True)
df_org.reset_index(drop=False,inplace=True)
wb.close()
app.quit()
return (df_form1,df_org)
表2: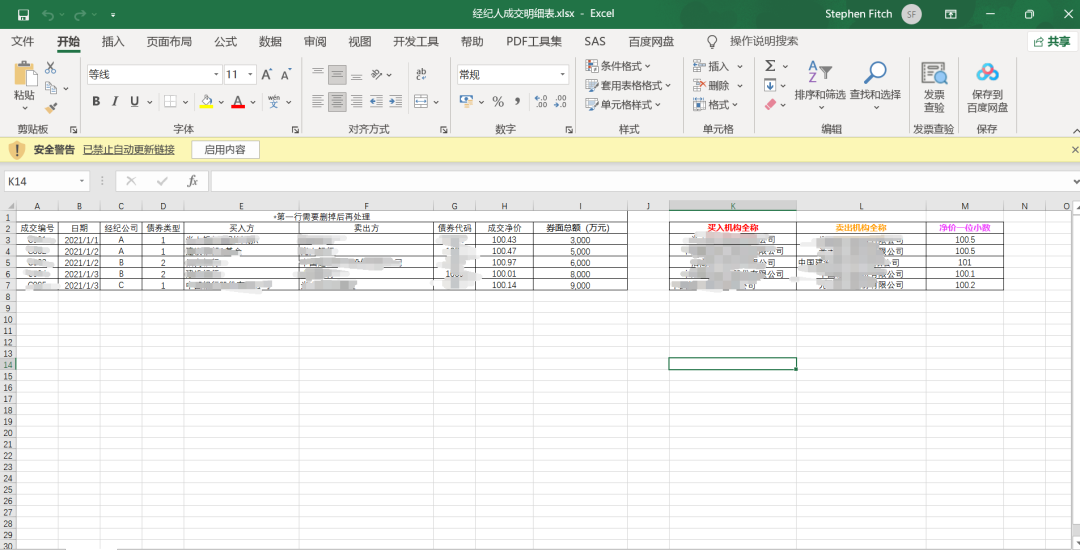 表2左侧的表格是原始数据,右侧是买入和卖出信息,也是最终输出的结果表之一,看下我封装的代码:
表2左侧的表格是原始数据,右侧是买入和卖出信息,也是最终输出的结果表之一,看下我封装的代码:
表1和表2都要注意,如果不做索引重置,那么成交编号这个列名就会成为我们的行索引,那么在最后的处理时,就会报错,因此 使用方法来定义每个表格的功能能够很好的将需求和实现完美的分离,随时可以做极简的修改。
#提取form2信息
def df_form2(file_path):
app = xw.App(visible=False,add_book=False)
wb = app.books.open(file_path)
df = wb.sheets[0].range('A2').expand('table').options(pd.DataFrame).value
df_org = wb.sheets[0].range('A2').expand('table').options(pd.DataFrame).value
df['成交净价'] = np.round(df['成交净价'],1)
df.reset_index(drop=False,inplace=True)
df_org.reset_index(drop=False,inplace=True)
wb.close()
app.quit()
return (df,df_org)
表1和表2的代码你会发现,我返回了一个元组,里面其实是替换数据的dataframe对象和没有替换的dataframe对象,这样我就可以不用写两次代码完成我的需求了。
表3: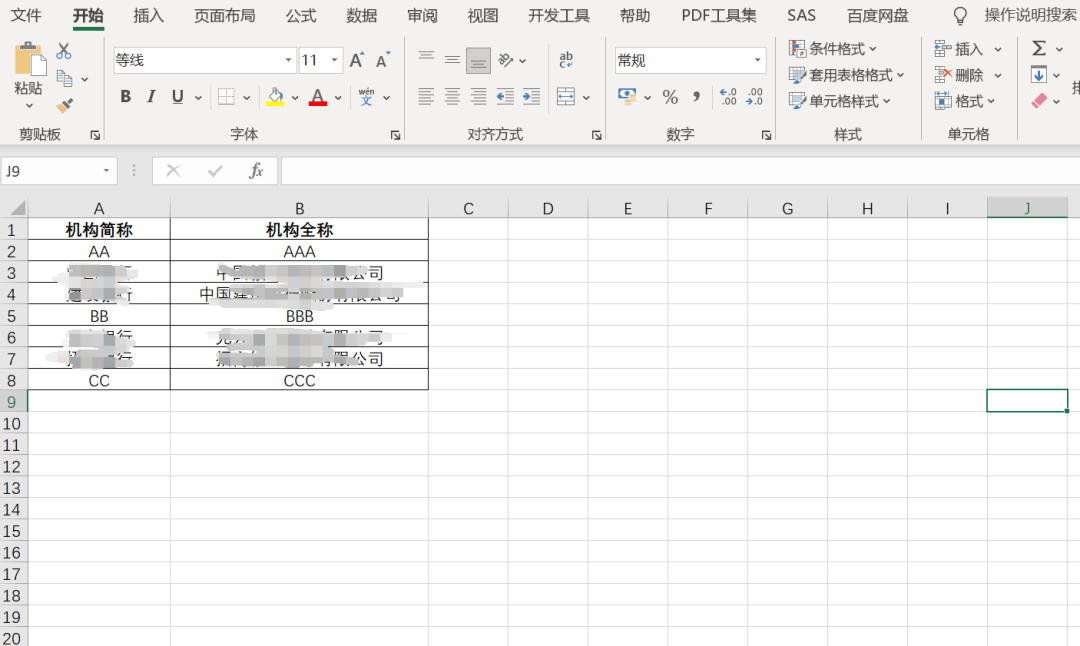
表4:
接下来是主要的业务代码:
首先,我将表1和表2的买入方的机构全名替换写到了一个函数中去,这样做的主要原因是它们的业务逻辑是相同的,没必要写两遍代码,因此也是函数封装:
# 买入方对应表3,4机构全名
# buyer_ser
def buyer_proc(buyer_ser,df_form3,df_form4):
form1_borgs = list(buyer_ser)
form3_orgs = list(df_form3['机构简称'])
form4_orgs = list(df_form4['子机构'])
for i in range(len(form1_borgs)):
if form1_borgs[i] in form3_orgs:
ii = form3_orgs.index(form1_borgs[i])
buyer_ser.loc[i] = df_form3.loc[ii,'机构全称']
elif form1_borgs[i] in form4_orgs:
ii = form4_orgs.index(form1_borgs[i])
buyer_ser.loc[i] = df_form4.loc[ii,'主机构']
else:
continue
return buyer_ser
同理,卖出方如下:
# 卖出方对应表3机构全名
# seller_ser
def seller_proc(seller_ser,df_form3,df_form4):
form1_sorgs = list(seller_ser)
form3_orgs = list(df_form3['机构简称'])
form4_orgs = list(df_form4['子机构'])
for i in range(len(form1_sorgs)):
if form1_sorgs[i] in form3_orgs:
ii = form3_orgs.index(form1_sorgs[i])
seller_ser.loc[i] = df_form3.loc[ii,'机构全称']
elif form1_sorgs[i] in form4_orgs:
ii = form4_orgs.index(form1_sorgs[i])
seller_ser.loc[i] = df_form4.loc[ii,'主机构']
else:
continue
return seller_ser
然后第三个功能是做经纪人的判断,也就是在一开始我说的必须要表1的6个字段和表2的6个字段完全一致才能做这样的判断,注意是替换后的数据匹配。
这里我使用pandas中的merge函数进行匹配,给这个自定义函数传入它们要进行匹配的字段列表即可实现
# 判断是否是经纪人成交
def marker(list1,df1,df2):
df = pd.merge(
left=df1,
right=df2,
left_on=list1,
right_on=list1
)
list_jd = []
for i in df1['成交编号'].index:
if df1.loc[i,'成交编号'] in list(df.loc[:,'成交编号_x']):
list_jd.append('是')
else:
list_jd.append('')
return list_jd
然后生成总表3,也就是在结果集中总的明细数据集中的买入和卖出交易信息表
# 生成总表3
def df3_gen(df1,df2):
df = df1[['买入方','卖出方','券面总额(万元)','成交净价']]
df['通过经纪人成交'] = marker(['买入方','卖出方','券面总额(万元)','成交净价'],
df1,
df2
)
df.rename({'买入方':'买入机构全称',
'卖出方':'卖出机构全称',
'券面总额':'券面总额(万元)',
'成交净价':'净价一位小数'
},inplace=True,axis=1)
return df
代码执行流程:
生成买入卖出机构替换后的dataframe对象:
form1_path = Path(r'D:\Working\私活\财务\完整成交明细表.xlsx')
form2_path = Path(r'D:\Working\私活\财务\经纪人成交明细表.xlsx')
df1 = df_form1(form1_path)[0]
df2 = df_form2(form2_path)[0]
# 查找表1对应的表3,4机构名全称
df_form3 = pd.read_excel(r'D:\Working\私活\财务\机构简称全称对应表.xlsx')
df_form4 = pd.read_excel(r'D:\Working\私活\财务\主从机构对应表.xlsx')
# 改写机构名
df1['买入方'] = buyer_proc(df1['买入方'],df_form3,df_form4)
df1['卖出方'] = seller_proc(df1['卖出方'],df_form3,df_form4)
df2['买入方'] = buyer_proc(df2['买入方'],df_form3,df_form4)
df2['卖出方'] = seller_proc(df2['卖出方'],df_form3,df_form4)
生成总表3:
df3 = df3_gen(df1,df2)
生成总表4:
df4 = df3[df3['通过经纪人成交']=='是'].groupby(['买入机构全称'])['券面总额(万元)'].sum()
生成总表5:
df5 = df3[df3['通过经纪人成交']=='是'].groupby(['卖出机构全称'])['券面总额(万元)'].sum()
生成总表6:
df6 = df2[['买入方','卖出方','成交净价']]
df6.rename({'买入方':'买入机构全称',
'卖出方':'卖出机构全称',
'成交净价':'净价一位小数'},
inplace=True,
axis=1)
df6.set_index('买入机构全称',inplace=True)
以上所有最后需要输出的dataframe我全部生成好了,接下来需要在一个excel文档中的不同部位将他们写入,这个时候就需要用到xlwings的range区域对象来帮助,看下代码:
final_file1 = Path(r'D:\Working\私活\财务\final_total.xlsx')
final_file2 = Path(r'D:\Working\私活\财务\final_agent.xlsx')
app = xw.App(visible=False,add_book=False)
workbook1 = app.books.add()
dff1 = df_form1(form1_path)[1]
dff1.set_index('成交编号',inplace=True)
workbook1.sheets[0].range('A1').value = dff1
df3.set_index('买入机构全称',inplace=True)
workbook1.sheets[0].range('J1').value = df3
workbook1.sheets[0].range('P1').value = df4
workbook1.sheets[0].range('S1').value = df5
workbook1.save(final_file1)
workbook2 = app.books.add()
dff2 = df_form2(form2_path)[1]
dff2.set_index('成交编号',inplace=True)
workbook2.sheets[0].range('A1').value = dff2
workbook2.sheets[0].range('K1').value =df6
workbook2.save(final_file2)
workbook1.close()
workbook2.close()
app.quit()
最终可以批量化,自动的生成所需要的数据,而且所有的功能都被封装到了方法中,后续有变动不需要管数据是怎么样的,只要去看功能是否有变化,如果数据变为更多的文件需要处理,那么只需要写个循环语句,直接拿来方法使用就可以了,是不是很方便?
最后,推荐蚂蚁老师的《零基础入门Python到实战数据分析》课程