
Java数据结构与算法:多路查找树
作者:subeiLY https://blog.csdn.net/m0_46153949/article/details/106742330
本章思维导图
二叉树与B树
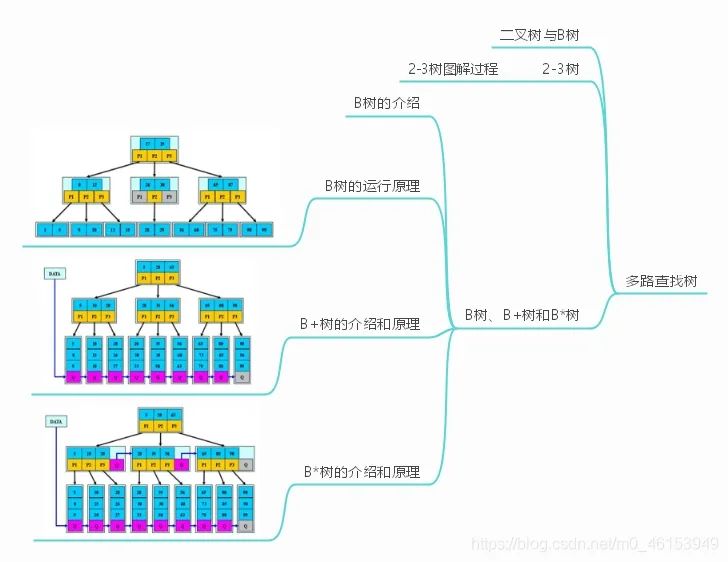
二叉树的问题分析 二叉树的操作效率较高,但是也存在问题, 请看下面的二叉树:
B树的基本介绍 B树通过重新组织节点,降低树的高度,并且减少读写次数来提升效率。

2-3树
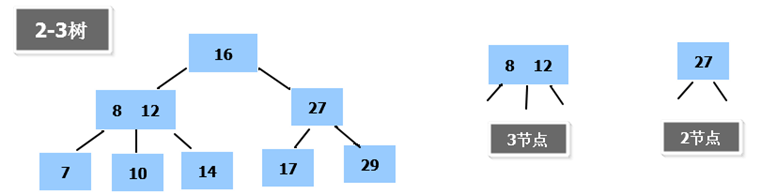
2-3树基本介绍:
2-3树是最简单的B树结构, 具有如下特点:
2-3树的所有叶子节点都在同一层.(只要是B树都满足这个条件)
有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点.
有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点.
2-3树是由二节点和三节点构成的树。
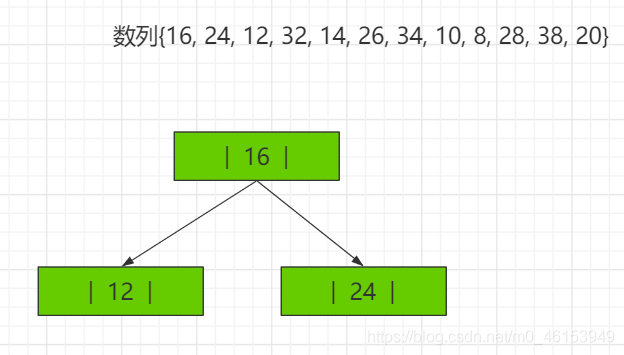
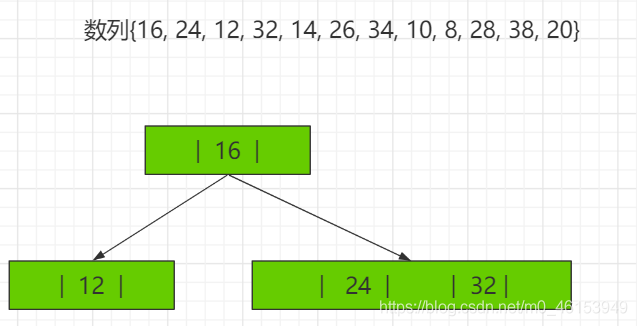
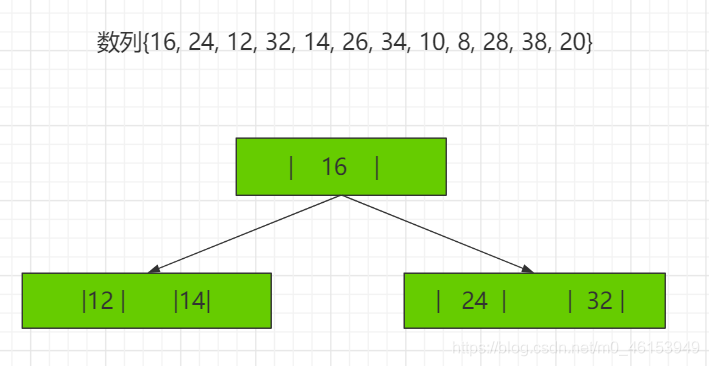
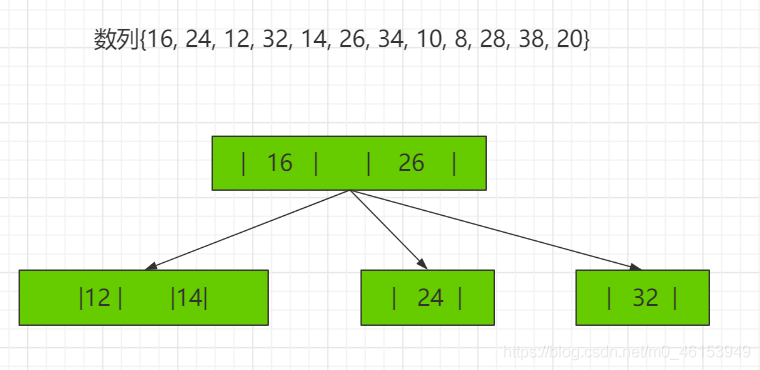
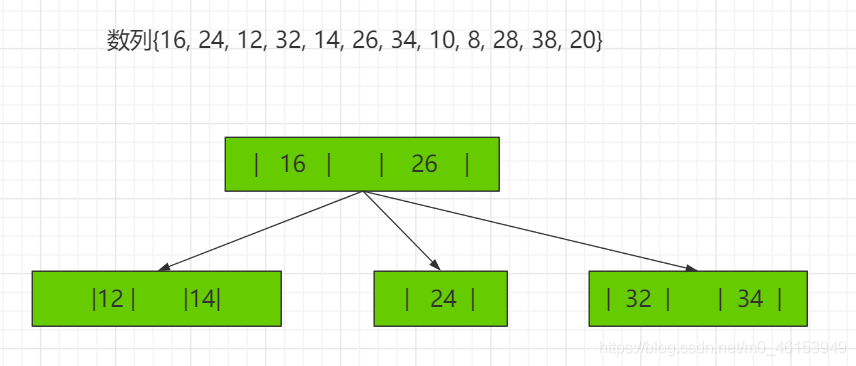
2-3树应用案例 将数列{16, 24, 12, 32, 14, 26, 34, 10, 8, 28, 38, 20} 构建成2-3树,并保证数据插入的大小顺序。 (演示构建2-3树的过程 ——> 如下:)


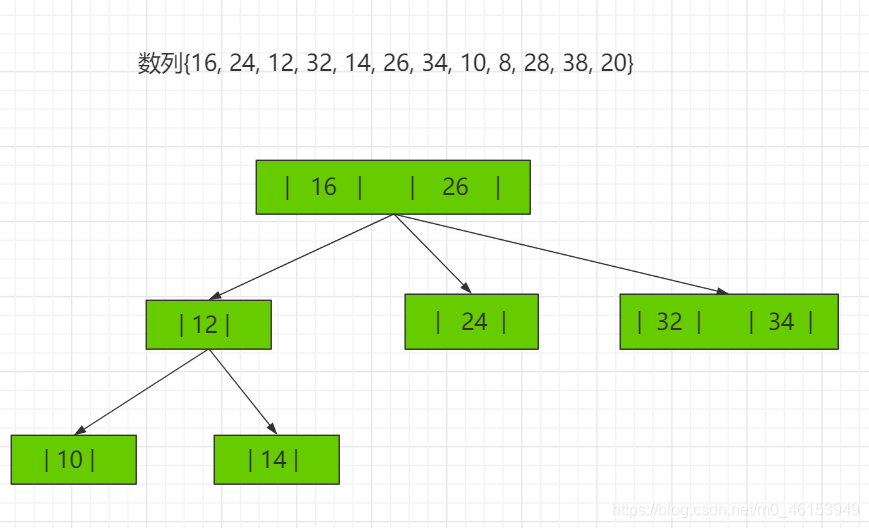
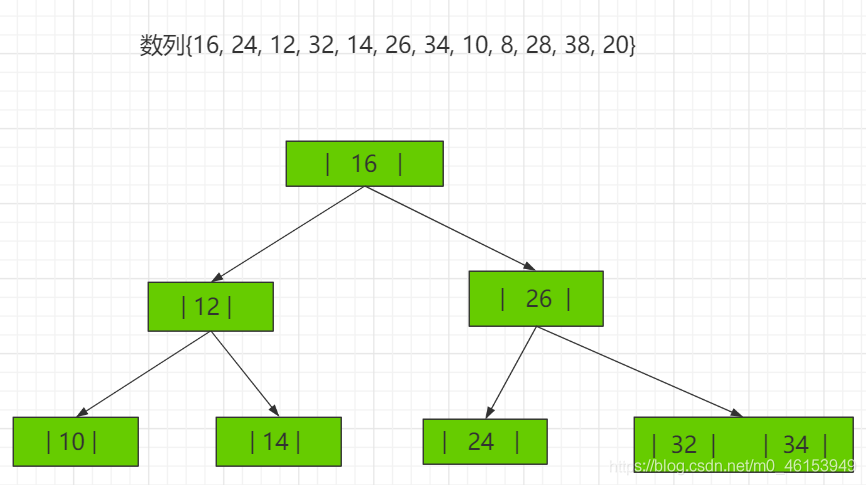
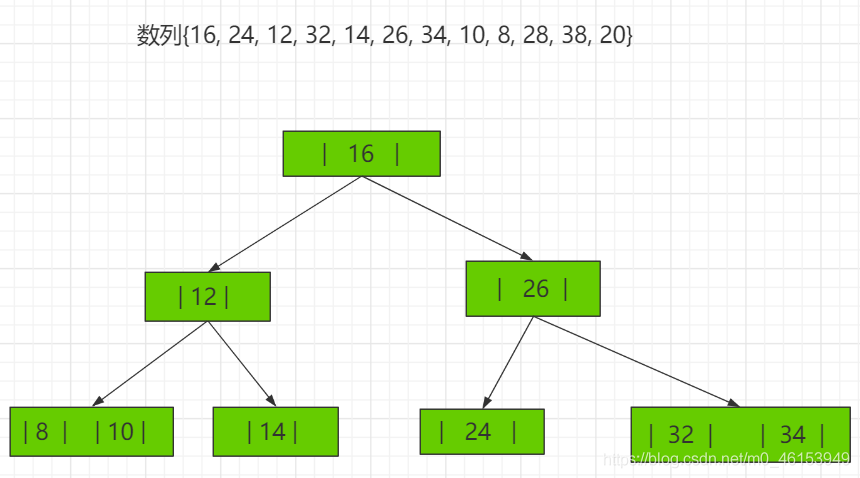
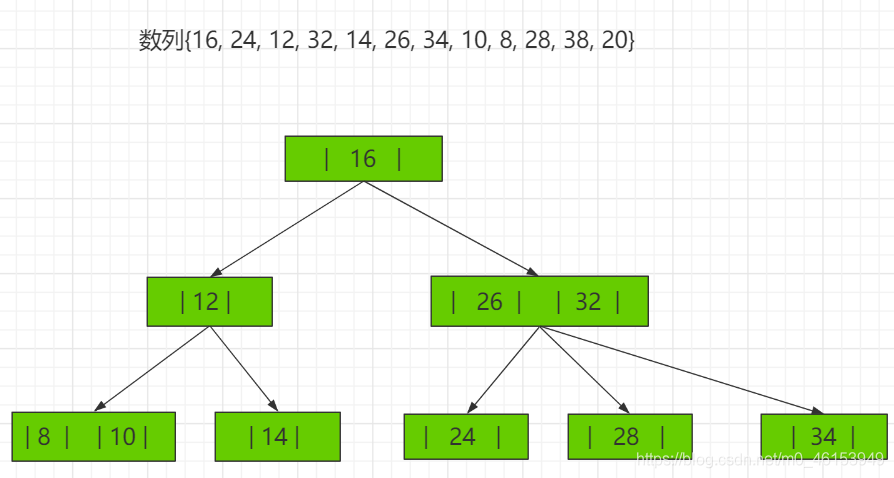
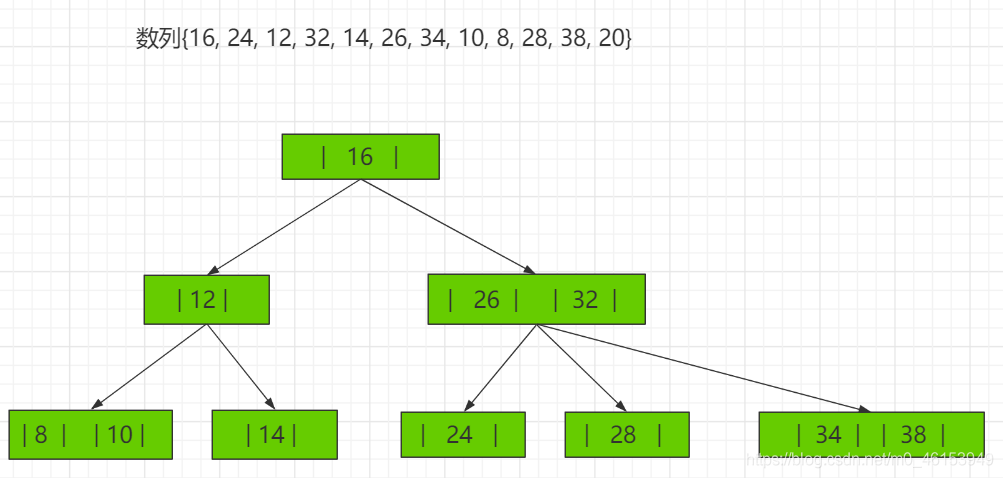
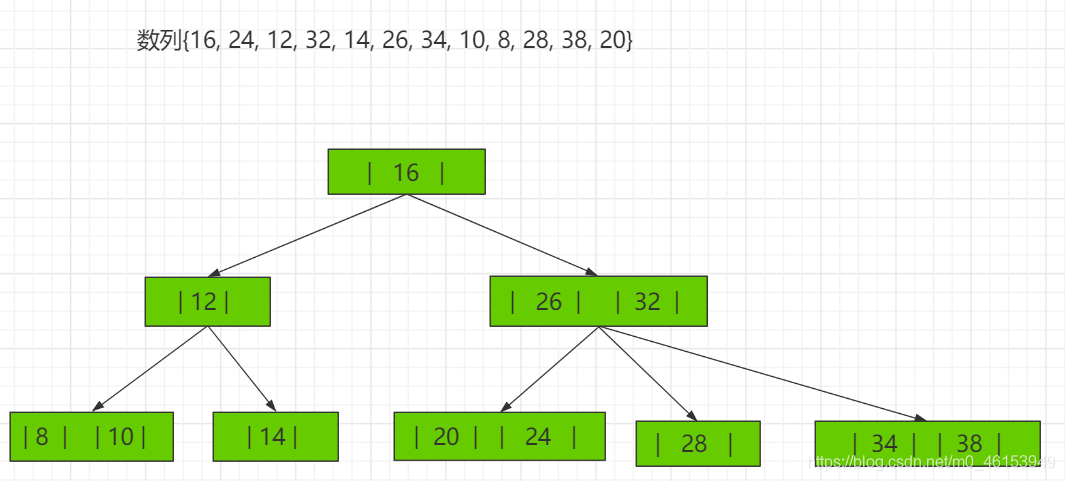
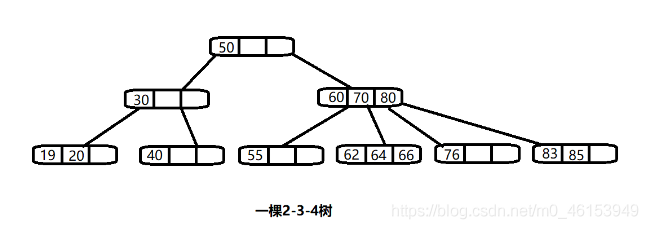
其它说明 除了23树,还有234树等,概念和23树类似,也是一种B树。如图:
B树、B+树和B*树
B树的介绍 B-tree树即B树,B即Balanced,平衡的意思。有人把B-tree翻译成B-树,容易让人产生误解。会以为B-树是一种树,而B树又是另一种树。实际上,B-tree就是指的B树。
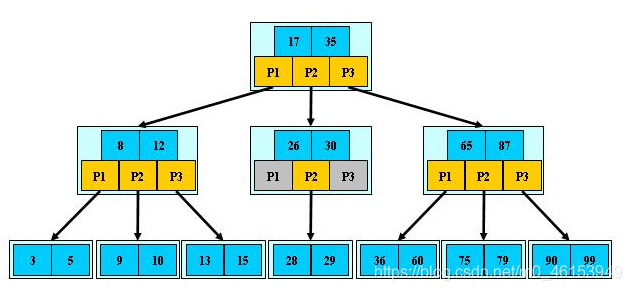
前面已经介绍了2-3树和2-3-4树,他们就是B树(英语:B-tree 也写成B-树),这里我们再做一个说明,我们在学习Mysql时,经常听到说某种类型的索引是基于B树或者B+树的,如图:
B+树的介绍 B+树是B树的变体,也是一种多路搜索树。
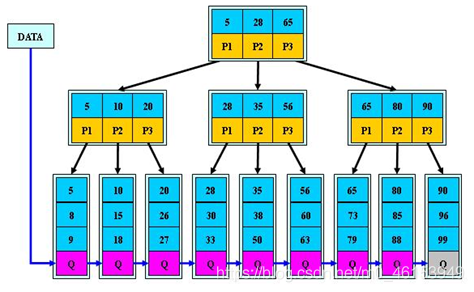
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针。
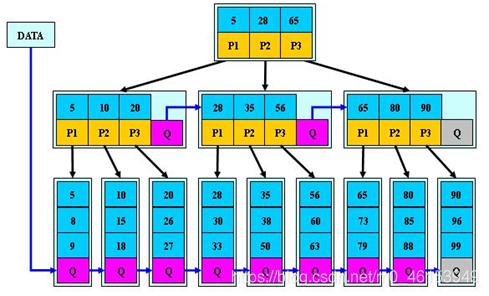
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3,而B+树的块的最低使用率为B+树的1/2。
从第1个特点我们可以看出,B*树分配新结点的概率比B+树要低,空间使用率更高
更多精彩: 记一次由Redis分布式锁造成的重大事故,避免以后踩坑! 6 个 Spring Boot 项目够经典,建议收藏! 数据量很大,分页查询很慢,推荐个优化方案! 京东把 Elasticsearch 用得真牛逼!日均5亿订单查询完美解决! 推荐一款免费开源的通用数据库工具 这么设计,Redis 10亿数据量只需要100MB内存 关注公众号,查看更多优质文章 最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。 明天见(。・ω・。)ノ♡
评论