
60 行代码,10000 个虎牙小姐姐视频来袭!
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:Python 技术 作者:某某白米饭

获取播放列表
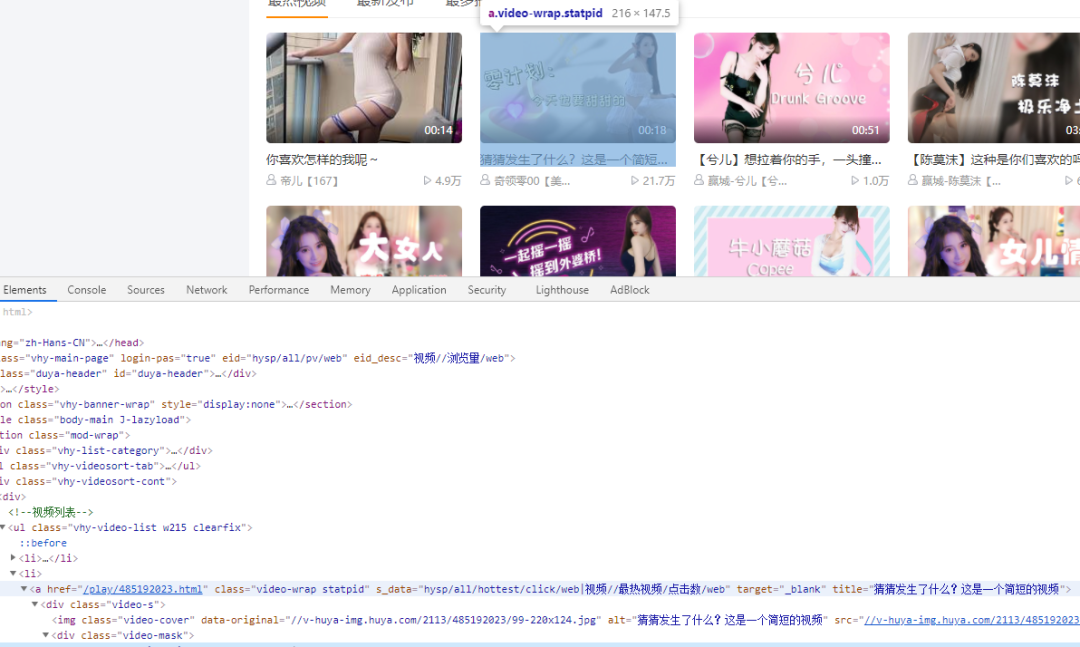
打开虎牙上星秀/颜值的视频地址 https://v.huya.com/g/all?set_id=31&order=hot&page=1,我们可以看到看到一共 500 页,每页有 20 条视频,总共 10000 条小姐姐的视频。

通过观察 F12 控制台可知每个视频播放页超链接都在 li 标签下,获取到 li 标签就可以取到视频地址了。然后将视频名字和地址用 | 存入 txt 文本或者 list 变量中。
import requests
from bs4 import BeautifulSoup
import time
import random
import json
import re
url_file_name = 'D:\\url.txt'
def get_list():
for p in range(500):
html = requests.get('https://v.huya.com/g/all?set_id=31&order=hot&page={}'.format(p+1));
soup = BeautifulSoup(html.text, 'html.parser')
ul = soup.find('ul', class_='vhy-video-list w215 clearfix')
lis = ul.find_all('li')
for li in lis:
a = li.find('a', class_ = 'video-wrap statpid');
href = a.get('href')
title = a.get('title')
# 去掉文件名中的特殊字符
title = validate_title(title)
with open(url_file_name,'a',encoding = 'utf-8') as f:
f.write(title + '|' + href + '\n')
print("已经抓取了 {} 页".format(p + 1))
time.sleep(random.randint(1, 9)/10)
def validate_title(title):
rstr = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(rstr, "", title)
return new_title
示例结果:

获取视频地址
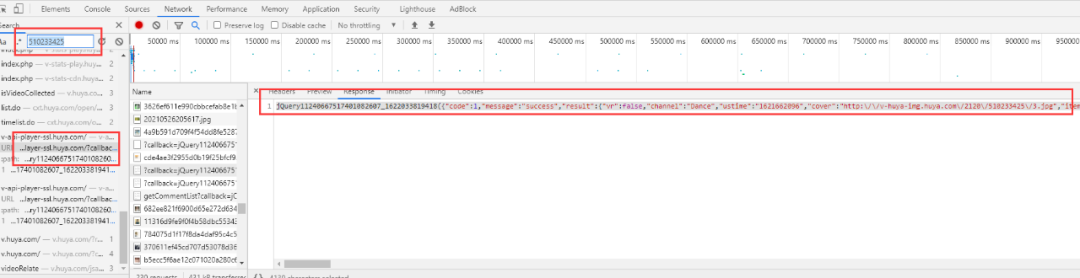
下载视频只得到视频的播放页地址是远远不够的,还需要得到每个视频的真实播放地址。通过如下图观察 Network 面板可以发现视频播放地址在 https://v-api-player-ssl.huya.com/?r=vhuyaplay%2Fvideo&vid=510233425&format=mp4%2Cm3u8 的返回值中。
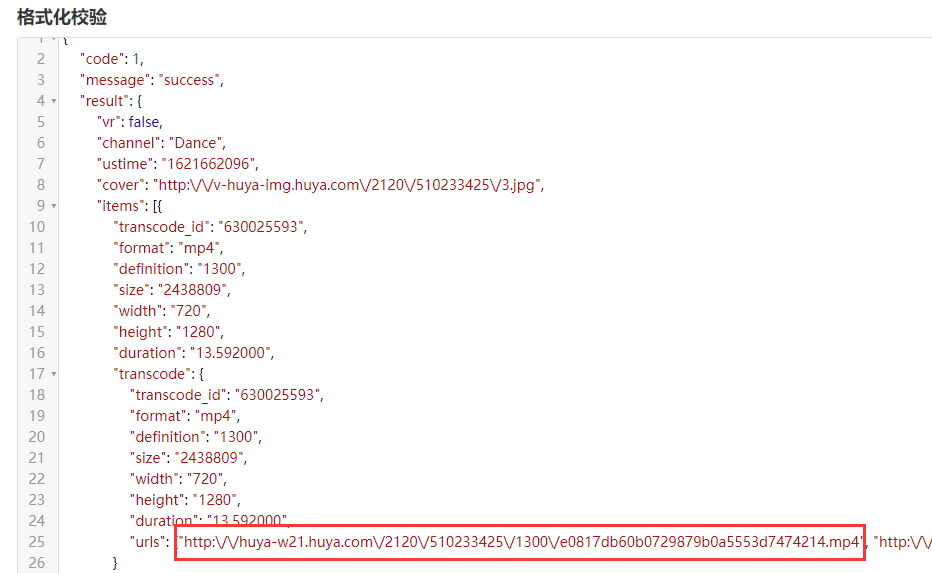
json 格式化后结果:
def get_video_url():
urls_file = open(url_file_name, 'r', encoding='utf-8')
url_lines = urls_file.readlines()
urls_file.close()
video_urls = []
for line in url_lines:
# 视频名字 | 地址
infos = line.split('|')
video_id = infos[1].replace('.html\n', '').replace('/play/', '');
data = requests.get('https://v-api-player-ssl.huya.com/?r=vhuyaplay%2Fvideo&vid={}&format=mp4%2Cm3u8'.format(video_id))
data = json.loads(data.text)
url = data['result']['items'][0]['transcode']['urls'][0]
video_urls.append({'title': infos[0], 'url':url})
return video_urls
最后调用写文件函数保存视频。
def save_video(video_urls):
for item in video_urls:
title = item.get('title')
print('正在下载:{}'.format(title))
html = requests.get(item.get('url'))
data = html.content
with open('D:\\{}.mp4'.format(title), 'wb') as f:
f.write(data)
print('全部下载完成了')
示例结果:

总结
这个 Python 脚本比较简单,比 B 站的视频下载简单多了,有兴趣的小伙伴可以试着练练手。喜欢二次元小姐姐的小伙伴可以将星秀频道 url 换成二次元频道 url。
--END--
推荐图书
图书介绍:《Excel 在数据处理与分析中的应用》本书从实际工作应用出发,以“数据获取→数据整理与编辑→数据计算处理→数据汇总处理→数据分析处理→数据展示报告→相关行业数据处理应用”为线索,精心挑选了多个案例,详细讲解了Excel数据处理与分析的相关技能。
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
优秀的读者都知道,“点赞”传统美德不能丢 
评论