
某厂面试:如何优雅使用 SPI 机制
代码不多,文章可能有点长。朋友面试某厂问到的 SPI 机制,联想到自己项目最近写到的 SPI 场景,文章简要描述下 SPI 机制的发展历程
产出背景
因为最近项目中使用分库分表以及数据加密使用到了 ShardingSphere,所以决定这段时间看看源码实现。问我为什么要读源码?不看源码怎么提高逼格嘞,就是这么朴实无华~

Sharding-Jdbc SPI
看源码的历程,往往从点开 Jar 包的瞬间开始。好巧不巧,就看到源代码包下有个 SPI 包,处于好奇心就点了一点,嗯~ 代码果然很熟悉,还是那个配方原来的味道
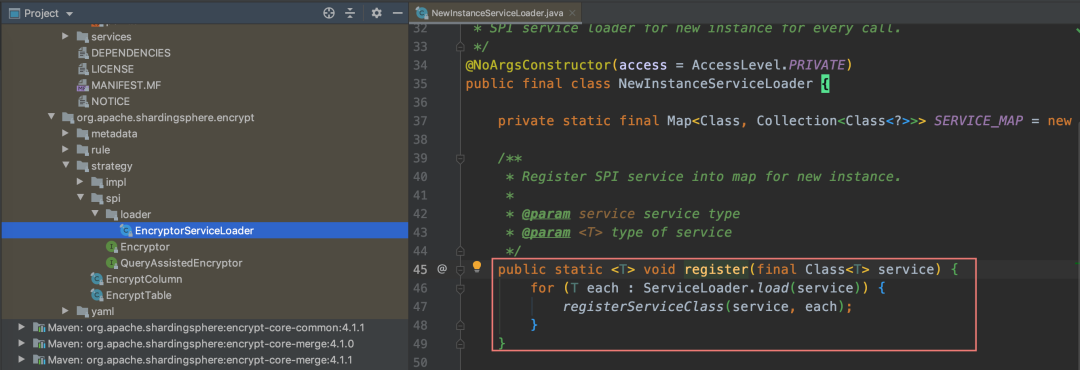
看了许久,陷入深深的沉思。内心小九九:这玩意好像之前看过,但是在哪我忘了,这到底是个啥?
代码还是那个代码,只是它认识我,我不认识它了
这一块的 SPI 接口是 shrding-jdbc 预留自定义加密器的接口
看到这里相信就遇到过绝大多数技术同学都会遇到的一个问题,那就是 认为自己会了,实际情况呢?不一定。所以,学习一门技术,一定要多看几遍,尝试去理解记忆。千万不要看一遍之后,眼高手低认为技术 so easy,然后隔十天半个月就啥都不记的

继续回过头来说说今天的主角:SPI。首先回答这么一个问题,什么是 SPI 机制
SPI 全称为 Service Provider Interface,是一种服务发现机制。为了被第三方实现或扩展的 API,它可以用于实现框架扩展或组件替换
SPI 机制本质是将 接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载文件中的实现类,这样运行时可以动态的为接口替换实现类
看文字描述介绍总是枯燥无味且空洞的。简单一点来说,就是你在 META-INF/services 下面定义个文件,然后通过一个特殊的类加载器,启动的时候加载你定义文件中的类,这样就能扩展原有框架的功能
就这么简单,那可能有读者会问:我不定义在 META-INF/services 下面行不行?就想定义在别的地方

不行滴,请遏制住这么危险的想法,人家怎么定义你就怎么实现。这是 JDK 规定好的配置路径,你随便定义,类加载器怎么知道去哪里加载
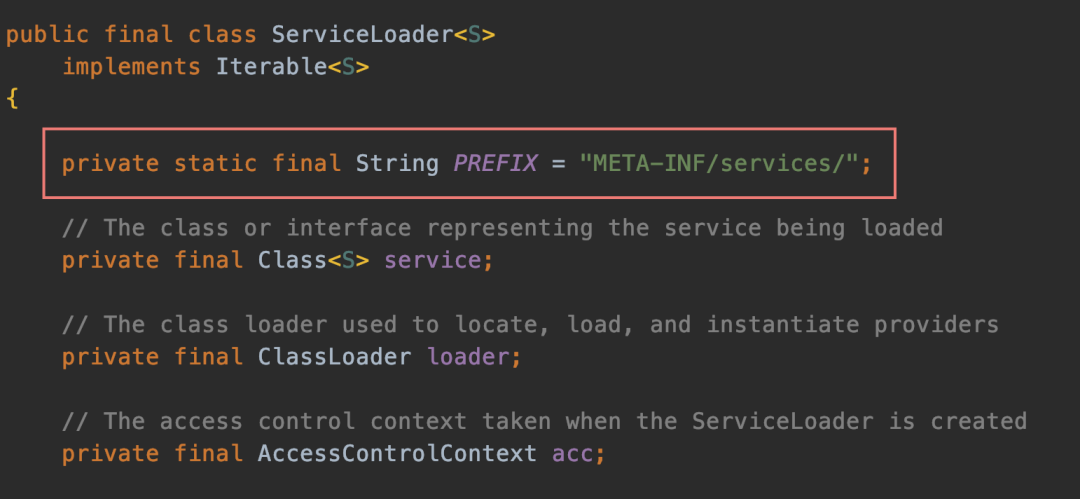
看到这个 PREFIX 常量之后,想法比较活跃的小伙子不知道清醒点了么。简单画张图来描述下 SPI 的运行机制

有点 SPI 基础的同学看到图之后应该又开始自信了,这不就是我之前看过的那玩意么?是的,技术还是那个技术,可以继续往下看看,有没有自己不知道的
为什么要有 SPI
了解一项技术的前提,一定要知道它为了解决什么样的痛点而存在,JDK 作者也不会没屁事加点代码玩
引入了 SPI 机制后,服务接口与服务实现就会达成分离的状态,可以实现 解耦以及程序可扩展机制。服务提供者(比如 springboot starter)提供出 SPI 接口后,客户端(平常的 springboot 项目)就可以通过本地注册的形式,将实现类注册到服务端,轻松实现可插拔
数据加密举例
以实际项目举个例子,就拿 sharding-jdbc 数据加密模块来说,sharding-jdbc 本身支持 AES 和 MD5 两种加密方式。但是,如果客户端不想用内置的两种加密,偏偏想用 RSA 算法呢?难道每加一种算法,sharding-jdbc 就要发个版本么

sharding-jdbc 可不会这么干,首先提供出 Encryptor 加密接口,并引入 SPI 的机制,做到服务接口与服务实现分离的效果。如果客户端想要使用新的加密算法,只需要在客户端项目 META-INF/services 目录下定义接口的全限定名称文件,并在文件内写上加密实现类的全限定名,就像这样式的
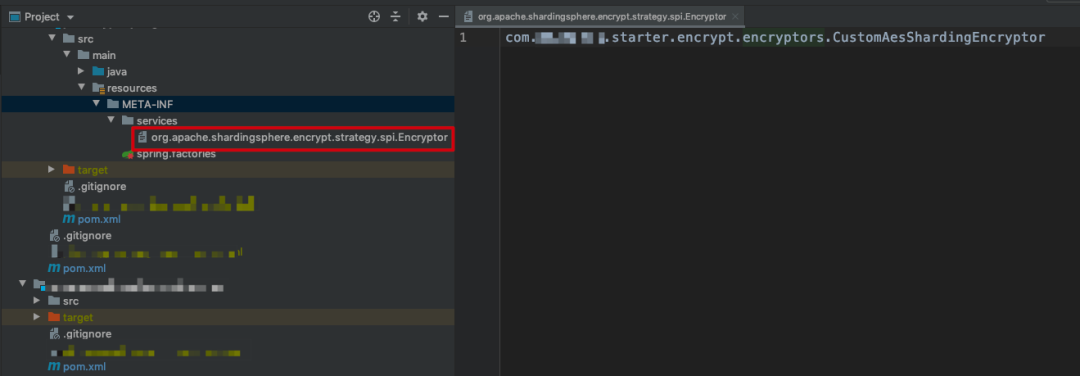
通过 SPI 的方式,就可以将客户端提供的加密算法加载到 sharding-jdbc 加密规则中,这样就可以在项目运行中选择自定义算法来对数据进行加密存储
通过 sharding-jdbc 的例子,可以很好的看出来,上面提到的 SPI 优点,都体现了出来
客户端(自己的项目)提供了服务端(sharding-jdbc)的接口自定义实现,但是与服务端状态分离,只有在客户端提供了自定义接口实现时才会加载,其它并没有关联;客户端的新增或删除实现类不会影响服务端 如果客户端不想要 RSA 算法,又想要使用内置的 AES 算法,那么可以随时删掉实现类,可扩展性强,插件化架构
对象存储举例


实战讲解
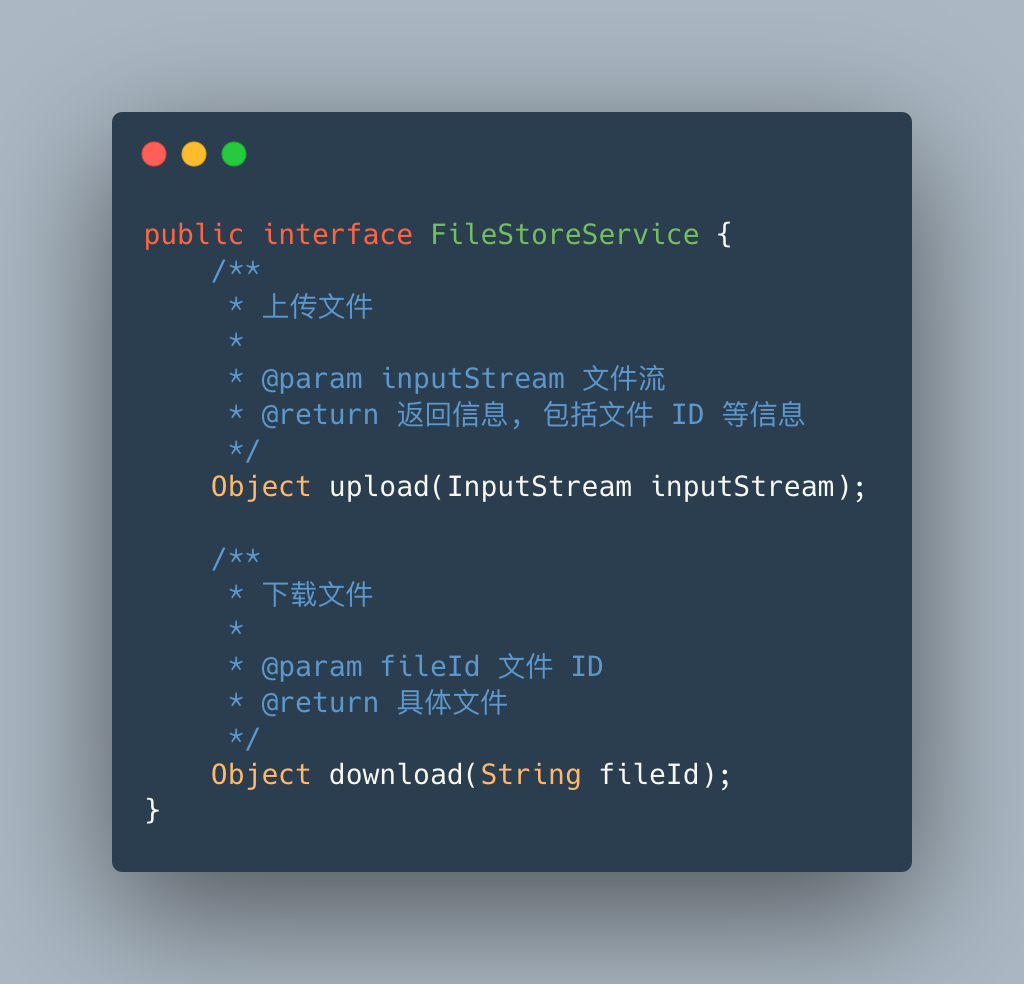
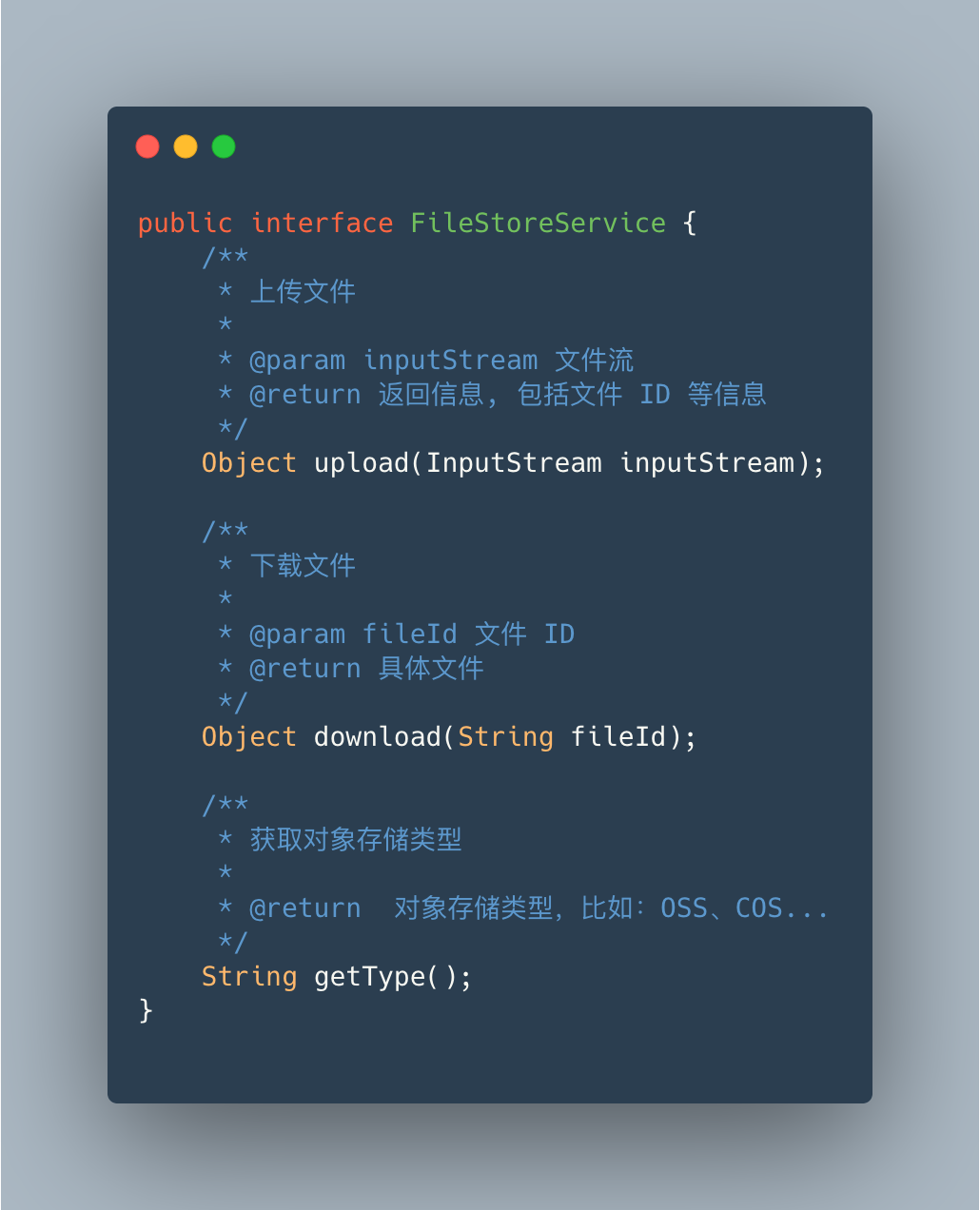
var 是 lombok 的注解,可以自动识别对象类型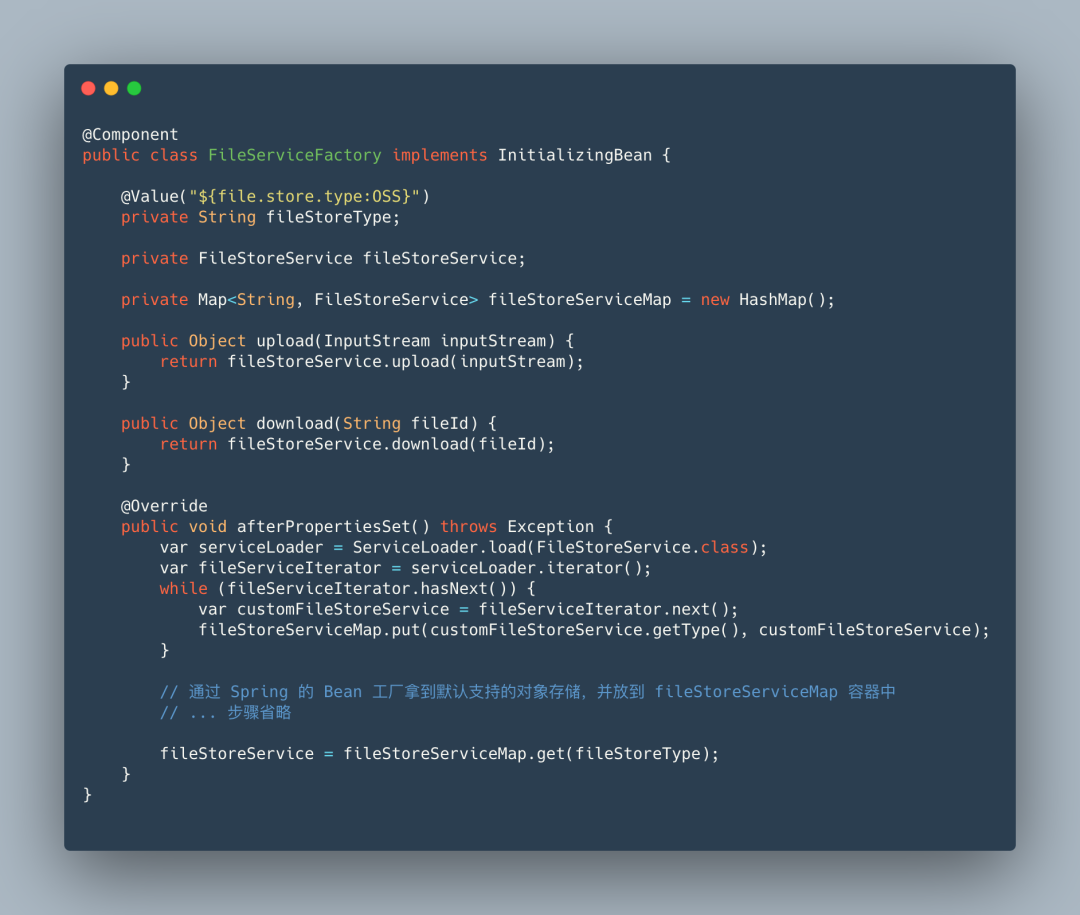
FileServiceFactory大家可以理解为文件服务对外的统一访问入口。实现了 spirng 初始化的一个接口,可以在 bean 初始化时进行代码逻辑操作bean 初始化时,通过 ServiceLoader类加载器负责加载对象存储接口,这样就能加载到客户端存放到META-INF/services中的自定义对象存储实现获取到自定义对象存储后,和服务端本身自带的对象存储一起存放至容器中,这样就可以根据项目中的 fileStoreType获取对应的服务了

深入解析 SPI
ServiceLoader 底层都做了什么事情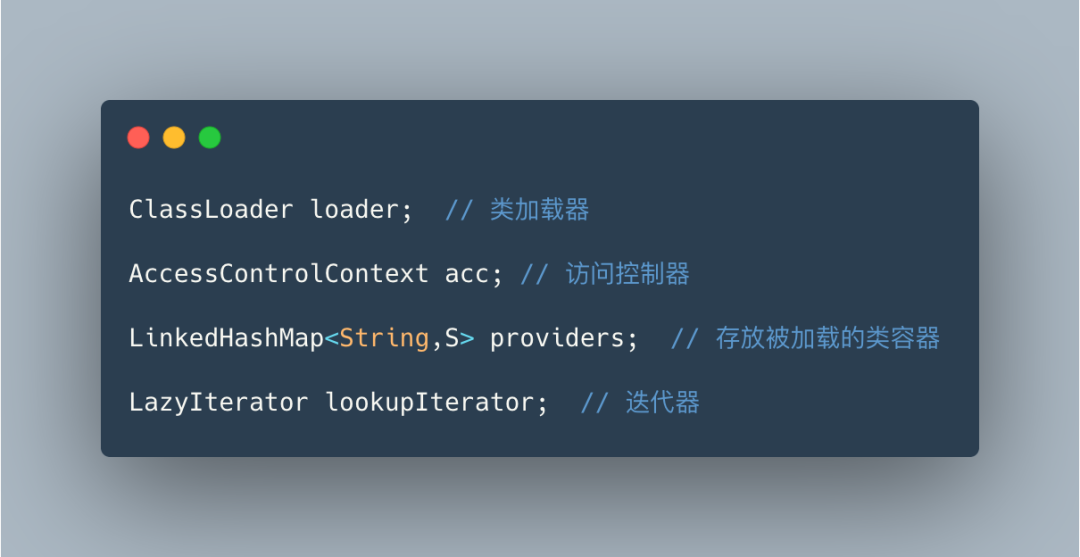
providers 对象中是否有实例对象LazyIterator#hasNextService读取META-INF/services下的配置文件,获得所有能被实例化的类的名称,并完成 SPI 配置文件的解析LazyIterator#nextService负责实例化hasNextService()读到的实现类,并将实例化后的对象存放到providers集合中缓存
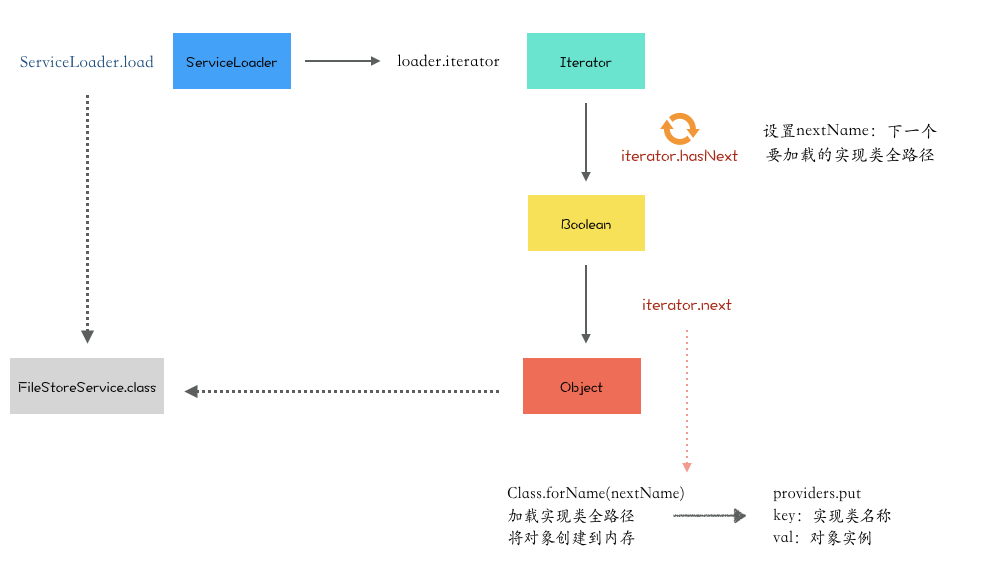
ServiceLoader 底层执行的方法,跟着下面这个程序敲一遍代码就懂了
结言
SPI 机制优势就是解耦。将接口的定义以及具体业务实现分离,而不是和业务端全部耦合在一端。可以实现 运行时根据业务实际场景启用或者替换具体组件 SPI 机制的场景就是 没有统一实现标准的业务场景。一般就是,服务端有标准的接口,但是没有统一的实现,需要业务方提供其具体实现。比如说 JDBC 的 java.sql.Driver接口和不同云厂商提供的数据库实现包
不能按需加载。虽然 ServiceLoader 做了延迟加载,但是只能通过遍历的方式全部获取。如果其中某些实现类很耗时,而且你也不需要加载它,那么就形成了资源浪费 获取某个实现类的方式不够灵活,只能通过迭代器的形式获取。这两点可以参考 Dubbo SPI 实现方式进行业务优化
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️