
pandas100个骚操作:逆天!一行代码让 apply 速度飙到极致

来源:Python数据科学
作者:东哥起飞
大家好,我是东哥。
本篇介绍一行代码让 pandas 的 apply 速度飙到极致!
如果想要让pandas提速,东哥总结有两个方法:
1. 向量化
向量化是最优的方法,具体用法参考文章:pandas100个骚操作:再见 for 循环!速度提升315倍!
举个例子,我们将向量化定义为使用Numpy表示整个数组而不是元素的计算。下面有两个数组:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])
我们希望创建一个新数组,该数组是两个数组的总和,结果应该是:
result = [7,9,11,13,15]
当然,我们也可以在Python中使用for循环将这些数组求和,但这非常慢。替代的是,Numpy允许我们直接在阵列上进行操作,这要快得多,尤其是大型阵列。
result = array_1 + array_2
2. 并行化
dask。pandas使用比较多的一个功能就是apply功能,使用自带函数或者自己写个函数,可以直接对dataframe进行变换,非常香!本次给大家分享一个神器 Swifter,可以自动让apply的运行速度达到最快,并且只需要一行代码!
Swifter是这样做的。Dask进行并行处理或仅使用普通Pandas的apply(仅使用单个内核)哪个更合理。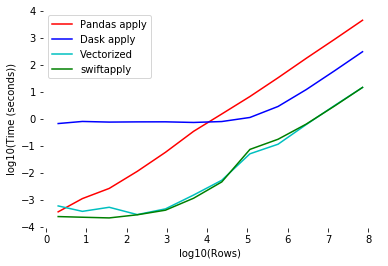
swifter可以直接为我们自动选择最佳的方式。Swifter的使用非常简单。import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
swifter,然后简单的一行代码调用即可,赶快试一下这个神器!
相关阅读:
评论