
详尽!统计学知识大梳理
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
来源:海豚数据科学实验室 编辑:深度学习冲鸭
著作权归作者所有,文仅分享,侵权
道德经云:”道生一,一生二,二生三,三生万物“。学习知识亦是如此,一个概念衍生出两个概念,两个概念演化出更小的子概念,接着衍生出整个知识体系。
笔者结合自己对统计学和概率论知识的理解写了这篇文章,有以下几个目标。
目标一:构建出可以让人理解的知识架构,让读者对这个知识体系一览无余
目标二:尽l量阐述每个知识在数据分析工作中的使用场景及边界条件
目标三:为读者搭建从“理论”到“实践"的桥梁
你的“对象” 是谁?


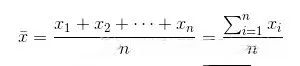



Q1:第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。 Q2:第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。 Q3:第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
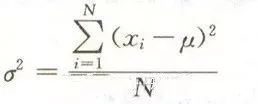
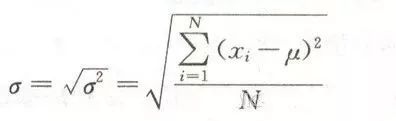

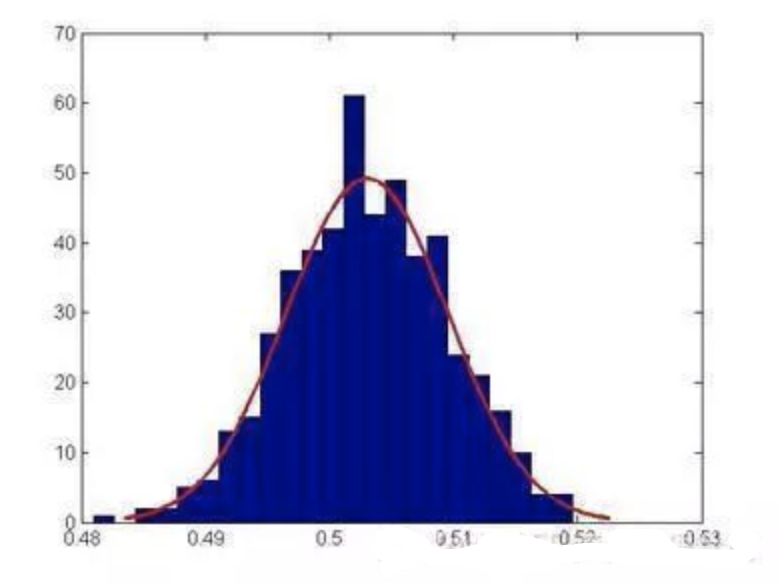
事件:有概率可言的一件事情,一个事情可能会发生很多结果,结果和结果之间要完全穷尽,相互独立。 概率:每一种结果发生的可能性。所有结果的可能性相加等于1,也就是必然!!! 概率分布:我们把事件和事件所对应的概率组织起来,就是这个事件的概率分布。

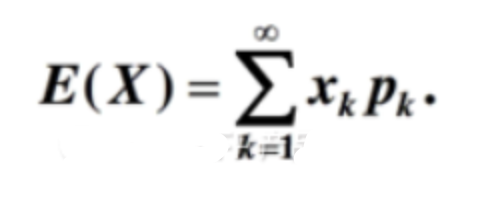

离散数据: 一个粒儿,一个粒儿的数据就是离散型数据。 连续数据: 一个串儿,一个串儿的数据就是连续型数据。


f(x)----是该关于事件X的概率密度函数 μ --- 均值 σ^2 ---方差 σ ---标准差
step1 --- 确定分布和范围 ,求出均值和方差 step2 --- 利用标准分将正态分布转化为标准正态分布 (还记得 第一部分的标准分吗?) step3 ---查表找概率

对立事件:如果一个事件,A’包含所有A不包含的可能性,那么我们称A’和A是互为对立事件 穷尽事件:如何A和B为穷尽事件,那么A和B的并集为1 互斥事件:如何A和B为互斥事件,那么A和B没有任何交集 独立事件:如果A件事的结果不会影响B事件结果的概率分布那么A和B互为独立事件。

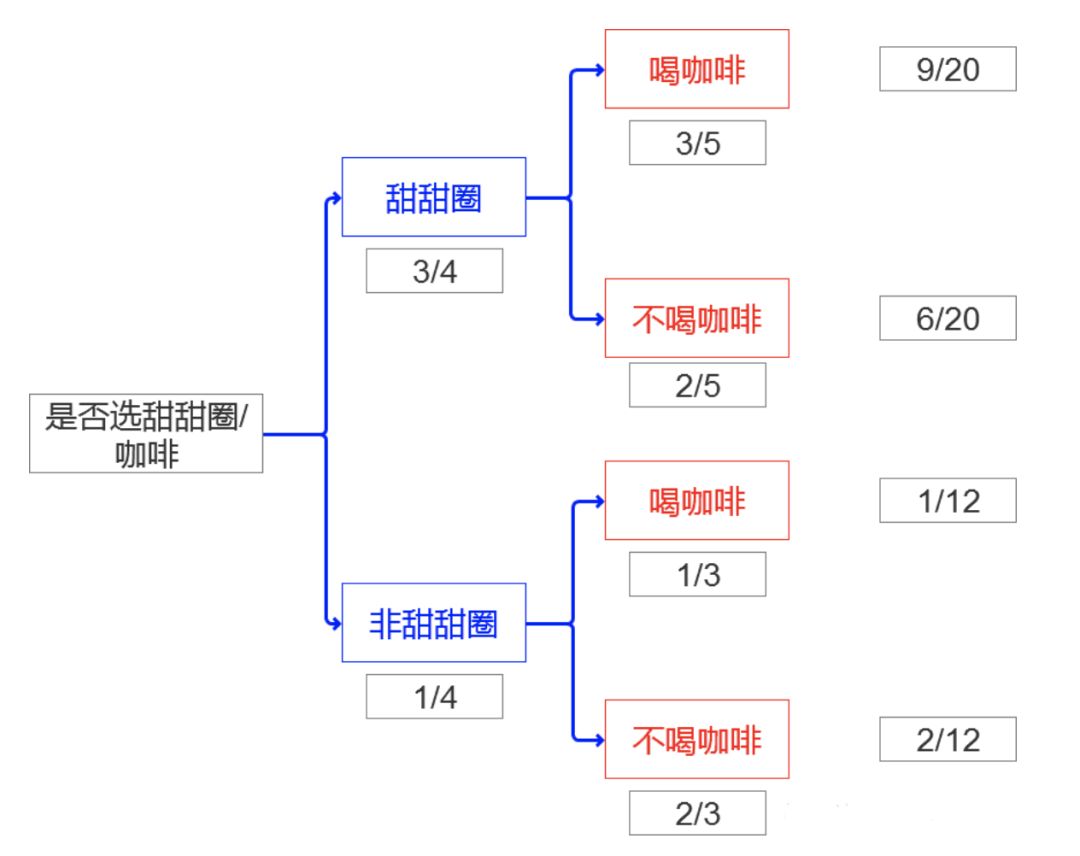
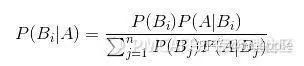

总体:你研究的所有事件的集合 样本:总体中选取相对较小的集合,用于做出关于总体本身的结论 偏倚:样本不能代表目标总体,说明该样本存在偏倚 简单随机抽样: 随机抽取单位形成样本。 分成抽样: 总体分成几组或者几层,对每一层执行简单随机抽样 系统抽样:选取一个参数K,每到第K个抽样单位,抽样一次。

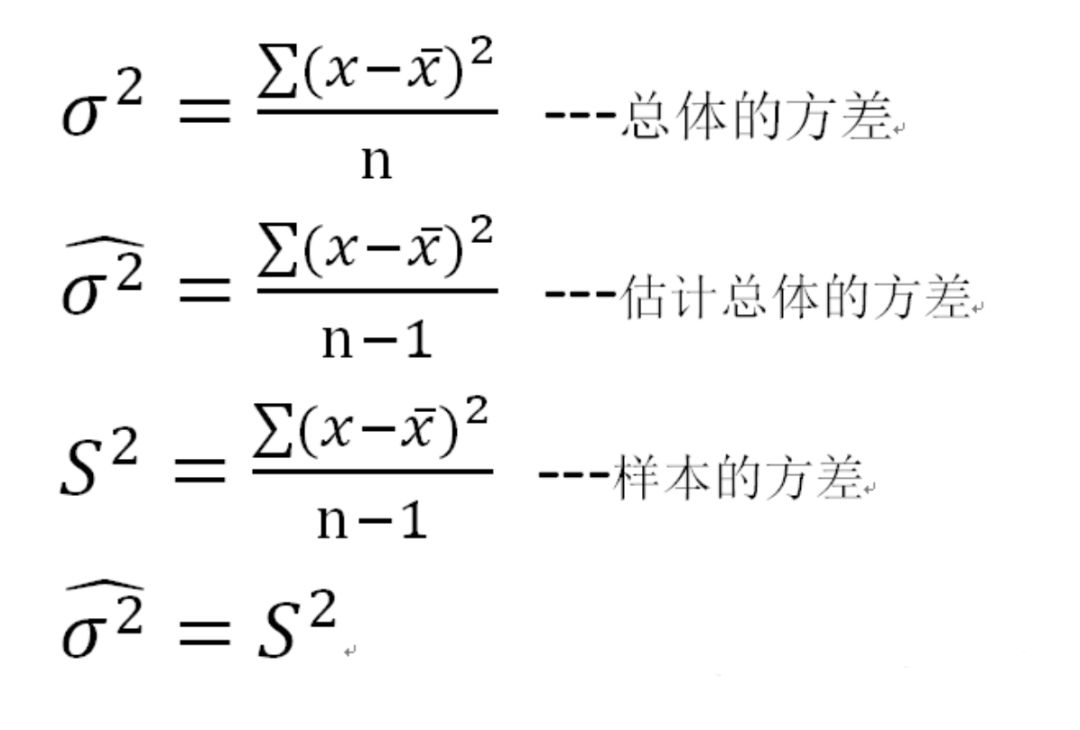

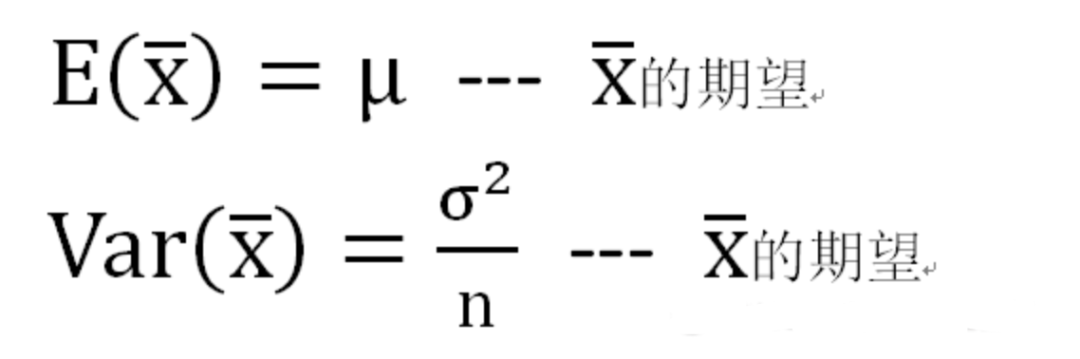
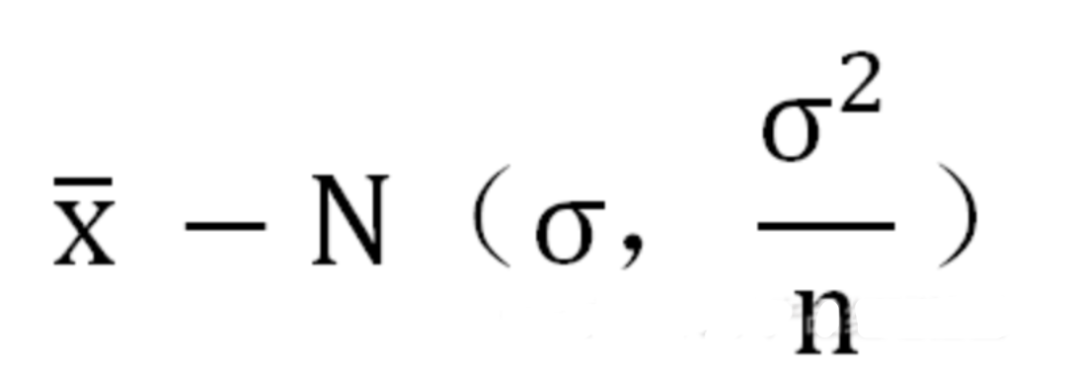

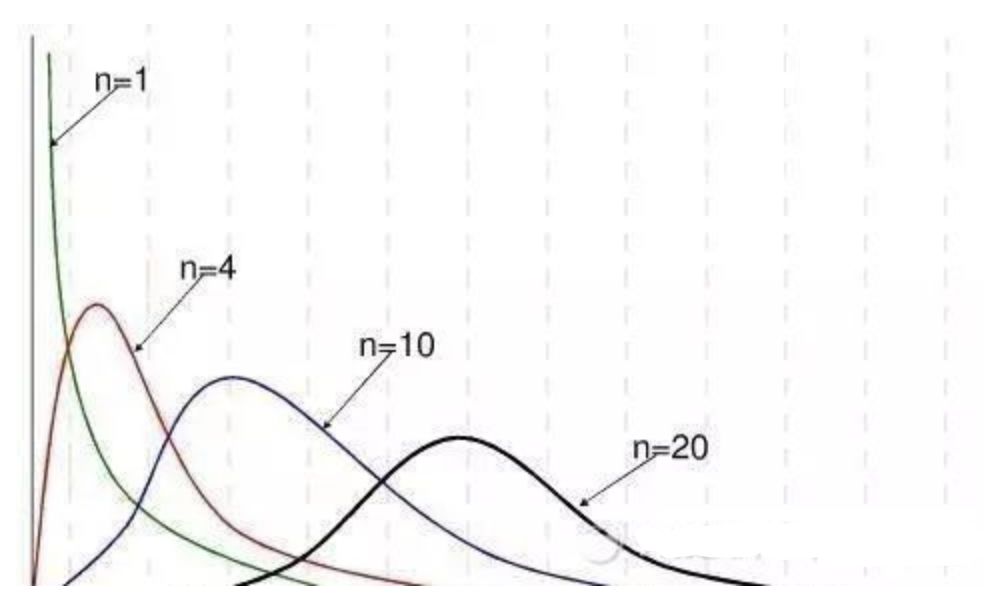
用途1:用于检验拟合优度。也就是检验一组给定的数据与指定分布的吻合程度; 用途2:检验两个变量的独立性。通过卡方分布可以检查变量之间是否存在某种关联:

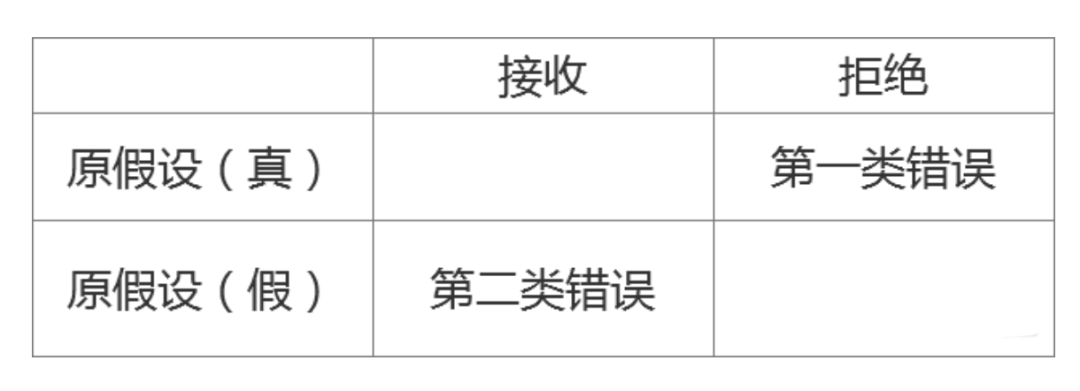
第一类错误: 拒绝了一个正确的假设,错杀了一个好人 第二类错误:接收了一个错误的假设,放过了一个坏人
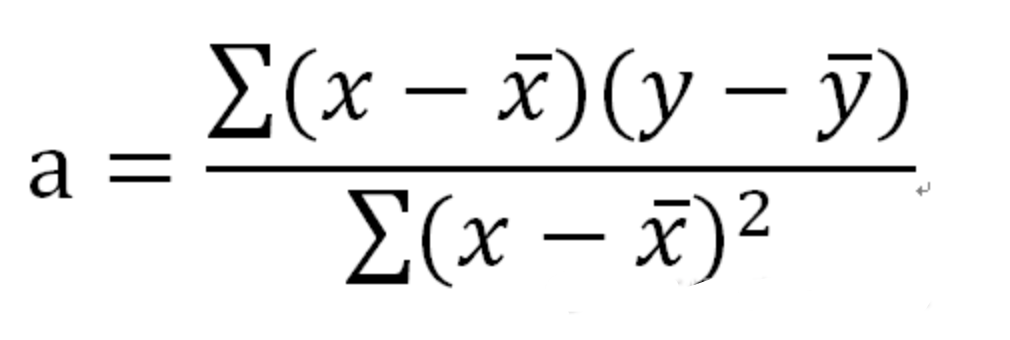
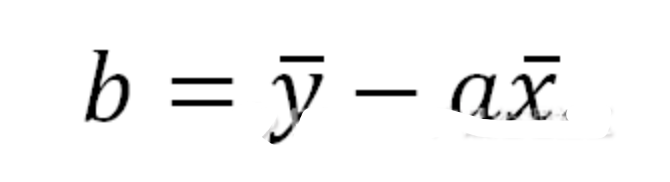
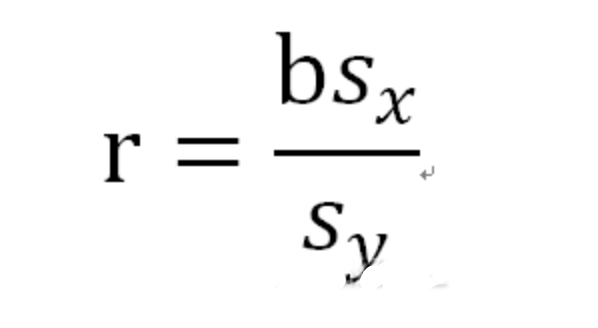
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论